
1. broadcast 함수 정리
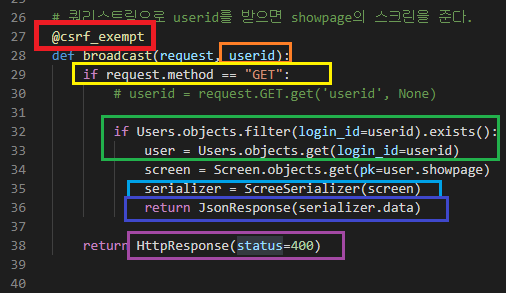
1. @csrf_exempt
프론트와 백이 연결시 csrf오류가 난다.
라이브러리를 다운받고
FBV라면 위와같이 메소드앞에 저걸@csrf_exempt 쓰고
(Java에선 어노테이션인데 여기선 다른 이름인데 기억이 안난다 추후 수정)
CBV라면 아래와 같이 해당 메소드를 추가하는 방식

FBV? CBV?
여기서 소개될 내용은 아니지만 간단히 설명해보자면
FBV: Function Base View로 개발자가 원하는 view를 작성할 때 좀더 커스터마이징한 구문으로 작성할 때 이용된다.
CBV: Class Base View는 drf측에서 자주 사용될 것 같은 view템플릿들을 만들어서 제공하는 class들로,
사용하는 곳과 문법만 익숙하다면 쓰는 것이 좋을 듯 하다
나는 코드를 빨리 만들어야 하기도 했고,
(변명)조금 더 파이썬 문법에 익숙해지기 위해대부분의 코드를 FBV로 만들었으나 나중에 시간이 되면 가능한 CBV문법을 익혀 리팩토링 하고 싶다.
2. path variable 형태로 사용자(브라우저)로 부터 파라미터 받기
먼저urls.py 에서 아래와 같이 path를 수정해야한다.
path('broadcast/<str:userid>/', views.broadcast), # get: screen pk후에 view에서 동일한 이름으로 파라미터를 받아 사용할 수 있다.
사이트에서 URL에 추가적인 정보를 넣고 싶을 때 2가지 방법이있다.
1. QueryString
/users?id=123 # Fetch a user who has id of 123와 같이
?뒤에key=value형태로 데이터를 넘겨주는 형태2. Path Variable
/users/123 # Fetch a user who has id 123와 같이
/뒤에 값만 명시하는 형태일반적으로 우리가 어떤 자원(데이터)의 위치를 특정해서 보여줘야 할 경우 Path variable을 쓰고,
정렬하거나 필터해서 보여줘야 할 경우에 Query string(MDN에선 그냥 parameter라고 적었다.MDN)를 쓴다.
라고 한다.
3. request.method
GET, POST, PUT, DELETE로 구분할 수 있다.
사용하지 않는 method들에 대해선 별도의 return을 표시하는 것이 좋다고 한다.
4. filter(), get()
filter와 get의 차이점은 더 많겠지만, 명확히 아는점만 서술해보면
filter, get모두 sql에서 where절에 해당하는 부분이다.
filter는 원하는 객체가 없어도, 2개 이상이어도 에러를 발생하지 않는다.
get은 반대로 없으면 없다고 에러, 2개 이상이면 2개 이상이어도 에러를 발생한다.
위 같은 특성으로 get은 정말 단 하나의 객체를 얻을 때 오류를 미리 검사하는 목적으로 만들어지지 않았을까 생각한다.
아직 get보단 filter가 편해서 대부분의 로직에 filter만 사용하는데, 나중에 리팩토링할 때 get으로 바꿔줄 부분이 있다면 바꿔줘야겠다.
5. serializer
model을 통해 가져온 객체를 json형태로 return하기 위해서 직렬화해야한다.
깊숙한 뜻은 다를 수 있으나 간단히 model객체를 json형태로 front에 보내기 위해선 반드시 serializer 한다 라고 생각한다.
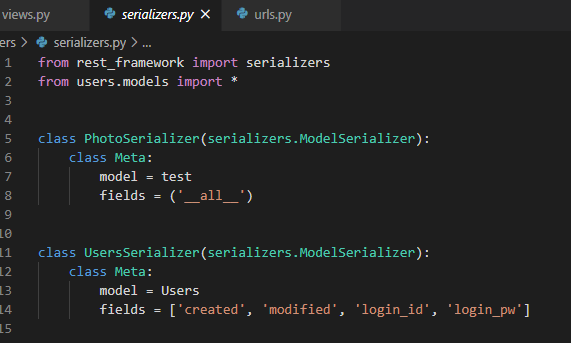
serializer는 별도의 파일을 만들어 model마다 해당하는 클래스를 만들어 줘야 한다.
공홈 사이트에서 나와 있는 코드를 변경하지 않고 그대로 사용했다.
- It will automatically generate a set of fields for you, based on the model.
--> model에 있는 field대로 생성 - It will automatically generate validators for the serializer, such as unique_together validators.
--> 잘은 모르겠으나 unique_together validators같은 것을 자동으로 생성하는듯 함 - It includes simple default implementations of .create() and .update().
--> create, update메소드 자동 생성
아직까지 더이상의 설정이 필요한 사건을 발생하지 않았다.
6. JsonResponse, HttpResponse, Response
# 임포트 부분
from django.http import HttpResponse, JsonResponse
from rest_framework.response import Response내가 공부하면서 썻던 response형태는 3개로
-
JsonResponse
json형태의 response가 가능하다. -
HttpResponse
별다른 리턴 없이 상태코드를 리턴할 수 있다. -
Response
json과 상태코드 둘다를 한번에 보낼 수 있다.
지금보니 Response로만 하면 될 것 같다.
2. screendataall 정리
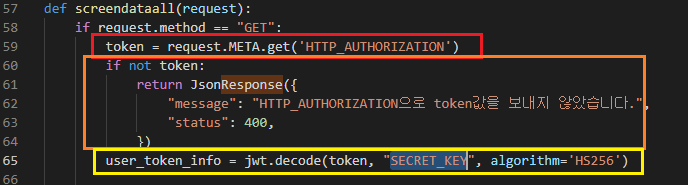
1. request header에서 값 가져오기
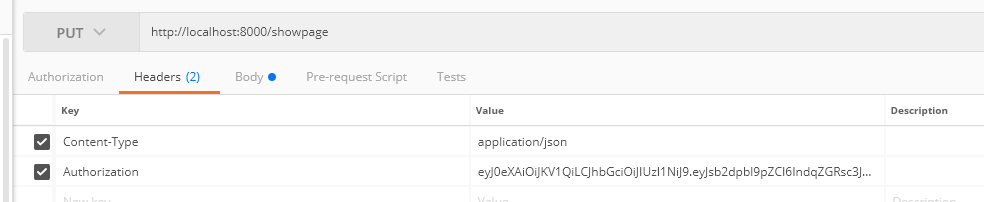
위와 같이 request header에서 Authorization이란 이름으로 어떤 값을 가져오고 싶다면
request.META.get('HTTP_가져올이름.upper()')형태로 가져올 수 있다.
2. 토큰이 없다면
없으면 예외처리 해준 구문인데 Response로 했어야 했는데 좀 부끄러운 코드다.
3. 가져온 token해독
jwt토큰을 해독하는 부분이다.
$ pip install PyJWT
import jwtdecode 함수
# class PyJWT(PyJWS):
## ...
def decode(self,
jwt, # type: str
key='', # type: str
verify=True, # type: bool
algorithms=None, # type: List[str]
options=None, # type: Dict
**kwargs):
if verify and not algorithms:
warnings.warn(
'It is strongly recommended that you pass in a ' +
'value for the "algorithms" argument when calling decode(). ' +
'This argument will be mandatory in a future version.',
DeprecationWarning
)
payload, _, _, _ = self._load(jwt)
if options is None:
options = {'verify_signature': verify}
else:
options.setdefault('verify_signature', verify)
decoded = super(PyJWT, self).decode(
jwt, key=key, algorithms=algorithms, options=options, **kwargs
)
## ...
마지막 부분을 보면 대략
첫 번째 파라미터로 jwt,
두 번째 파라미터로 key(비밀키),
세 번째 파라미터로 복호화 알고리즘을 요구하는 것으로 보인다.
당연히 비밀키를 저렇게 스트링 형태로 직접 넣으면 안된다.
다른 파일로 보관하고 파일을 임포트해 변수 형태로 넣어야 한다.
그리고 해당 비밀키 파일은 당연히 .gitignore처리가 되어 있어야한다.
비밀키는 파일로 보관해야하고, 알고리즘은 hs256말고 더 길고 어렵게 해주는 것을 써야 할 것 같다.
JWT
- 전자 서명, URL-safe (URL로 이용할 수있는 문자 만 구성된)
- 서버와 클라이언트 간 정보를 주고 받을 때 Http 리퀘스트 헤더에 JSON 토큰을 넣은 후 서버는 별도의 인증 과정없이 헤더에 포함되어 있는 JWT 정보를 통해 인증
- JWT는 세 파트로 나누어지며, 순서대로 헤더 (Header), 페이로드 (Payload), 서명 (Sinature)로 구성합니다.
- Header는 토큰의 타입과 해시 암호화 알고리즘으로 구성
- Payload는 토큰에 담을 클레임(claim) 정보를 포함하고 있습니다. Payload 에 담는 정보의 한 ‘조각’ 을 클레임이라고 부르고, 이는 name / value 의 한 쌍으로 이뤄져있습니다. 토큰에는 여러개의 클레임 들을 넣을 수 있습니다.
클레임의 정보는 등록된 (registered) 클레임, 공개 (public) 클레임, 비공개 (private) 클레임으로 세 종류가 있습니다.실제 사용시
exp: 만료시간 설정정도만 세팅했던 것 같은데 더 공부가 필요해 보입니다.
- Signature는 secret key를 포함하여 암호화되어 있습니다.

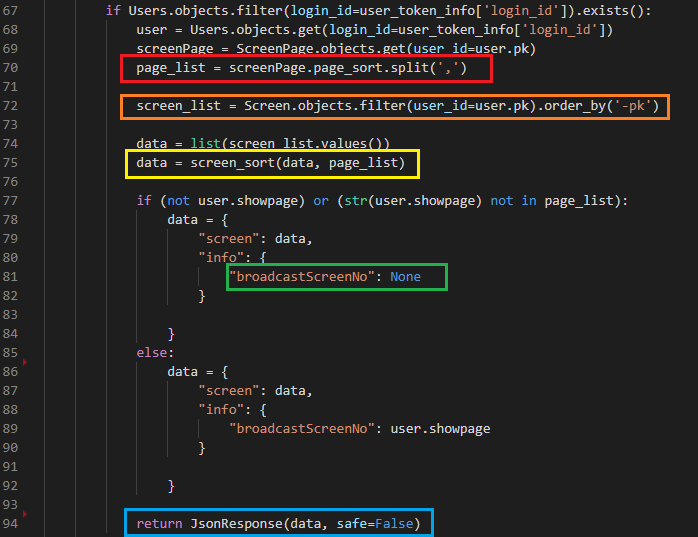
4. split(',') 메소드
가져온 데이터를 ,기준으로 잘라 list에 담는다.
5. .order_by('-pk')
QuerySet를 정렬할 수 있는 메소드로 원하는 속성값 기준으로 정렬해 준다.
.order_by('pk'): 정방향 정렬
.order_by('-pk'): 역 방향 정렬
자세한 공홈 사이트
특이하게 랜덤으로 정렬할 수 도 있다고 한다..

6. None
아마 front가 받기에 null값으로 리턴하기 위한 방법이었지 않나 싶다.
7. JsonResponse(, safe=False)
from django.http import HttpResponse, JsonResponseJsonResponse는 임포트부분에서 봤다시피 DRF(Django REST Framework)에서 지원하는 라이브러리가 아니다.
따라서 리턴하는 부분이 dict형태가 아니라면 무조건 safe=False를 붙여줘야한다.
3. showpage
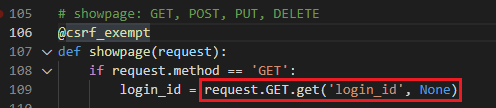
1. request.GET.get('login_id', None)
Query String 방식으로 데이터를 넘겨줄 때 받는 방법이다.
/users?id=123 # Fetch a user who has id of 123 데이터가 없다면 None을 넣도록 하는 형태이다.
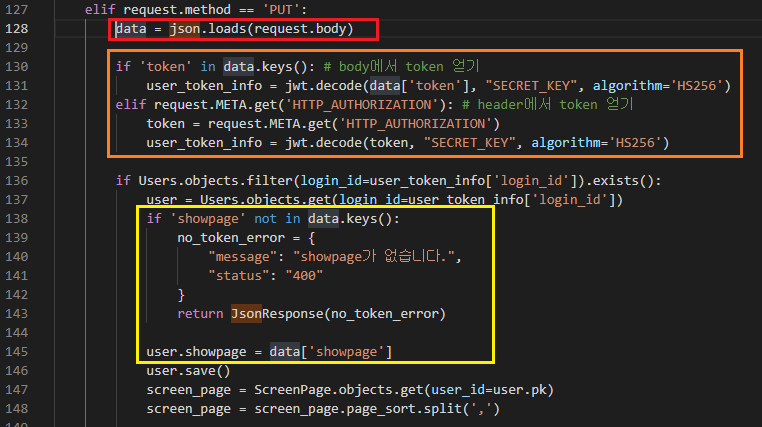
2. data = json.loads(request.body)
request body에 담긴 데이터를 꺼내는 방법이다.
3. if 'token' in data.keys():
body에서 원하는 데이터가 없는 경우 검사하기 위한 예외 조건이다.
keys를 통해 검사하지 않고 바로 value를 조회하려하면 에러가 발생하기 때문에 이렇게 했다.
data는 dict형태이기 때문에 data['showpage']와 같은 형태로 접근한다.
4. screen_page.save(update_fields=['page_sort])
현재 우리가 DB를 조작하는 방법은 ORM방식이라고 한다.
ORM
자세한 소개는 구글에 검색하여 보고 아주 간단하게 설명하자면
기존에 프로그램이 DB를 조작하기 위해서 SQL(Structured Query Language)이라는 DB전용(?) 문법을 썼어야 했다.
이 문법은 일반 프로그래밍 언어와 문법적으로 큰 괴리가 있었다.# 간단한 예문 SELECT name, population FROM city WHERE countrycode = "KOR" AND population >= 1000000 ORDER BY population DESC; SELECT language, COUNT(countrycode) as "count"; FROM countrylanguage GROUP BY language ORDER BY count DESC LIMIT 4, 6;이것을 좀 더 프로그래밍 언어와 익숙하게 바꾼 문법이 ORM문법이다.
그래서 코드들을 더 코드스럽게(?) 쓸 수 있고, 중간다리 역할을 하기 때문에 DB에 덜 종속적이게 된다는 대단한 이점을 얻을 수 있다.MySQL, Oracle, MS SQL들은 각자 문법이 조금씩 다르다.
하지만 ORM을 쓰는 순가 그런 차이는 ORM이 맡아서 변환해준다.
(CODE -> ORM -> DB)그래서 우리는 ORM이라는 새로운 문법을 익혀야 하지만, 얻는 이점이 크다는 이유로 사용하는 것을 권장한다.
ex_
Spring: spring-data-jpa
node.js: Sequelizer
django: QuerySet
코드로 돌아와 현재 save()메소드를 호출하는것을 볼 수 있는데 이는
새로운 값들을 넣고 save를 호출하면 create
기존속성을 변경하고 save를 호출하면 update
가 되는 엄청난 메소드다.
여기선 update를 하기 위해 update_fields속성에 변경할 속성을 넣어주어 실행했다.
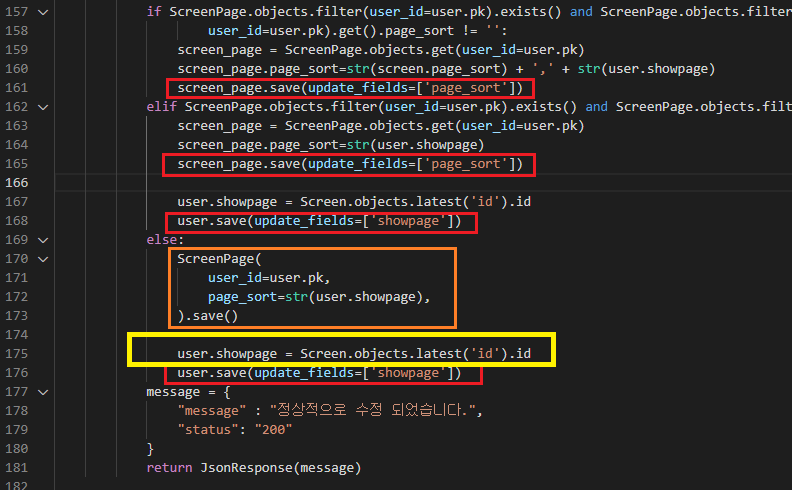
저기서 보이는 빨간, 주황, 노랑 코드들 모두 ORM에 해당되며
각각
1) update:
screen_page.save(update_fields=['page_sort'])
screen.save(update_fields=['body', 'alias', 'modified'])2) create:
ScreenPage( ... ).save()
ScreenPage(
user_id=user,
pk=screen_page.id,
page_sort=new_screen_sequence
).save()3) 마지막에 생성한 객체 접근:
user.showpage = Screen.objects.latest('id').id을 맡고 있다.
더 자세한 부분은 나중에 기회가 되면 정리해보겠습니다.
5. http status code

매우 많지만 어느정도 규칙이 있으며, 자주 사용되는 것 위주로 익히면 된다.
200~(Good)
대충 성공적이라는 의미이며 보이면 기분이 좋아진다.
- 200 OK: 요청이 성공적!
- 201 Created: 요청이 성공적이었으며 그 결과로 새로운 리소스가 생성
300~(retry?)
보통 어떤 이유로 다시 요청해야한다 이다.
대표적으로 redirect를 할 때 이런 코드를 사용한다.
- 300 Multiple Choice: 요청에 대해서 하나 이상의 응답이 가능합니다. 응답 중 하나를 선택하는 방법에 대한 표준화 된 방법은 존재하지 않습니다
- 301 Moved Permanently: 이 응답 코드는 요청한 리소스의 URI가 변경되었음을 의미합니다. 새로운 URI가 응답에서 아마도 주어질 수 있습니다.
400~(Bad Request)
보통 client(Browser)쪽에서 잘못된 값을 보냈을 확률이 높다.
- 400 Bad Request: 이 응답은 잘못된 문법으로 인하여 서버가 요청을 이해할 수 없음을 의미합니다.
- 403 Forbidden: 클라이언트는 콘텐츠에 접근할 권리를 가지고 있지 않습니다.
- 404 Not Found: 서버는 요청받은 리소스를 찾을 수 없습니다.
500~(Bad Response)
보통 서버쪽에서 잘못처리했을 확률이 높습니다.
- 500 Internal Server Error: 서버가 처리 방법을 모르는 상황이 발생했습니다. 서버는 아직 처리 방법을 알 수 없습니다.
- 502 Bad Gateway: 이 오류 응답은 서버가 요청을 처리하는 데 필요한 응답을 얻기 위해 게이트웨이로 작업하는 동안 잘못된 응답을 수신했음을 의미합니다.
