AI/ML/SVM(Support Vector Machine)
Support Vector Machine
Gradient Boosting(의사결정나무 기반 모델)과 같이 가장 강력한 머신러닝 모델 중 하나이다. 회귀, 분류 둘다 가능하다.
개념(분류 모델)
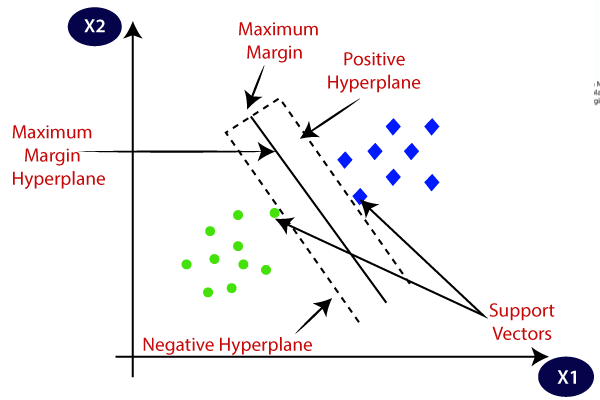
클래스 간 margin을 최대화하는 결정경계 Decision Boundary를 찾는 것이 핵심이다. 경계에서 가까운 데이터를 Support vector라고 한다.
positive plane과 negative plane 사이의 최소거리를 margin이라고 한다.
positive plane, negative plane은 각각 support vector를 지난다
Soft Margin SVM, Hard Margin SVM
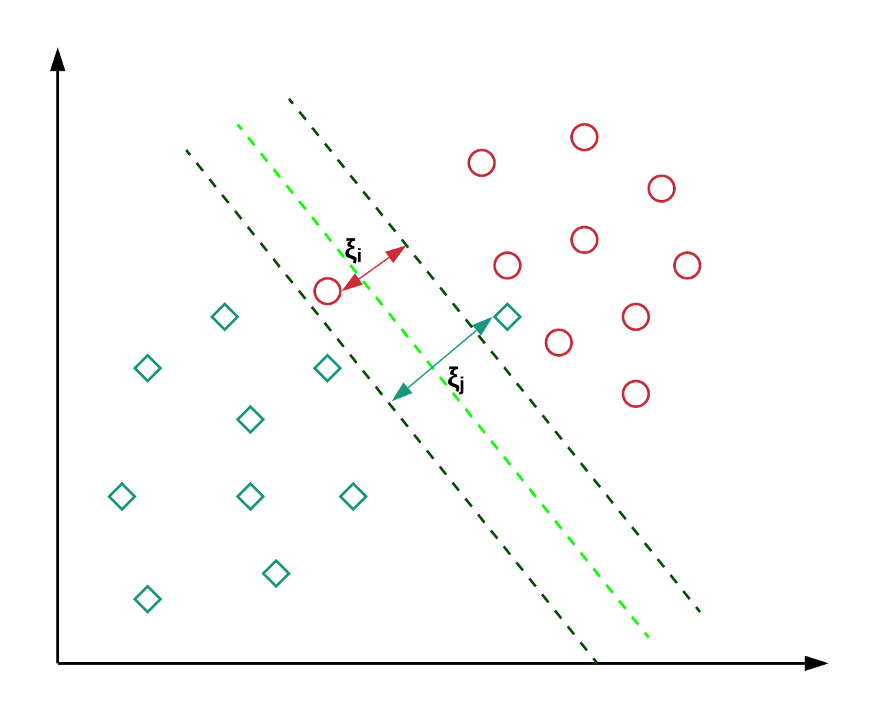
경계를 넘는 데이터가 있으면 어떻게 Decision Boundary를 만들까? 기존 SVM의 목적함수에 약간의 오차를 허용하면 된다. 이를 Soft Margin SVM이라고 한다.(이전은 Hard Margin)
https://yngie-c.github.io/machine%20learning/2021/03/13/soft_margin_svm/
요기 c-svm의 목적 함수를 참고하면, w는 마진, xi는 일탈한 데이터와 p-plane, n-plane중 먼 것 과의 거리를 나타낸다. C는 가중치(Hyper-Parameter)다. 2/w인 margin과 달리 w^^2를 쓰는 이유는 미분하기 편해서 라고..
이를 통해 모델의 Robustness가 올라간다. 이상치의 영향을 덜 받는다는 뜻이다.
Kernel SVM
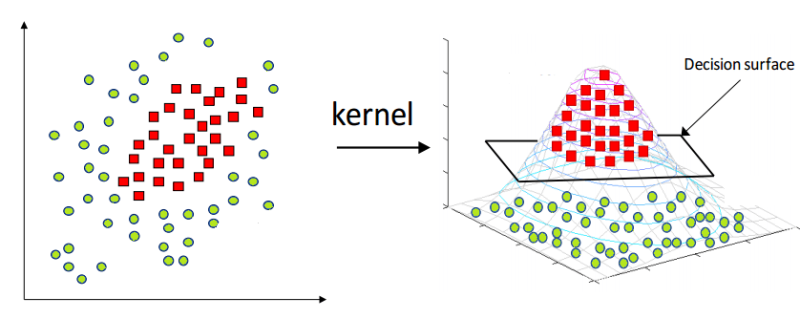
위와 같이 선형 분리 불가능(Linearly-Unseparable)한 데이터의 경계를 찾아내기 위해 Kernel SVM이 등장한다. 한 축에있는 데이터를 조작하여 새로운 z축을 만들어내고 입체화해서 결정 경계를 만든 후 다시 2차원으로 돌아오는 방식이다. 그러면 타원형 결정 경계가 생긴다.
여기서 기존 데이터를 고차원으로 옮길 때 사용되는 함수를 커널 함수라고 한다. 이 커널 함수는 사람 마음대로 결정하는 것(Hyper-Parameter)이다. 물론 다항 커널, 가우시안 커널 등 이미 잘 만들어진 커널들이 많다. (https://sanghyu.tistory.com/14)
기존 데이터를 조작해 새롭게 데이터를 만들어낸다는 점에서 딥러닝의 layer개념과 비슷하다. 근데 딥러닝에선 컴퓨터가 알아서 계산하지만 여기선 사람이 커널을 정해야 한다. 그래서 layer를 Learnable Kernel이라고도 한다. (https://developers.google.com/machine-learning/crash-course/feature-crosses/video-lecture)
실습
from sklearn.svm import SVC
clf = SVC(C=10, kernel='rbf, gamma=0.1)
clf.fit(x, y)
보통 SVC, SVR을 많이 사용한다. LinearSVC같은 것도 있음.
Hyper-Parameter
- C: 목적함수에서 xi의 총합에 곱하는 계수. 클 수록 아웃라이어들에 민감해짐(오버피팅).
- kernel: 커널함수를 정할 수 있다. 'linear', 'poly', 'rbf' 등등 있는데 가우시안 커널 (Radial Basis Function)을 많이 사용한다고함
- gamma: 가우시안 커널에서 1/r. 커질수록 좀더 구체적이고 작은 타원모양이 나오고 작을 수록 둔하고 큰 타원모양이 나온다. (2차원에서)
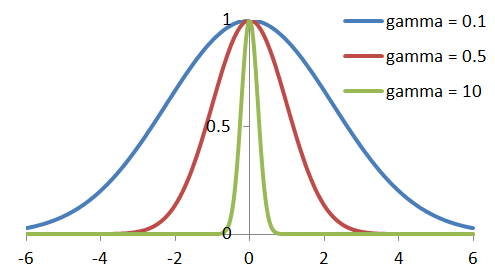
C와 gamma모두 커질수록 오버피팅되는 경향이 있다.
SVM은 X데이터들 간 스케일이 차이가 많이나면 성능이 잘 안나온다
예를 들면 어떤 열은 10~100사이인데 어떤 열은 0.0001~0.01인 경우
Feature Scaling
min-max normalization
(x-min)/(max-min) 이렇게 0~1 사이에서 값을 조정한다.
SVM뿐만 아니라 다른 모델에도 성능을 올려준다.
Tree기반 모델들은 그닥 필요하지 않다. 해도 상관은 없다.
sc = sklearn.preprocessing.MinMax~~~()
sc.fit(x_train)standardization
평균이 0, 표준편차가 1이 되도록 표준화하는 것이다. (정규분포)
sc = sklearn.preprocessing.StandardScaler()
sc.fit(x_train)
x_train_scaled = sc.transform(x_train)
x_test_scaled = sc.transform(x_test)
...
model.fit(x_test_scaled)
스케일링 과정에서 test data가 개입하면 안된다.(평균, 최대, 최소, 표준편차 등) 쪼개고 Train data에만 하면 된다.
HPO
HPO(Hyper-Parameter-Optimization)
- Grid-SearchCV 직관적이고 성능도 좋음
- Randomized-Search 딥러닝에서 Grid-Search보다 성능이 잘나오는 경우가 있음.
- Bayesian-Search 난이도가 높음. 딥러닝에서 RandomizedSearch보다 잘 사용됨. AutoML 등에서 사용됨.
보통 각 조합을 비교할 때도 Cross Validation을 사용하는데 이때 훈련 데이터를 또 쪼개서 검증하기 때문에 수동으로 각 조합을 비교한 것과 점수가 다르게 나올 수 있다. 그럴 땐 수동으로 비교해서 잘 나온 조합을 사용하면 된다.
GridSearchCV
HPO를 하기 위해 사용하는 모듈이다. (=HP Tuning, Model Tuning)
Hyper-Parameter의 후보군을 주면 알아서 조합해서 보여준다.
CV는 Cross Validation의 줄임말이다.
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.metrics import classification_report
param_grid = {'C':[1, 2, 3, 4, 5],
'gamma':[0.1, 0.5, 1, 2, 100],
'kernel':['rbf']
}
grid = GridSearchCV(SVC(), param_grid, refit=True, verbose=1)
# refit: 최적조합을 바로 적용할지 여부
# verbose: print되는 설명의 정도
grid.fit(x_train_scaled, y_train)
y_pred = grid.predict(x_test_scaled)
print(classification_report(y_test, y_pred)) GridSearchCV()에 모델이 들어갈 때 따로 argument를 주면 안되는데, param_grid에 추가해주는 식으로 대신할 수 있다.
grid.best_params_로 최적해를 Dictionary로 꺼낼 수 있다.
RandomizedSearchCV
Hyper-Parameter의 범위를 주면 조합해서 보여준다.
BayesianSearchCV
베이즈 통계학을 기반으로한 기법 (vs 빈도주의 통계학)
