DDL (Data Definition Language)
- CREATE
- ALTER
- DROP
데이터를 정의하는 역할이다. db의 틀을 만들 때 사용하는 것들이다.
CREATE
테이블을 만들 때 사용
CREATE TABLE A (
A_id INTEGER PRIMARY KEY,
name TEXT NOT NULL, # NULL이 아님
password TEXT UNIQUE DEFAULT '1234', # 중복되지 않아야 함, 기본값 있음.
phone TEXT NOT NULL UNIQUE CHECK (LENGTH(phone) >= 10), # 길이가 10 이상이어야함
);여러 키워드들이 있다. PRIMARY KEY의 경우 아래와 같이 따로 지정해줘도 된다.
UNIQUE 제약조건의 경우 NULL의 중복을 다루지 않는다. 모든 NULL이 고유하다.
id INTEGER
phone TEXT NOT NULL ...
PRIMARY KEY(id)데이터 테이블 pandas의 dataframe으로 불러오기
pd.read_sql_query("SELECT * FROM A", conn)
외부 테이블 값 참조하기
CREATE TABLE B (
id INTEGER PRIMARY KEY,
A_id INTEGER,
FOREIGN KEY (A_id)
REFERENCES A(A_id) # A 테이블의 A_id를 참조한다.
ON DELETE CASCADE, # A 테이블에서 데이터가 삭제되면 B에서도 자동으로 삭제한다.
)ON UPDATE, ON CREATE / SET NULL, SET DEFAULT 등등 많다. 참고
ALTER
기존 테이블을 바꿀 때 사용한다.
CREATE TABLE devices (
name TEXT NOT NULL
model TEXT NOT NULL
serial INTEGER NOT NULL UNIQUE
);테이블의 이름 변경
ALTER TABLE devices RENAME TO phones;열 추가
ALTER TABLE phones ADD COLUMN factory TEXT NOT NULL;열 이름 변경
ALTER TABLE phones RENAME COLUMN factory TO country;DROP
삭제하는 역할이다.
DROP TABLE IF EXISTS phone; # 존재하면 삭제하기SQLite 덤프
DB 내 테이블의 목록, 테이블의 구조 등을 불러온다.
script = """
SELECT name FROM sqlite_master
WHERE
type = 'table' AND
name NOT LIKE 'sqlite_%'
"""
df = pd.read_sql_query(script, conn)sqlite_master에서 전부를 뽑아내면 가장 많은 정보를 뽑을 수 있다.
DML (Data Manipulation language)
테이블 내 데이터를 조작할 때 사용함
CRUD
SELECT(READ) / INSERT(CREATE) / UPDATE(UPDATE) / DELETE(DELETE)
SELECT(FROM)
SELECT column0, column1, ... FROM tablename;
파이썬의 경우 cur.execute()하고 cur.fetchall()을 하면 데이터를 뽑아낼 수 있다. 혹은
pd.read_sql_query("SELECT ~~~", conn) 이렇게 데이터프레임으로 바로 뽑을 수도 있다.
column 옆에 AS 어쩌구를 붙여준다면 column의 이름을 어쩌구로 바꿔준다.
INSERT(INTO)
INSERT INTO tablename (column0, column1, ...) VALUES ('value0', 'value1', ...);
여러 개를 한번에 넣을 수도 있다.
INSERT INTO tablename (column0, column1, ...) VALUES ('value0', 'value1', ...), ('value5', 'value6', ...);
UPDATE(SET)
이미 존재하는 데이터를 수정할 때 사용한다.
UPDATE tablename SET email = '' WHERE id = 4;tablename 테이블에 email열을 ''로 수정한다. 어느 데이터? id가 4인 데이터.
WHERE 키워드를 사용하지 않으면 전부 ''로 수정된다.
SET 뒤에 여러 열을 추가해 수정할 수 있다.
UPDATE tablename SET email = '', phone = '' WHERE id = 4;문자열 가공
UPDATE ~~
SET fullname = UPPER(firstname || "," || lastname);이런식으로 ||혹은 CONCAT()을 통해 문자열을 합쳐주고, UPPER()함수를 통해 대문자로 변환도 가능하다.
LENGTH()와 같이 길이를 반환해주는 함수도 있다. 더보기
DELETE(FROM)
주의: DROP은 테이블 및 열을 떨구는 역할이다. 데이터를 삭제하는 것은 DELETE다.
DELETE FROM tablename WHERE id=33;ORDER BY
정렬하기
SELECT * FROM table ORDER BY columnname;기본은 오름차순이다. 맨 뒤에 ASC가 오거나 기본은 오름차순, DESC이 오면 내림차순이다.
여러 기준으로 정렬하기
구분해서 넣어준다.
SELECT * FROM table ORDER BY column0 ASC, column1 DESC;NULL,NONE은 정렬 시 가장 작은 값으로 간주한다.
DISTINCT
데이터 종류 확인(중복제거)
특정 열에서 데이터의 종류가 얼마나 많은지 찾아보자.
(df로 뽑아낸 상황)
set(df['column'])데이터 값을 중복 없이 리턴해준다.
데이터 종류별 수 확인
df['coloumn'].value_counts데이터 값 별 빈도를 리턴해준다.
SQL문으로 중복 데이터 제거
SELECT DISTINCT column FROM table;이러면 위 데이터 종류 확인(중복제거) 같은 결과가 나온다.
DISTINCT 여러개
SELECT DISTINCT column0 column1 FROM table;column0와 column1이 둘다 중복되는 경우에만 지운다.
중요
-
SELECT시DISTINCT한 열과 그냥 보통 열을 같이 고를 수 없다.
그냥DISTINCT를 걸면 선택하면 모든 열에 걸리게 된다. -
NULL의 중복도 허용되지 않는다. DDL에서UNIQUE가 NULL의 중복을 허용해주는 것과는 다르다.
WHERE
데이터를 SELECT할 때 보통 필터링 용도로 쓰인다.
- 대소
SELECT * FROM table WHERE column1 > 100;
SELECT * FROM table WHERE number <> 10;- 범위
양 끝은 포함된다.
SELECT * FROM table WHERE column1 BETWEEN 1 AND 30;- 집합
SELECT * FROM table WHERE column1 IN (1,2,3);- 패턴
SELECT * FROM table WHERE name LIKE '%John%';- NULL
SELECT * FROM table WHERE name IS NULL;등등
와일드카드 문자
- %
아무 문자열. '%picture'는 끝에 picture가 오기만하면 된다. '%pic%'은 아무 곳이나 pic이 들어가면 된다. - _
글자 하나 - []
범위 내 문자열 한개. '[1-3]'은 1-3사이 문자 하나를 뜻하고, '[a-f]'는 a-f사이 하나를 뜻함. - [^]
위의 여집합. [^1-3]은 1-3사이 문자열이 아닌 문자열 하나를 뜻함. - '+'
말 그대로 문자열 더하기
subquery
필터링을 위해 다른 테이블의 정보가 필요하다면?
예를 들어,
table "영수증" 에 고객이름(cust_name), 고객이 구매한 상품품번(item_num)이 있고
table "상품" 에 상품품번(item_num)과 상품 이름(item_name)이 있는 상황에서
스마트폰을 산 고객의 명단이 궁금하다면?
SELECT cust_name
FROM 영수증
WHERE item_num IN (
SELECT item_num
FROM 물건
WHERE item_name = '스마트폰'
)LIMIT
LIMIT 키워드를 사용하면 위 혹은 아래서부터 N개의 행만 보여준다.
SELECT * FROM table LIMIT 4;위와 같은 코드는 위에서 4개까지 보여준다.
OFFSET을 뒤에 붙여주면 데이터를 몇개 덜어내고 그 다음부터 4개를 보여준다.
SELECT * FROM table LIMIT 4 OFFSET 4;ORDER BY를 사용해 정렬 후 사용하면 "A등 ~ B등 추출하기" 같은 것들이 된다.
JOIN
테이블을 합병한다. 네가지 종류가 있다.
- INNER JOIN (교집합)
- LEFT JOIN, RIGHT JOIN
- OUTER JOIN (합집합)
JOIN을 FROM 뒤에 줄줄이 붙여서 여러 테이블을 합병할 수 있다.
INNER JOIN
두 테이블의 교집합만 살아남는다.
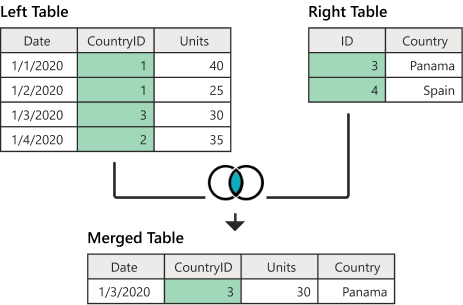
SQL문은 다음과 비스무리하겠다.
SELECT Date, CountryID, Units, Country
FROM Lefttable
INNER JOIN Righttable ON CountryID = ID-
SELECT문은lefttable에서 column들을 고르는게 아니라 두 테이블을 합병한 테이블에서 column들을 고른다 -
두 테이블의 column명이 같다면
테이블명.columnname식으로 적어주면 된다.
매번 테이블명. ~~~ 하기 싫다면 아래와 같이 테이블명에 이름을 더 붙여줄 수 있다.
SELECT l.Date, l.CountryID, l.Units, r.Country
FROM Lefttable l
INNER JOIN Righttable r ON l.CountryID = r.ID- 2번 내용에서,
ON뒤에 비교하는 두 column의 이름이 같다면ON 조건대신USING(columnname)을 사용하는 것이 간결하다.
번외: pandas로 테이블 합병하기
pd.merge(df_a, df_b, left_on='CountryID', right_on='ID', how='inner'
위의 예시와 같다.
LEFT JOIN
왼쪽 테이블만 유지된다.
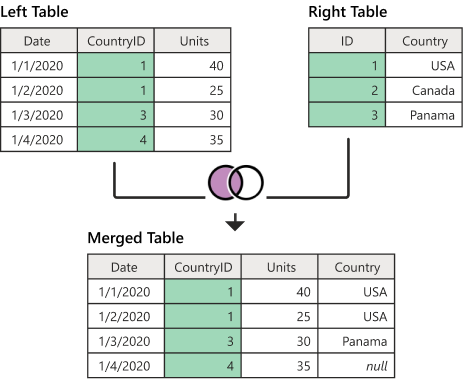
위의 INNER JOIN은 조건에 맞지않는 양 테이블의 데이터를 모두 버렸지만
LEFT JOIN 은 왼쪽 테이블을 유지하면서 조건에 맞는 오른쪽 테이블의 데이터를 불러오는 느낌이다.
SQL문은 INNER JOIN과 다를게 없다.
RIGHT JOIN
LEFT JOIN 으로 대체 가능
OUTER JOIN
합집합
번외 : SELF JOIN
테이블 하나를 두개로 보고 합병하는 것이다. 사실 한 테이블이지만 두 테이블로 생각하고 코드를 짜면 된다.
테이블 뒤 별명을 만들어서 헷갈리지 않도록 한다.
GROUP BY
pd.pivot_table(df, index='columnname', aggfunc=np.sum)
위의 pd.pivot_table()과 유사하다.
데이터프레임 df에서 index열을 기준으로 같은 것끼리 모아 aggfunc을 실행해준다.
예를 들면 멜론차트에서 같은 가수가 부른 음원끼리 모아서 몇곡이 있는지를 계산하는 것이 있다.
SELECT ArtistName, COUNT(TrackId)
FROM tracks
GROUP BY ArtistName이러면 아티스트 이름, 트랙 수가 있는 테이블이 나온다.
맨 윗줄에 COUNT()라는 함수가 있다. pd.pivot_table()로 치면 aggfunc과 같은 역할이다. 쓸 수 있는 함수는
SUM(), AVG(), COUNT(), MIN(), MAX() 등이 있다.
HAVING
GROUP BY에서 필터링이 필요할 때 사용한다. HAVING 뒤에 조건을 붙여주면 된다.
WHERE과의 차이?
WHERE가 GROUP BY, HAVING보다 먼저 적용된다.
일반적으로는 WHERE을 먼저 써주는게 빠르다. 그런데 HAVING을 써야만 하는 경우도 있다.
SELECT ArtistName, COUNT(TrackId)
FROM tracks
GROUP BY ArtistName
HAVING COUNT(TrackId) = 2GROUP BY를 먼저 해야 aggregate 함수인 COUNT를 쓸 수 있으니 WHERE로는 불가능하다.
날짜 다루기
STRFTIME(a, b)이라는 함수가 있는데, 날짜를 다루기 위한 함수이다.
첫번째 인수에는 원하는 출력방식을, 두번째에는 시간 객체를 넣으면 된다.
풀 시간에서 년도만 추출하고 싶다면
STRFTIME('%Y', Date) 이렇게 사용하면 된다.
순서
- SELECT FROM
- JOIN
- WHERE
- GROUP BY, HAVING
- ORDER BY
- LIMIT, OFFSET
