배경
데이터베이스는 조건문으로 검색할 때, 테이블 전체를 full scan으로 탐색한다. 이러한 탐색 방식은 데이터가 많아지면 많아질 수록 비효율적인 방식이라는 것을 알 수 있을 것이다.
이러한 비효율을 해소하기 위해 인덱스 테이블을 활용할 수 있다.
인덱스는 B-Tree 자료구조를 사용해서 구성된다고 한다.B-Tree알고리즘이 궁금하다면 여기를 참고하자.
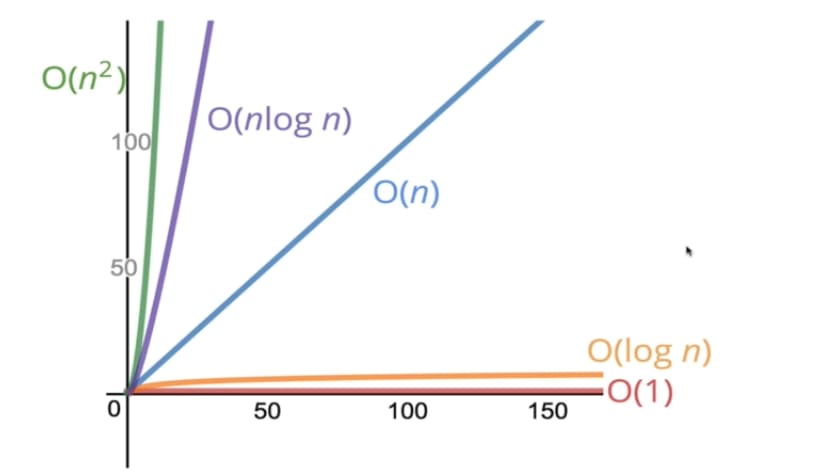
전문을 검색했을 때 O(n)의 시간복잡도가 걸리지만 인덱스 테이블을 사용하면, O(logn)시간만에 탐색을 마칠 수 있어서 탐색 시간이 훨씬 빠르다고 한다. 그래프를 보면 알 수 있지만, 데이터가 많아질 수록 그 격차는 더 크다. (물론 HashMap과 같이 O(1) 시간복잡도 보다는 느리다.)
그렇다면 실제로 인덱스를 사용해보면서 얼마나 효과가 있는지 확인해보자.
참고로 hibernate, mysql 등은 기본적으로 기본키를 활용한 인덱스 테이블을 자동으로 만든다.
조회 속도 비교
실험 코드는 간단하다. 회원 엔티티에 인덱스로 사용할 컬럼명을 작성해준다.
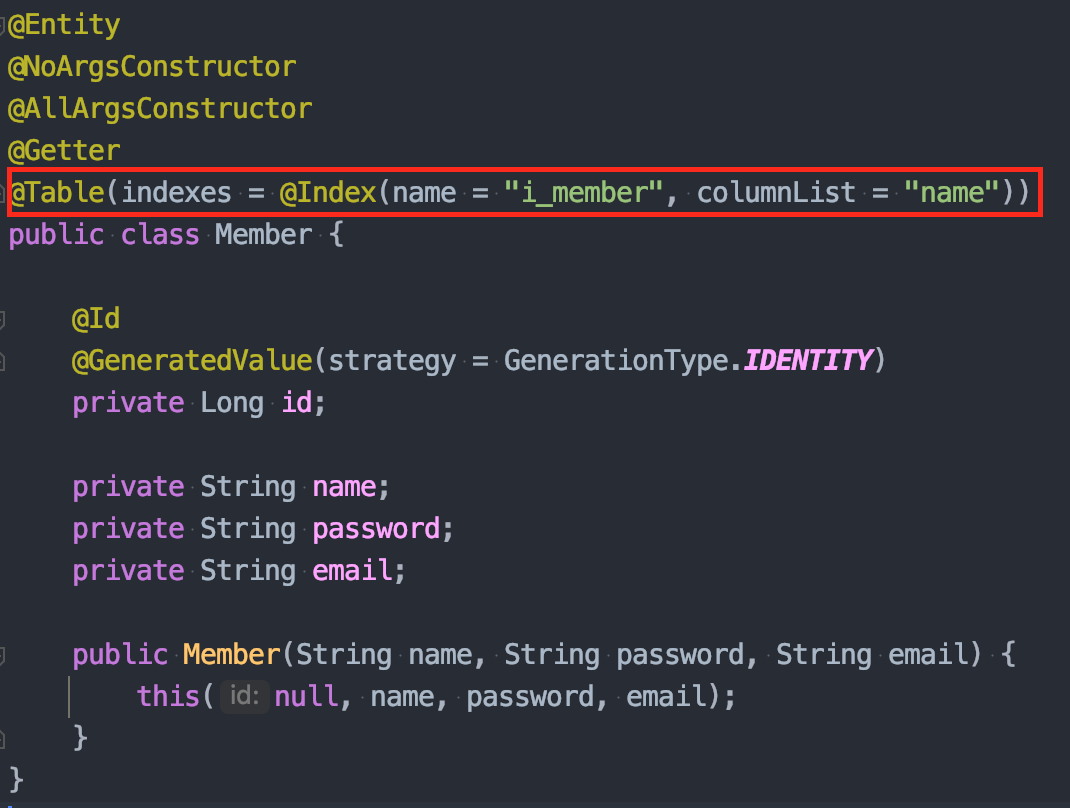
그러면 테이블 생성할 때, name 컬럼으로 인덱스 테이블이 새로 추가된 것을 확인할 수 있다.

그렇다면 이제 인덱스가 얼마나 효과가 있는지 확인해보자.
먼저, 회원수 100명일 때 이름에 대한 인덱스를 사용했을 때와 사용하지 않았을 때, 조회 시 걸린 속도를 비교이다.
회원 수 100명 일 때
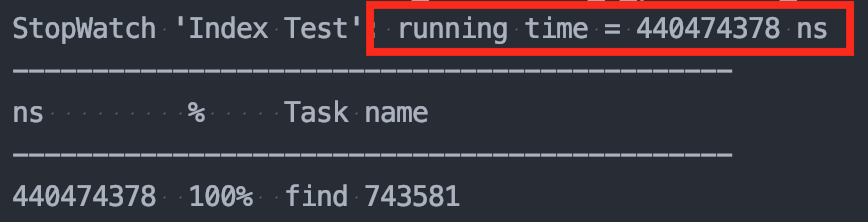
👉 인덱스 미사용 : 0.44s
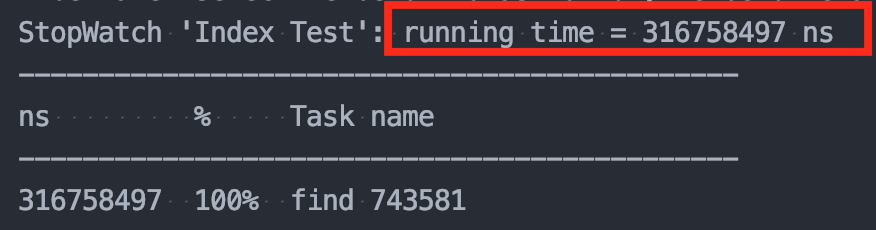
👉인덱스 사용 : 0.31s
데이터가 작을 때는 별차이가 없어보인다. 그럼 데이터를 조금씩 늘려보자.
회원 수 10,000명 일 때
👉 인덱스 미사용 : 1.01s
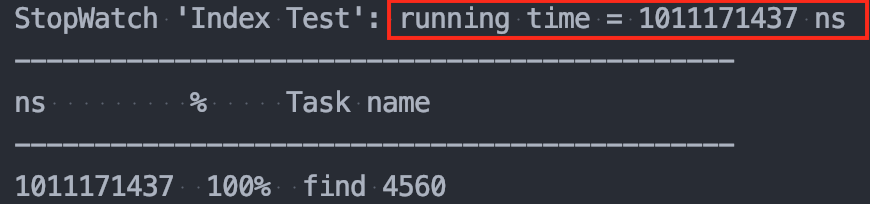
👉 인덱스 사용 : 0.39s

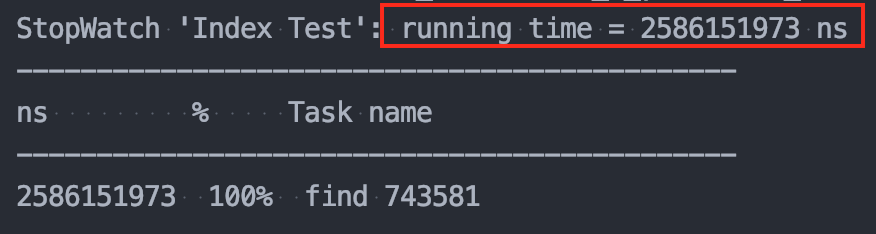
회원 수 100,000명 일 때
👉 인덱스 미사용 : 1.63s
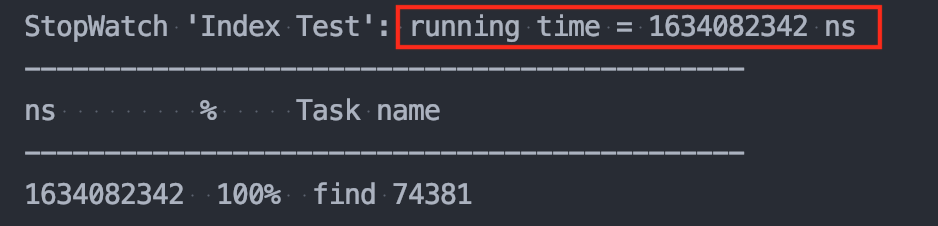
👉 인덱스 사용 : 1.23s
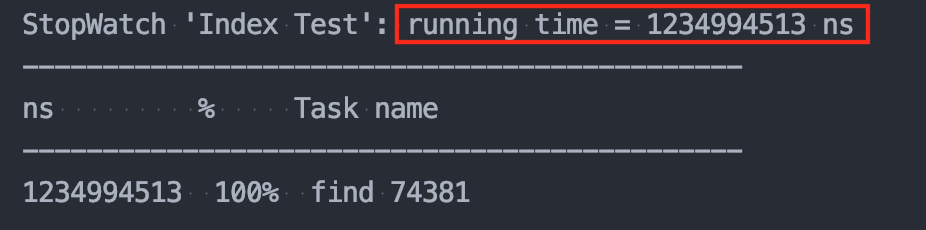
회원 수 500,000명 일 때
👉 인덱스 미사용 : 5.69s
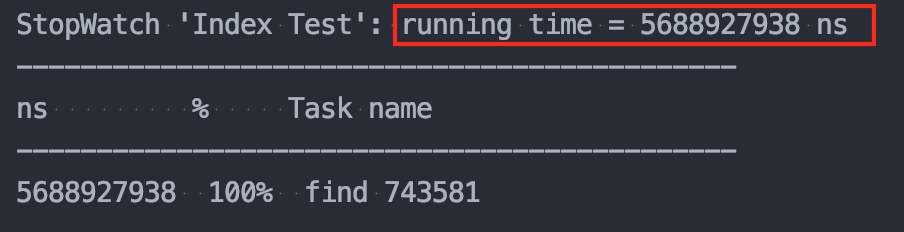
👉 인덱스 사용 : 2.59s
데이터가 점점 늘어날 수록 인덱스를 사용할 때와 사용하지 않았을 때의 차이가 점점 늘어나는 것을 확인할 수 있다. 데이터가 50만개일 때는 차이가 2배도 넘게 나는 것을 확인할 수 있었다.
결론
인덱스를 과도하게 설정하면 그 자체만으로도 메모리 공간을 많이 차지하지만, 본테이블이 변경될 때마다 인덱스의 정렬 순서도 매번 수정이 되어야하므로 이 역시 비효율을 낳는다.
인덱스를 복합으로 쓴다면 갯수는 3~4개가 적당하며 인덱스를 고르 때는 카디널리티가 높은 순서대로 고르는게 좋다. (카디널리티란, 정의상으론 집합을 이루는 원소의 갯수를 의미한다. 즉 카디널리티가 높다는 말은, 10개의 데이터가 있으면 10개 모두 다른 내용를 가질정도로 원소의 갯수가 많다는 것이다.)
B-Tree는 LIKE 검색으로 중간일치, 후방일치 검색을 할 수 없기 때문에 전방탐색(full-text)이 아니라면, 엘라스틱서치나 다른 방식으로 검색의 효율을 높이는게 좋다.
참고자료

안녕하세요 포스팅 잘 보았습니다.
혹시 더미데이터를 추가하여 테스트를 했을까요 아니면 실행계획에 10만 100만건 데이터를 넣을 수 있는 옵션 같은게 있을까요? 쿼리 성능을 측정하려는데 방법이 궁금합니다.!!