문제 사이트 https://ai-korea.kr/playground/selectTutorialPlaygroundTask.do
자연어 처리를 공부하던 중 직접 문제를 풀어보고 싶어서 사이트를 찾다가
인공지능 놀이터라는 사이트를 보게되었고 난이도가 높아 보이지 않아 문제를 풀어 보게 되었습니다
- 문제 확인

train data는 text와 category 형식으로 되있으며
test data는 text만 주어저 category를 맞추는 문제였습니다
-
데이터 전처리
2-1 중복 제거, null확인
데이터 학습시 중복과 null을 확인하여 불필요한 데이터 처리를 막기 위해 데이터를 확인하였습니다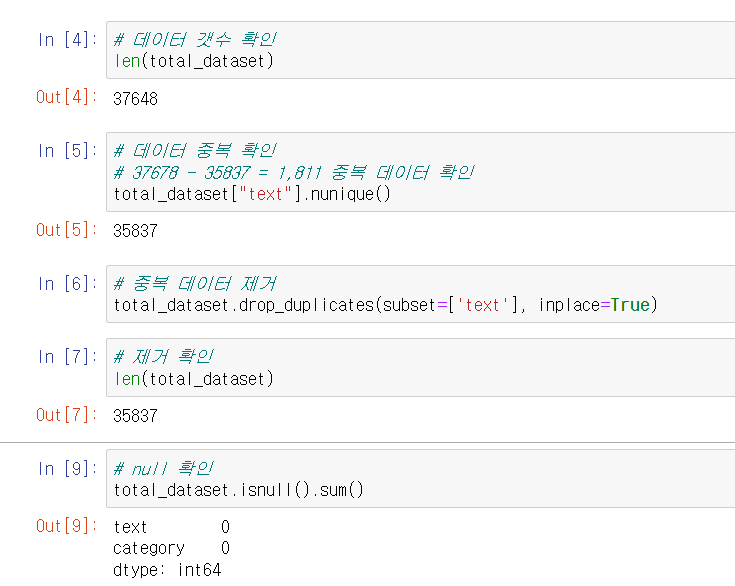
중복된 데이터가 있어 삭제를 제거하고 null 값은 없었습니다
2-2 한글 특수문자 제거
데이터에 특수문자를 제거하여 학습에 불필요한 데이터를 정리하였습니다
2-3 category 종류를 숫자로 변경
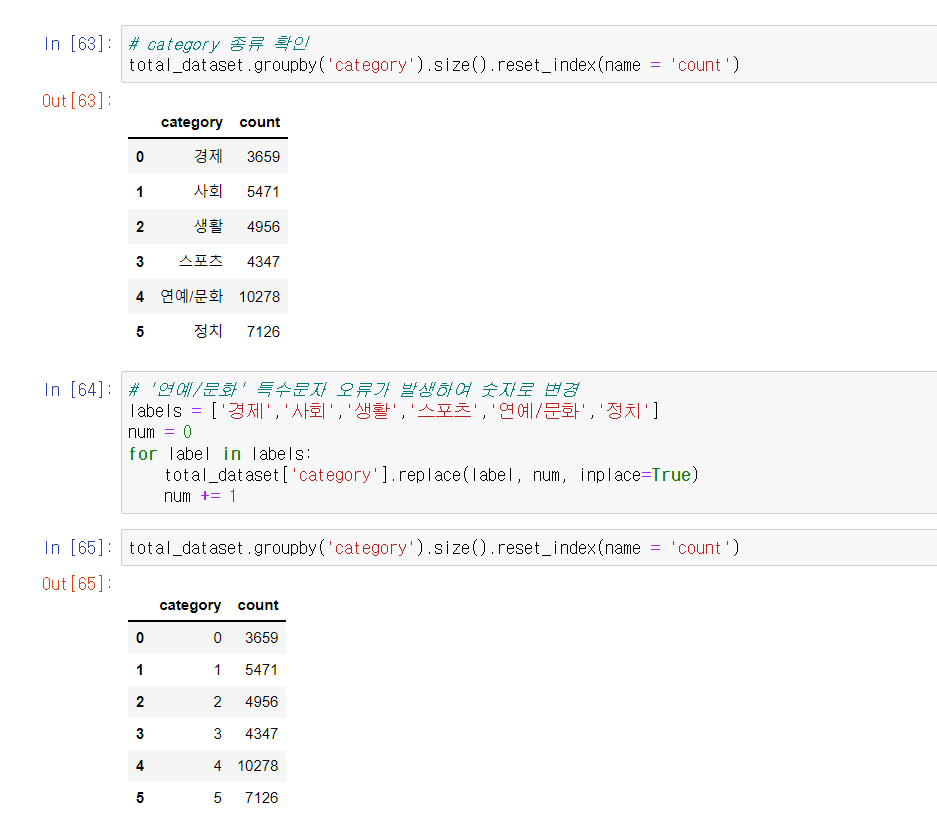
category를 한글과 '/' 특수문자를 그대로 사용하면
오류가 발생함으로 숫자로 미리 변경하여 오류 방지 하였습니다
2-4 데이터 분리
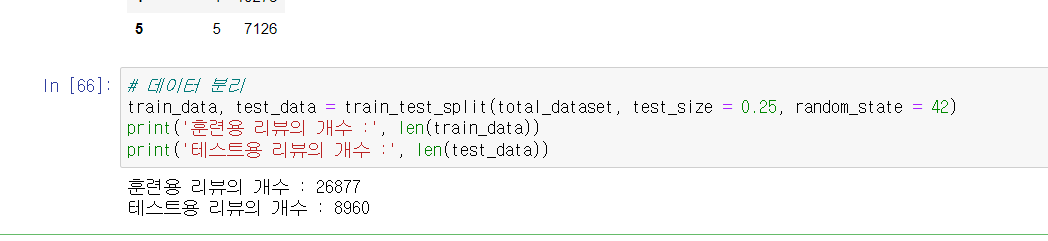 전처리된 데이터를 train_data, test_data로 분리하여 학습할수 있는 데이터로 만들어 주었습니다
전처리된 데이터를 train_data, test_data로 분리하여 학습할수 있는 데이터로 만들어 주었습니다
-
학습 데이터 만들기
3-1 토큰화, 정수 인코딩
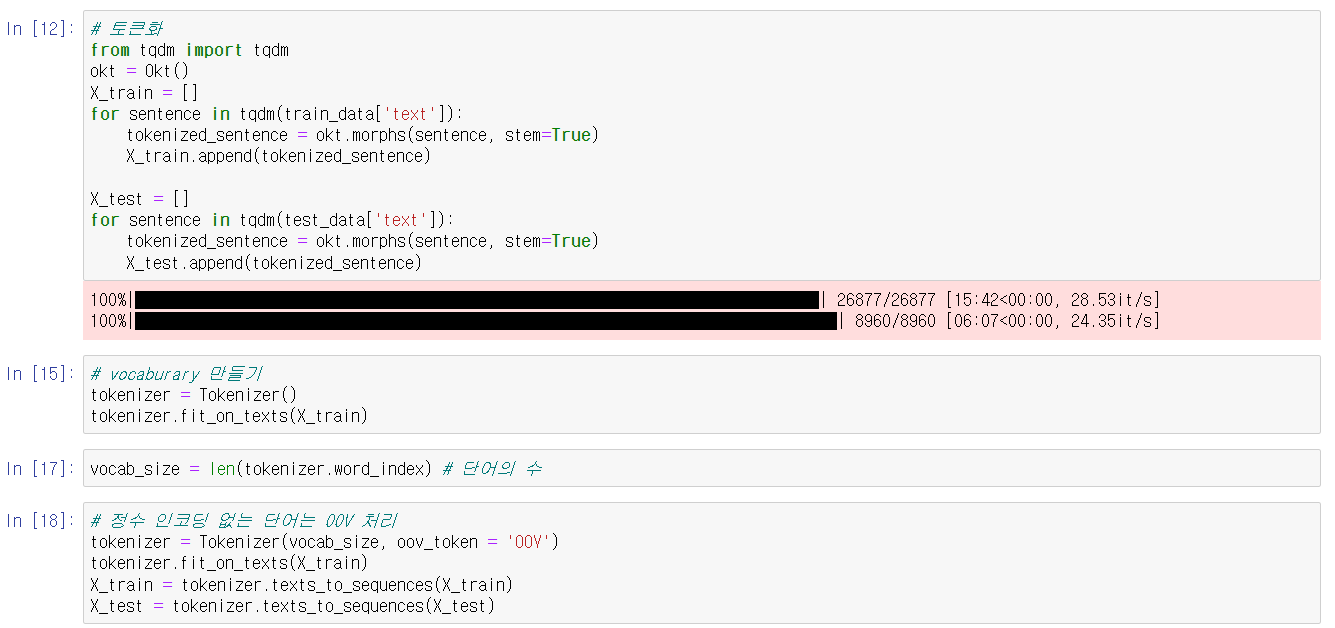
konlpy에 Okt를 사용하여 text를 토큰화 하고
만들어진 토큰을 이용해 vocaburary를 만들어
정수 인코딩 하였습니다3-2 패딩
문장의 길이를 맞춰주어 학습할수 있는 데이터로 만들어 주었습니다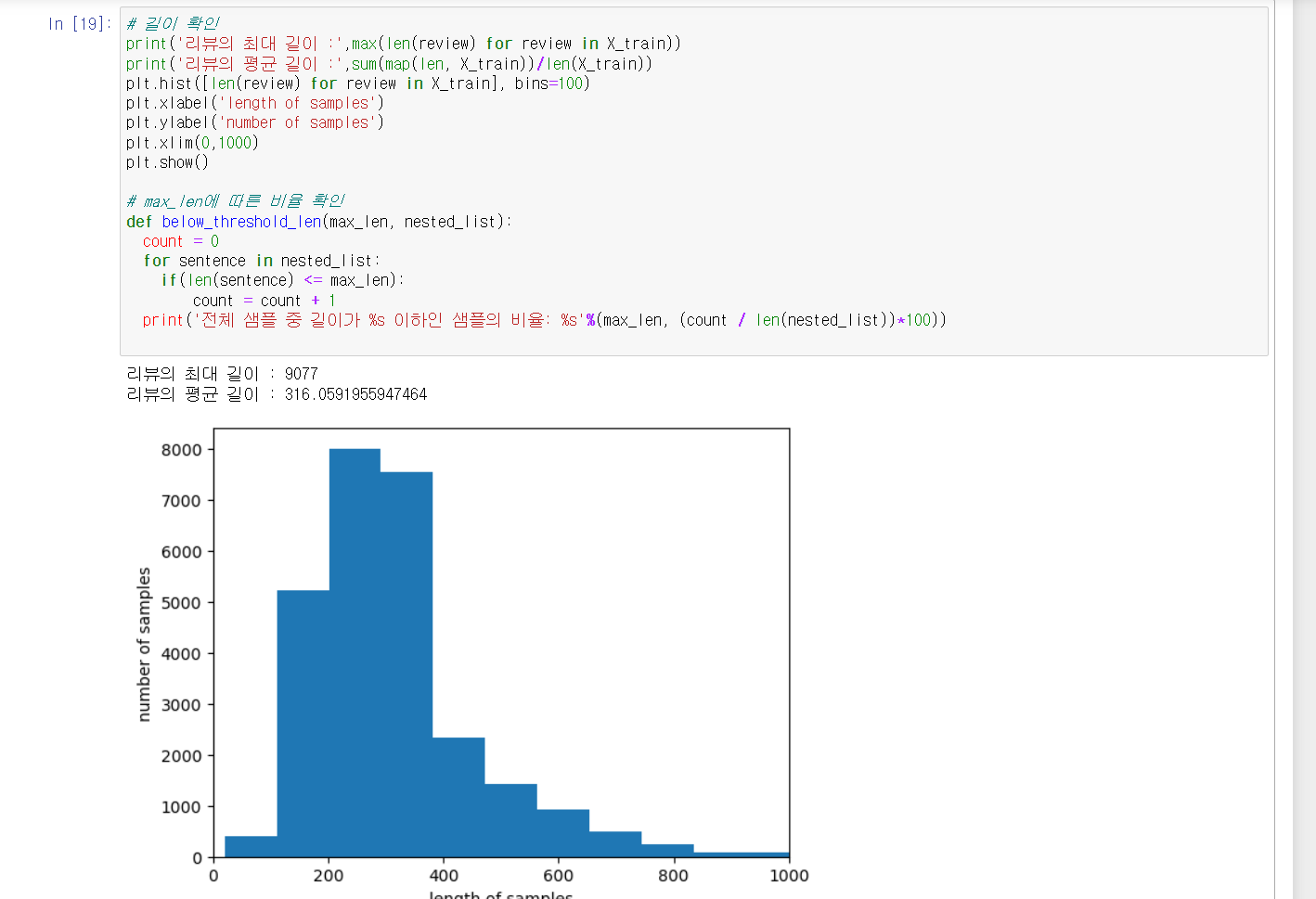
문장의 길이를 시각화 하니600~700 사이의 데이터 부터 빈도수가 줄어드는걸 확인하였습니다
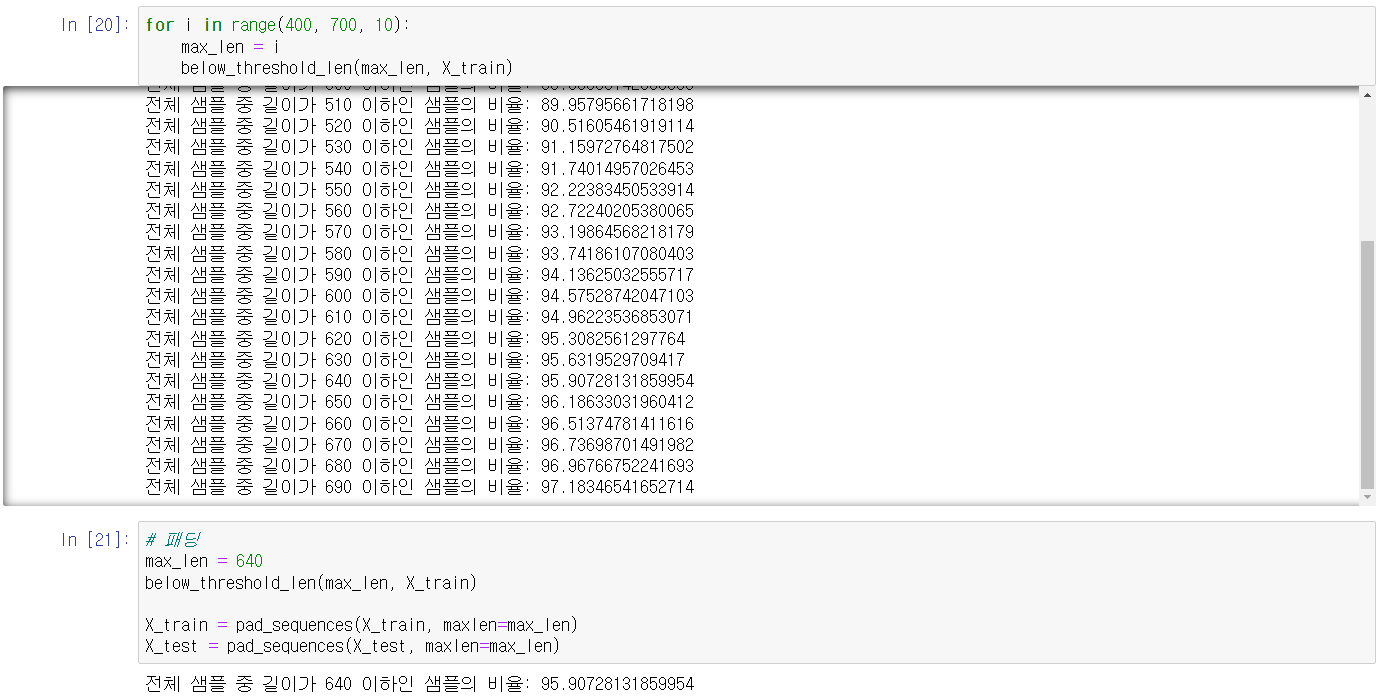
데이터 샘플의 비율을 확인하여 95% 지점을 선택해 패딩을 하였습니다.3-3 정답 데이터 원-핫 인코딩
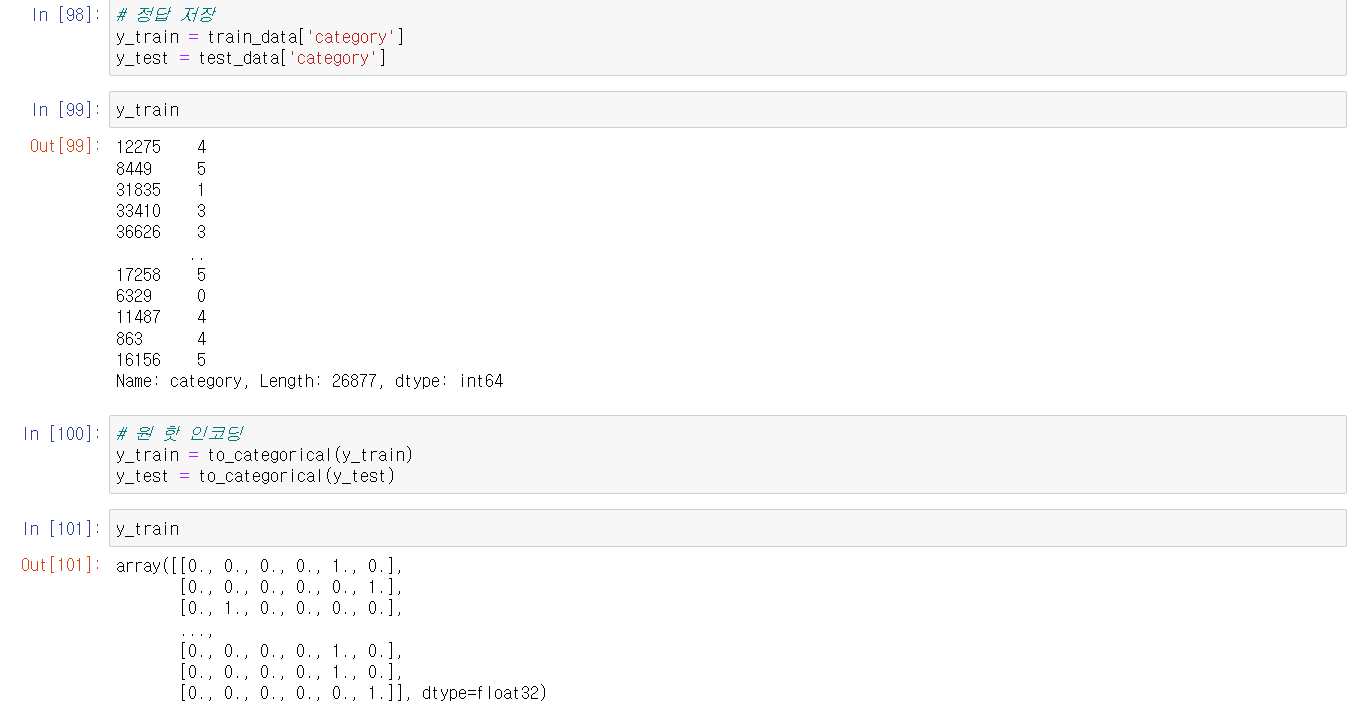
caegory 데이터를 원-핫 인코딩 하여 sofrmax를 활용할수 있는 학습데이터로 만들었습니다 -
데이터 학습
4-1 LSTM을 사용하여 데이터 학습시키기

데이터학습을 위해 자연어 처리에 사용되는 LSTM을 사용하였고
예측값이 6개 임으로 softmax를 사용하였습니다과적합 방지를 위해 EarlyStopping을 사용하였으며
모델을 저장하기위해 ModelCheckpoing를 사용하였습니다
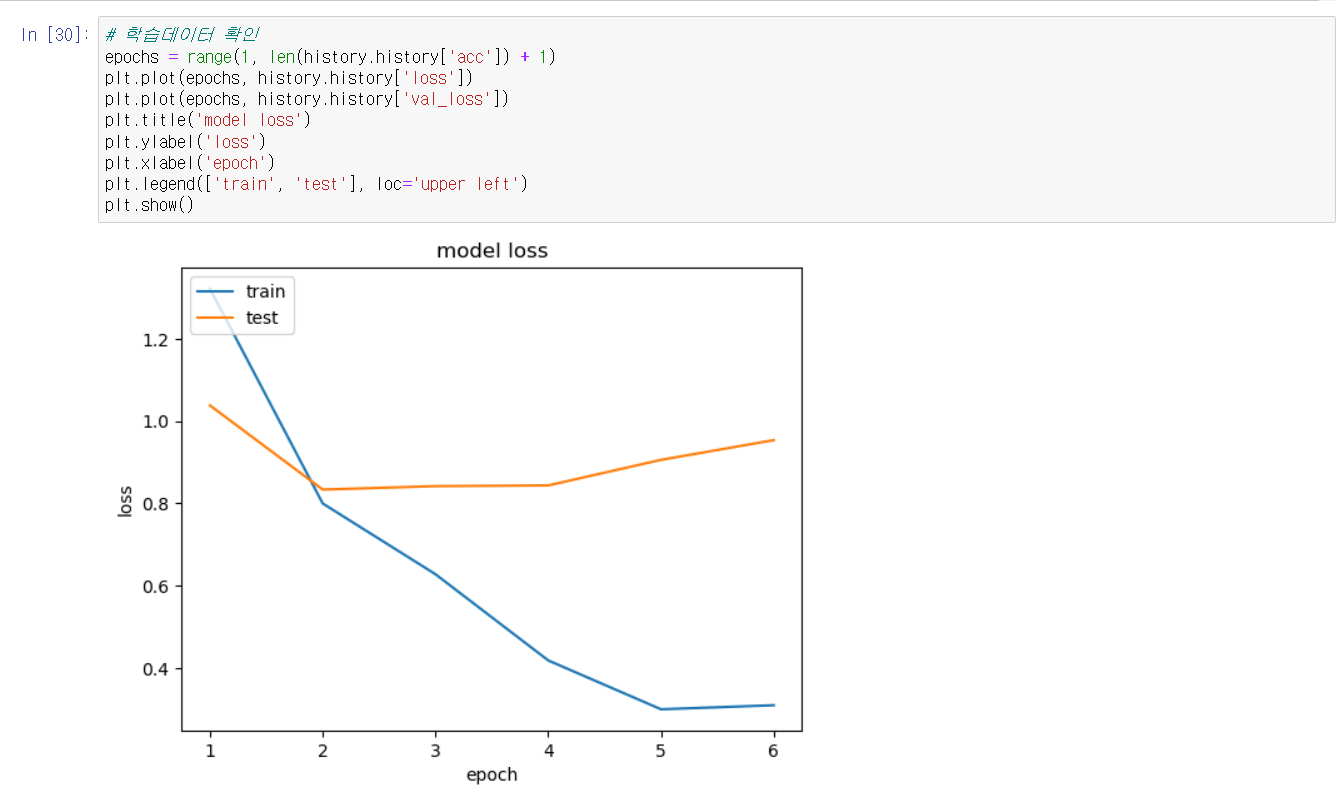
데이터학습 형태를 확인하니 성공적으로 학습이 되었으며
4회차부터틑 예측값의 변화가 없었어 6회차에 종료가 됨을 확인하였습니다
5.예측하기
데이터 예측을 위해 학습용데이터와 동일하게 전처리, 토큰화, 인코딩, 패딩한 데이터를
학습한 데이터에 넣어 값을 예측하였습니다

예측값을 다시 한글 데이터로 변경하고 예측 데이터를 제출하였습니다

약 78% 성공률의 예측값을 얻게 되었습니다
다음은 학습 데이터 향상을 위한 결과입니다
-
불용어 처리, vocab size 줄이기
-인코딩한 데이터안에 불필요하게 많은 데이터가 있어 학습에 방해가 된다고 예상하여
불용어 처리와 vocab size를 줄여 학습을 하였습니다
토큰화 과정중 stopword를 추가하여 불필요한 단어들을 제거하였습니다
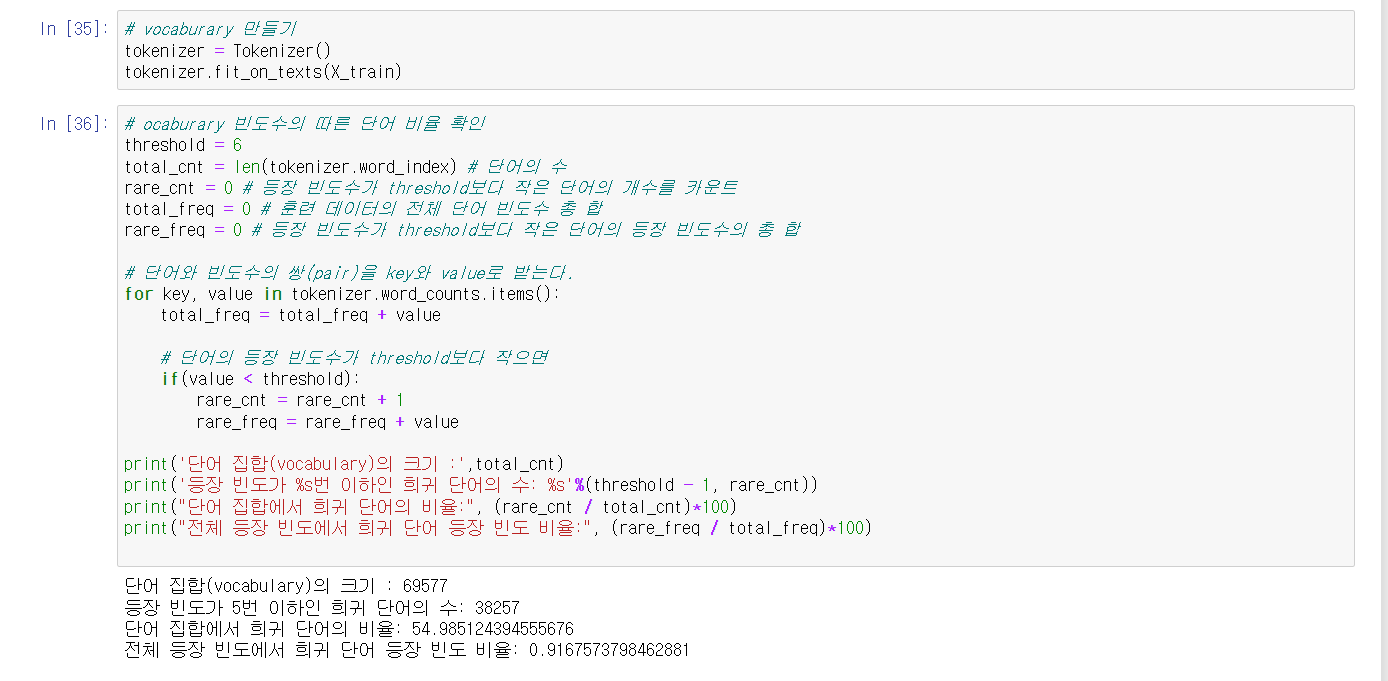
인코딩 이에 희귀 단어 빈도수를 확인하여 필요한 단어들만 남도록 정제 하였습니다
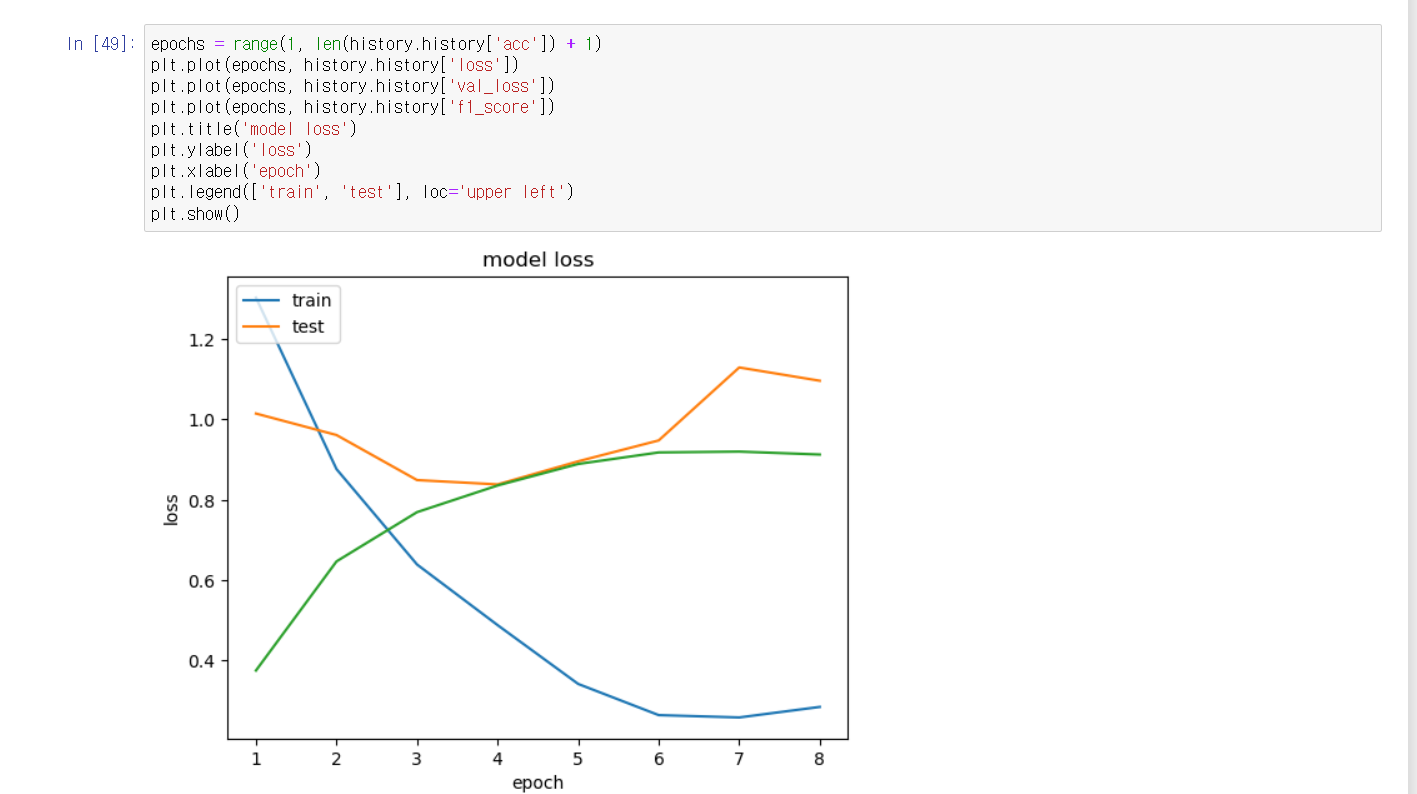
학습에는 눈에 띄는 변화는 없었습니다

71% 성공률을 보이며 오히려 성공률이 줄어들었습니다 -
GPT를 사용하여 학습하기
https://facerain.club/improve-dl-performance/
-이 사이트를 참고해 보니 제가 간단히 할수 있는 방법은 좋은 모델을 선택하는 방법이여서
트랜스포머를 사용한 GPT 모델을 사용하여 데이터를 예측하였습니다
https://wikidocs.net/159431
코드는 이책의 코드를 참고하여 제 데이터 상황에 맞춰 변경하였습니다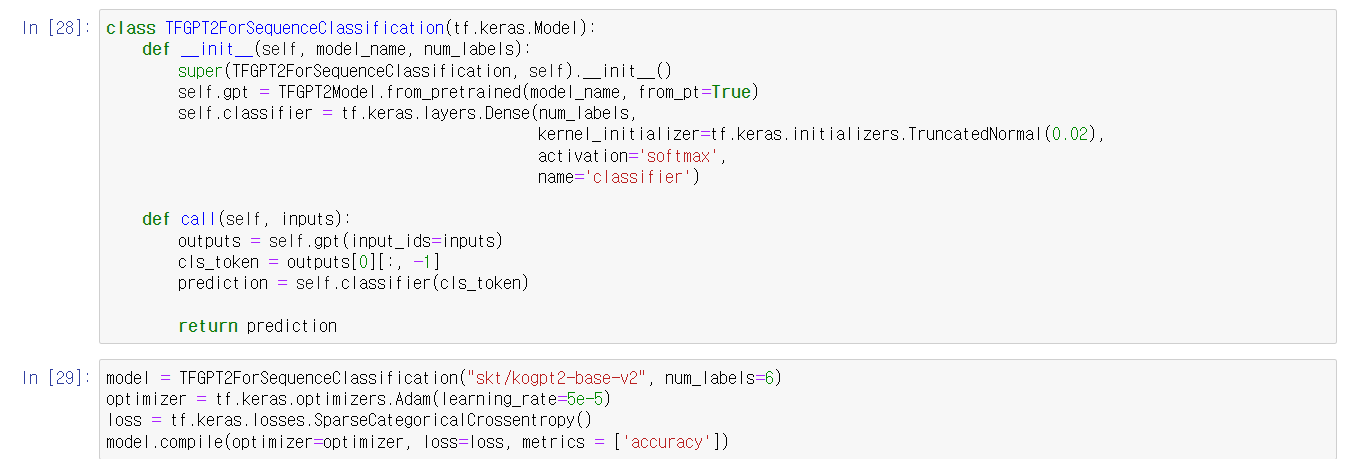
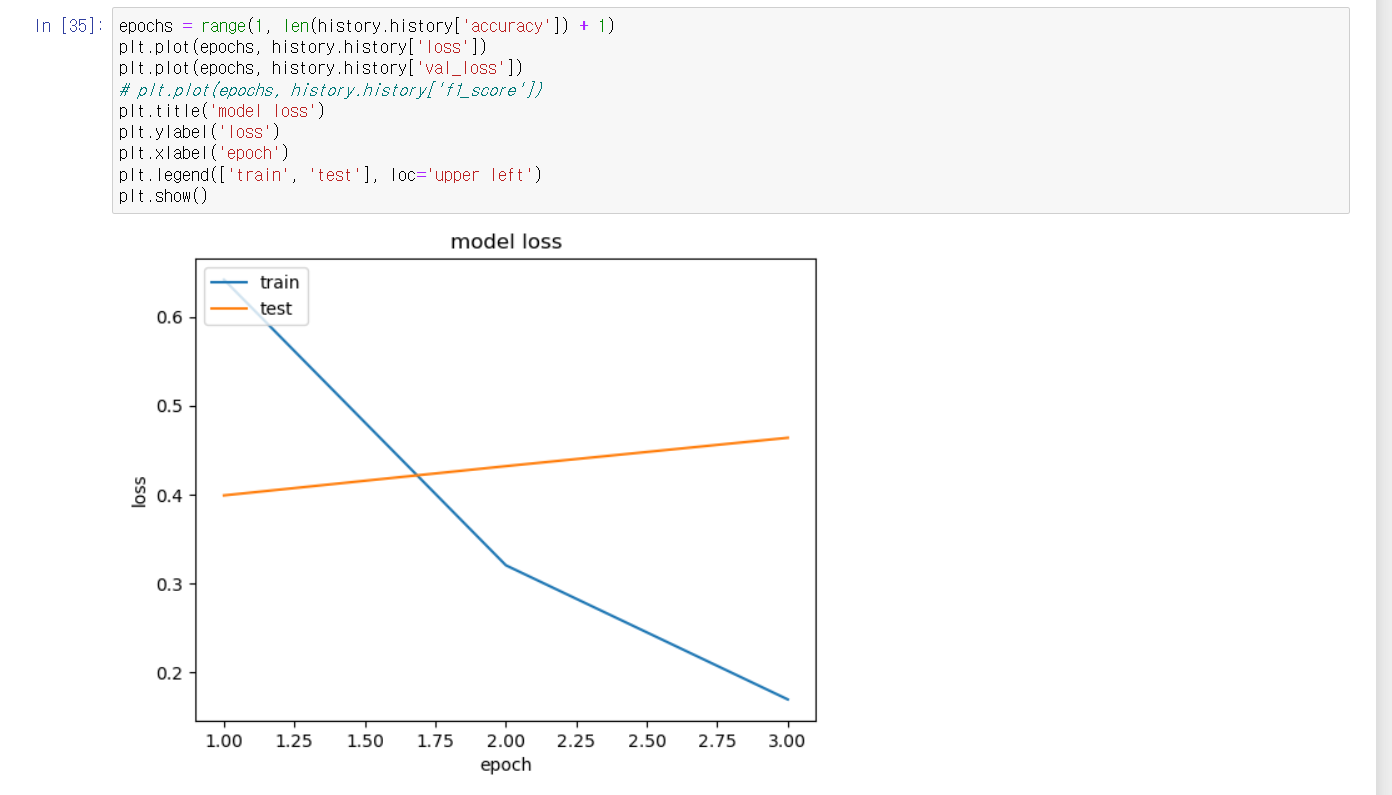
1점데에 머무르던 값이 0.5~0.4 사이에 값으로 줄어들었습니다

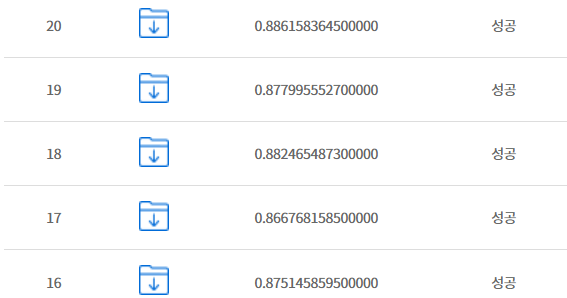
학습을 3회차까지 하니 87% 나왔으며
학습을 여러번 하니 88.6% 향상된 결과를 얻을수 있었습니다

문장 길이 95% 정도로 설정하셔서 진행한 부분 인사이트 얻고 갑니다
감사합니다!