Kafka?
- 분산 스트리밍 플랫폼, 데이터 파이프라인(언제든 데이터를 꺼내 쓸 수 있도록 데이터를 계속 쌓아두는 역할)을 만들 때 주로 사용
Kafka 특징?
- Publisher Subscriber 모델
- Publisher Subscriber 모델은 데이터 큐를 중간에 두고 서로 간 독립적으로 데이터를 생산하고 소비 - 고가용성(High availability) 및 확장성(Scalability)
- 클러스터로서 작동하므로 Fault-tolerant한 고가용성 서비스를 제공할 수 있고 분산처리를 통해 빠른 데이터 처리가 가능
Kafka 구성?
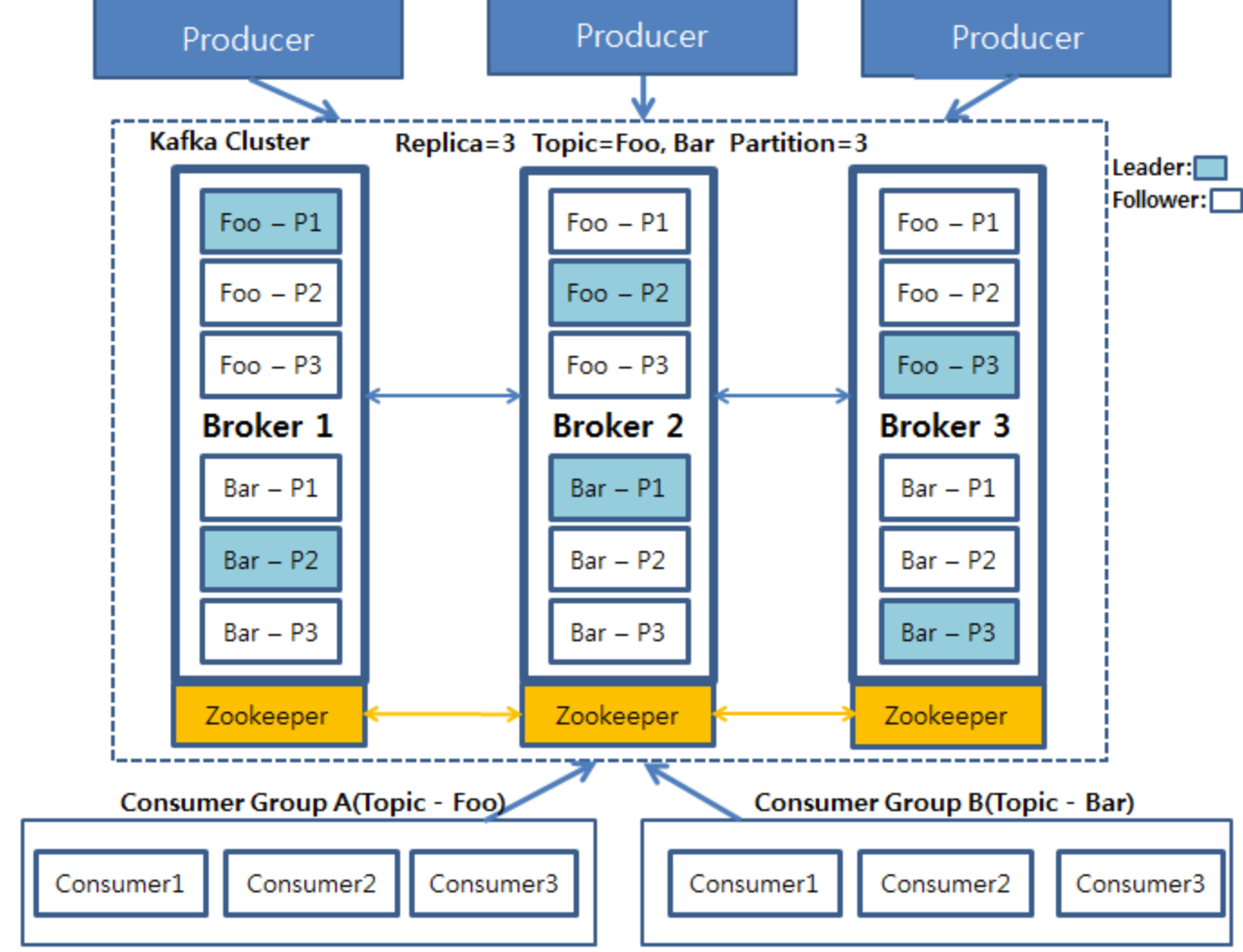
- Producer
- 데이터를 발생시키고 카프카 클러스터(Kafka Cluster)에 적재하는 프로세스 - Broker
- 카프카 서버를 의미 - Zookeeper
- 분산 코디네이션 시스템, 카프타 클러스터의 리더를 발탁하는 방식도 주키퍼에서 제공 - Topic
- 데이터를 관리할 그 기준이 되는 개념
- 하나의 토픽은 1개 이상의 Partition으로 구성 - Partition
- 각 토픽 당 데이터를 분산 처리하는 단위
- 토픽 안에서 파티션을 나누어서 그 수대로 데이터를 분산처리
- Kafka option 에서 지정한 replica 수만큼 파티션이 각 서버들에 복제 - Consumer Group
- 컨슈머의 집합을 구성하는 단위
- 카프카에서는 컨슈머 그룹으로서 데이터를 처리하며 컨슈머 그룹 안의 컨슈머 수만큼 파티션의 데이터를 분산처리
파티션의 읽기, 쓰기
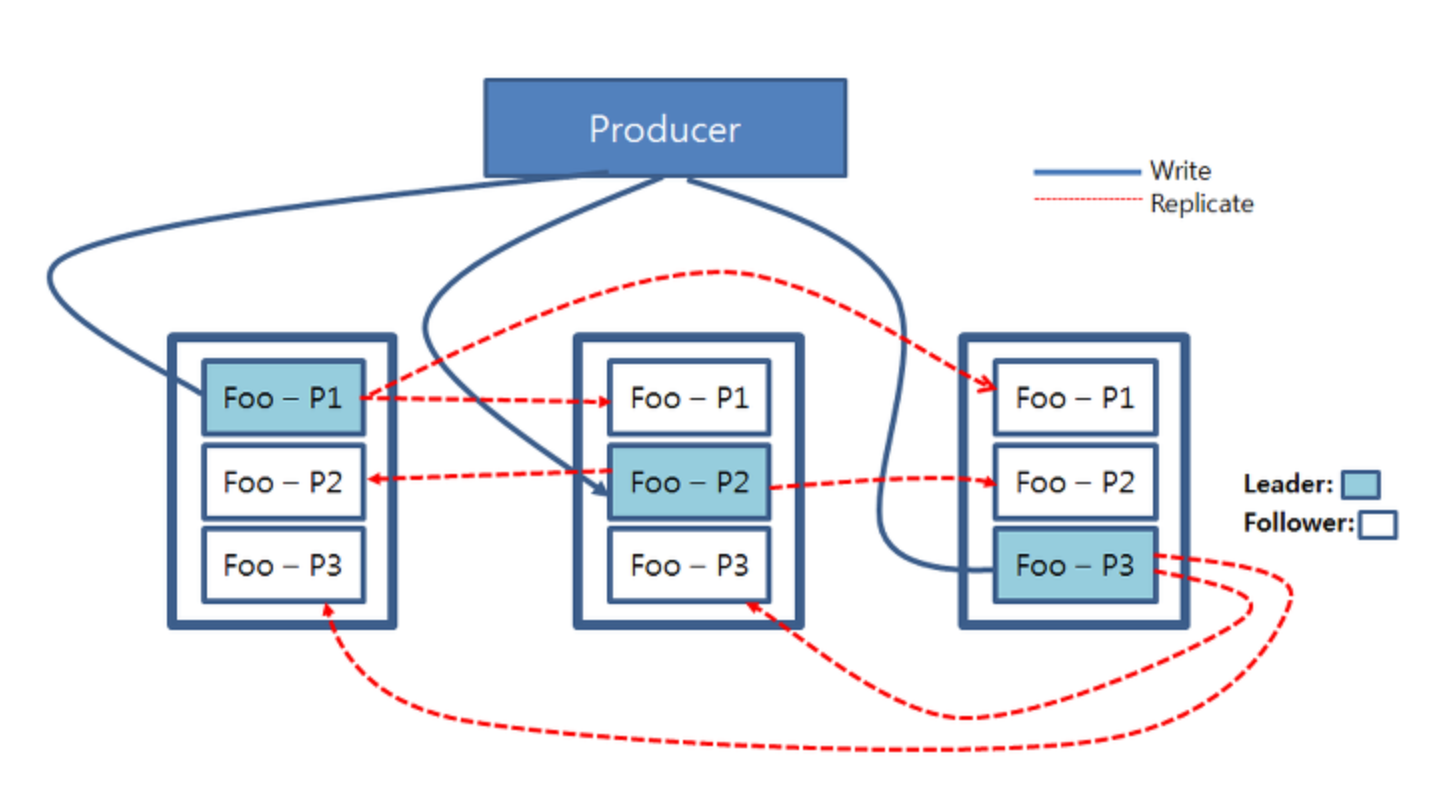
- 쓰기, 읽기 연산은 카프카 클러스터 내의 리더 파티션들에게만 적용
- 하늘색으로 칠해진 각 파티션들은 리더 파티션이고, 프로듀서가 이 파티션들에게 쓰기 연산을 진행
- 리더 파티션에 쓰기가 진행되고 난 후, 업데이트된 데이터는 각 파티션들의 복제본들에게 복사
- Producer에서 생성한 데이터는 '레코드'라고 부르는데, '레코드'를 순서대로 저장하며 저장된 레코드는 FIFO 방식으로 컨슈머에서 fetch
- 컨슈머에서 파티션에 있는 레코드를 가져가도 삭제되지는 않음
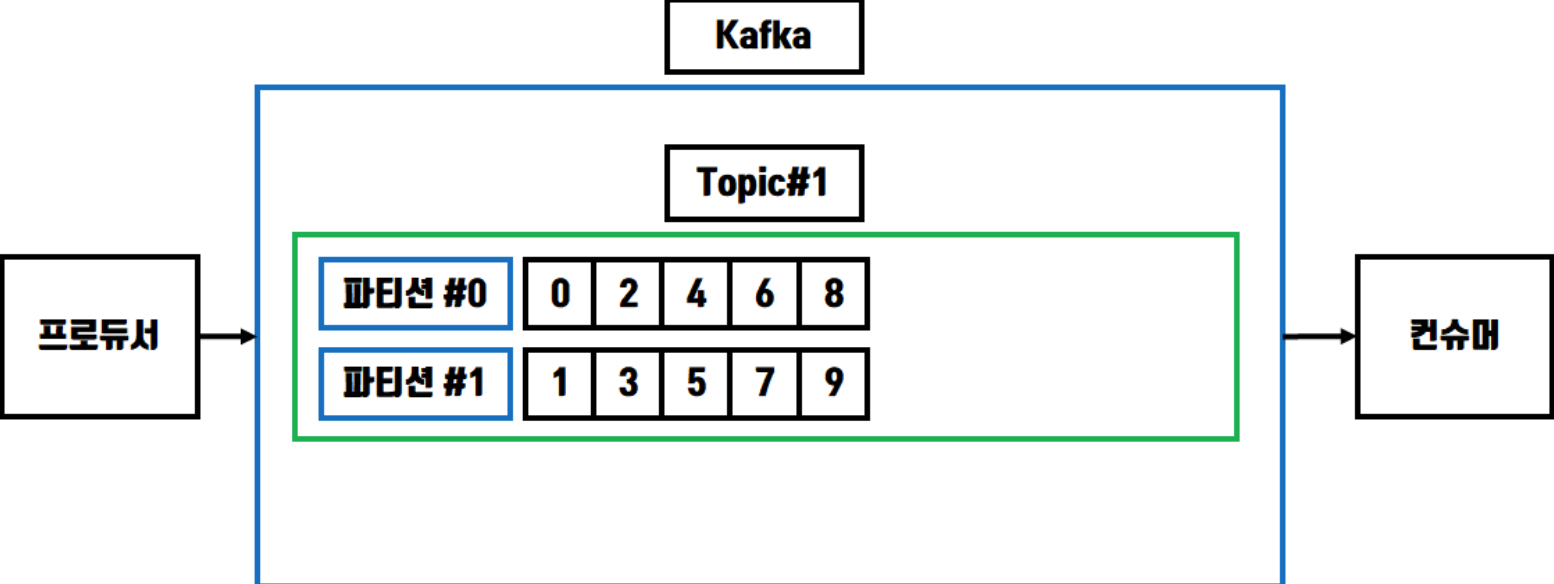
파티션 저장 방법
-
키가 Null 일 때 : Rounde Robin
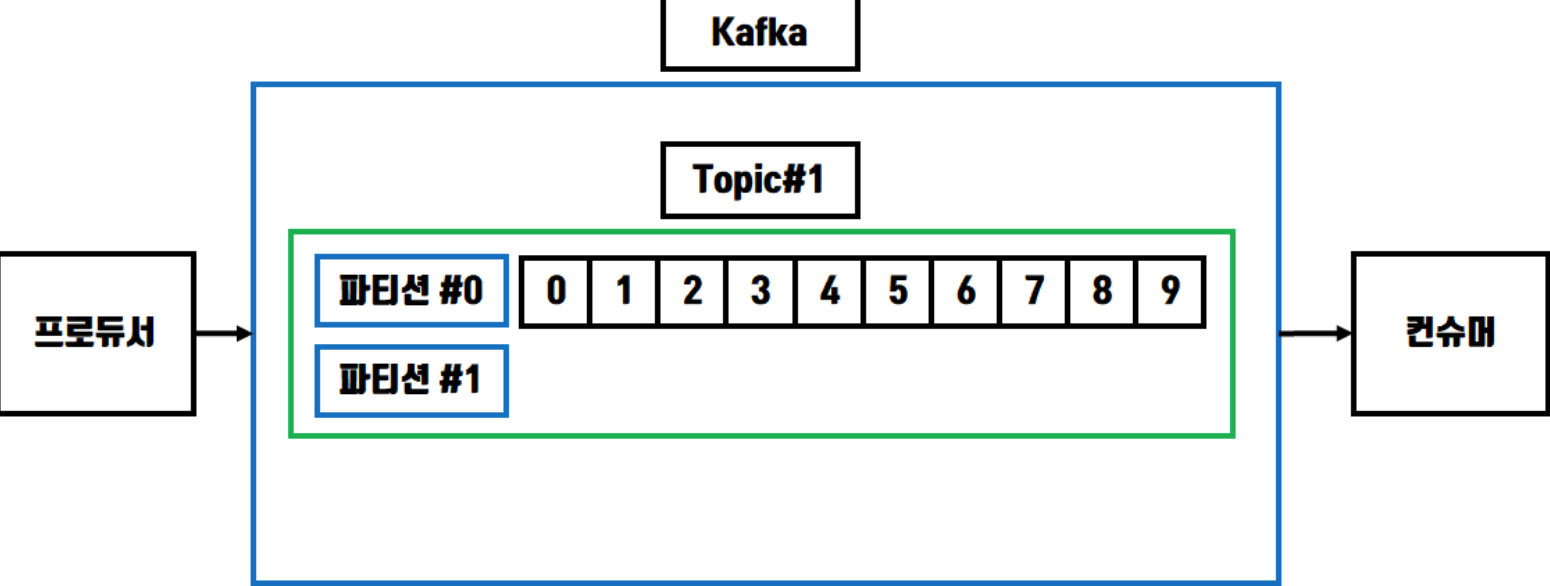
-
키가 있을 때 : Using Hash
컨슈머 그룹에서 Topic 데이터를 가져가는 방법
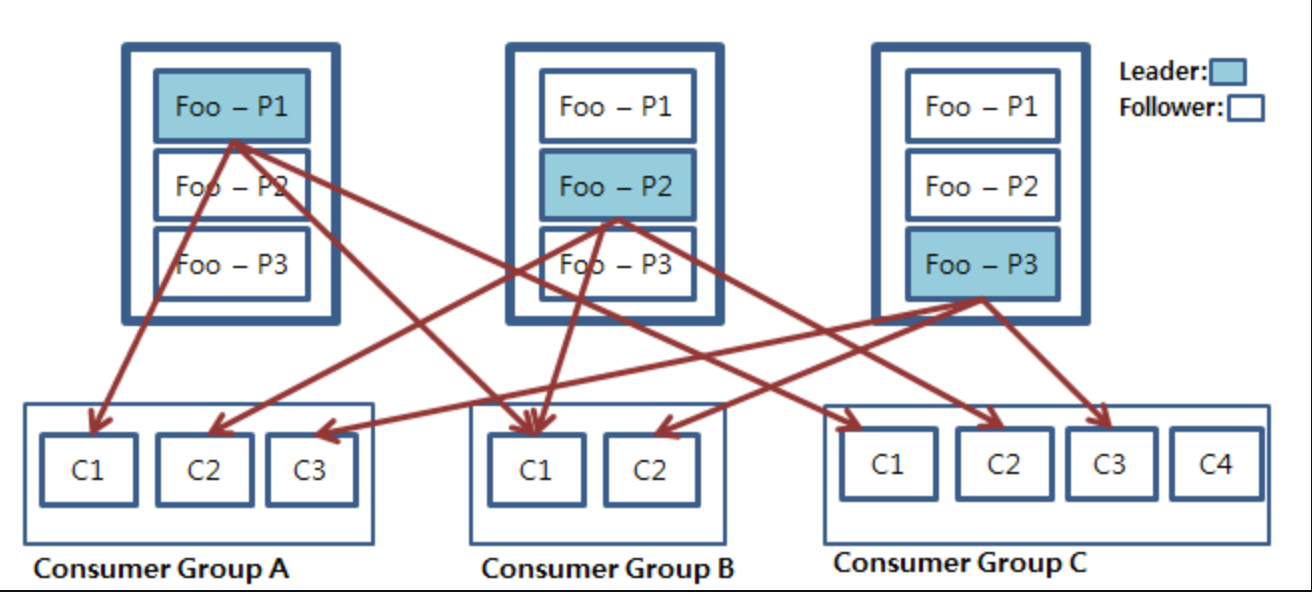
- 만일 컨슈머와 파티션의 개수가 같다면 컨슈머는 각 파티션을 1:1로 매핑
- 만일 컨슈머 그룹 안의 컨슈머의 개수가 파티션의 개수보다 적을 경우 컨슈머 중 하나가 남는 파티션의 데이터를 처리
- 눈여겨 볼 것은 만일 컨슈머의 개수가 파티션의 개수보다 많을 경우 남는 컨슈머는 파티션이 개수가 많아질 떄까지 대기

화이팅!