
JVM에 대해 공부해보자 🤔
- JVM 이란?
- 동작 방식
- JDK vs JRE
- JVM 구성 요소 (Architecture)
JVM 이란? 🤔
JVM은 Java Virtual Machine의 약자로, 흔히 자바 가상 머신이라고 부릅니다.
JVM은 자바와 운영체제 사이에서 일종의 중개자 역할을 수행하며, 운영체제에 구애 받지 않고 프로그램을 실행할 수 있도록 도와줍니다.
동작 방식 ⭐️
자바는 기본적으로 한 번 작성한 내용은, 어디서든지 읽고 실행될 수 있다. 라는 "Write once, Run Anywhere"의 의미를 가지고 만들어진 언어입니다.
예를 들어 C++ 프로그램 같은 경우 특정 운영체제 혹은 하드웨어에서 실행되기 위해 컴파일된 후 사용하지만, 자바는 byte code로 컴파일이 이루어집니다. 이 byte code가 우리가 흔히 IDE에서 볼 수 있는 .class 파일입니다. 이때 JDK 안에 내장되어 있는 자바 컴파일러(javac)를 사용하여 컴파일하게 되면 내부적으로 이 byte code를 JVM이 OS와 하드웨어가 이해할 수 있는 기계어로 바꾸게 됩니다.
이러한 과정으로 인해 byte code는 OS, 하드웨어에 종속되지 않고 독립적으로 존재할 수 있습니다. 그 이유는 OS 종류와 관계없이 오직 JVM을 위한 컴파일만 하면 되기 때문입니다. 하지만 JVM은 사용중인 OS에 맞는 적합한 버전을 선택해야합니다. 그래야만 어느 운영체제에서도 실행될 수 있는 프로그램을 만들 수 있습니다.

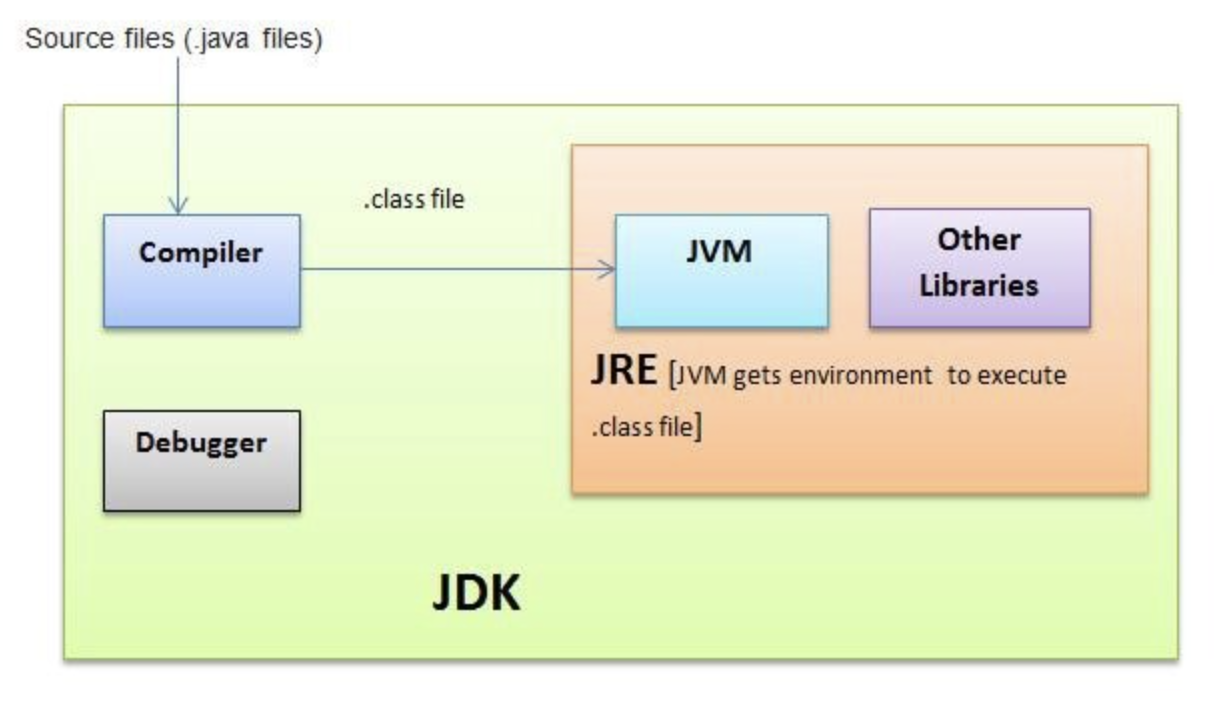
JRE vs JDK 🤔
자바를 공부하면서 JVM, JRE, JDK는 가장 맨 처음에 나오는 용어이자, 자바 프로그래밍에서 없어선 안될 존재입니다. 하지만 실제 공부하는 입장에선 참 헷갈릴만한 이름들인데, 이번 기회에 정리해보겠습니다.
- JDK는 Java Development Kit, 자바 기반의 소프트웨어를 개발하기 위한 도구 즉, 자바 프로그램을 만드는 개발자가 사용하는 도구입니다.
- JDK에는 자바 프로그램 개발에 필요한 프로그램이 들어있고, 동시에 JVM과 필수 자바 라이브러리가 포함되어 있다. 즉, JDK는 JRE를 포함하고 있습니다.
- JRE는 Java Runtime Environment, 자바 코드를 실행하기 위한 환경입니다. 즉, Java byte code를 실행할 때 필요한 프로그램들로 이루어진 환경을 말합니다. JDK가 개발자를 위한 도구라면 JRE는 사용자를 위한 도구라고 생각하시면 이해가 빠를 것 같습니다. 이 환경안에 JVM 이 포함되어 있습니다.
이를 바탕으로 앞에서 설명한 자바의 작동 과정을 다시 간단히 살펴보면
- 개발자가 Java 코드를 작성한다.
- JDK 내부에 있는 자바 컴파일러로 컴파일을 한다.
- byte code(.class)로 변환된다.
JVM 구성 요소(Architecture) 🚀
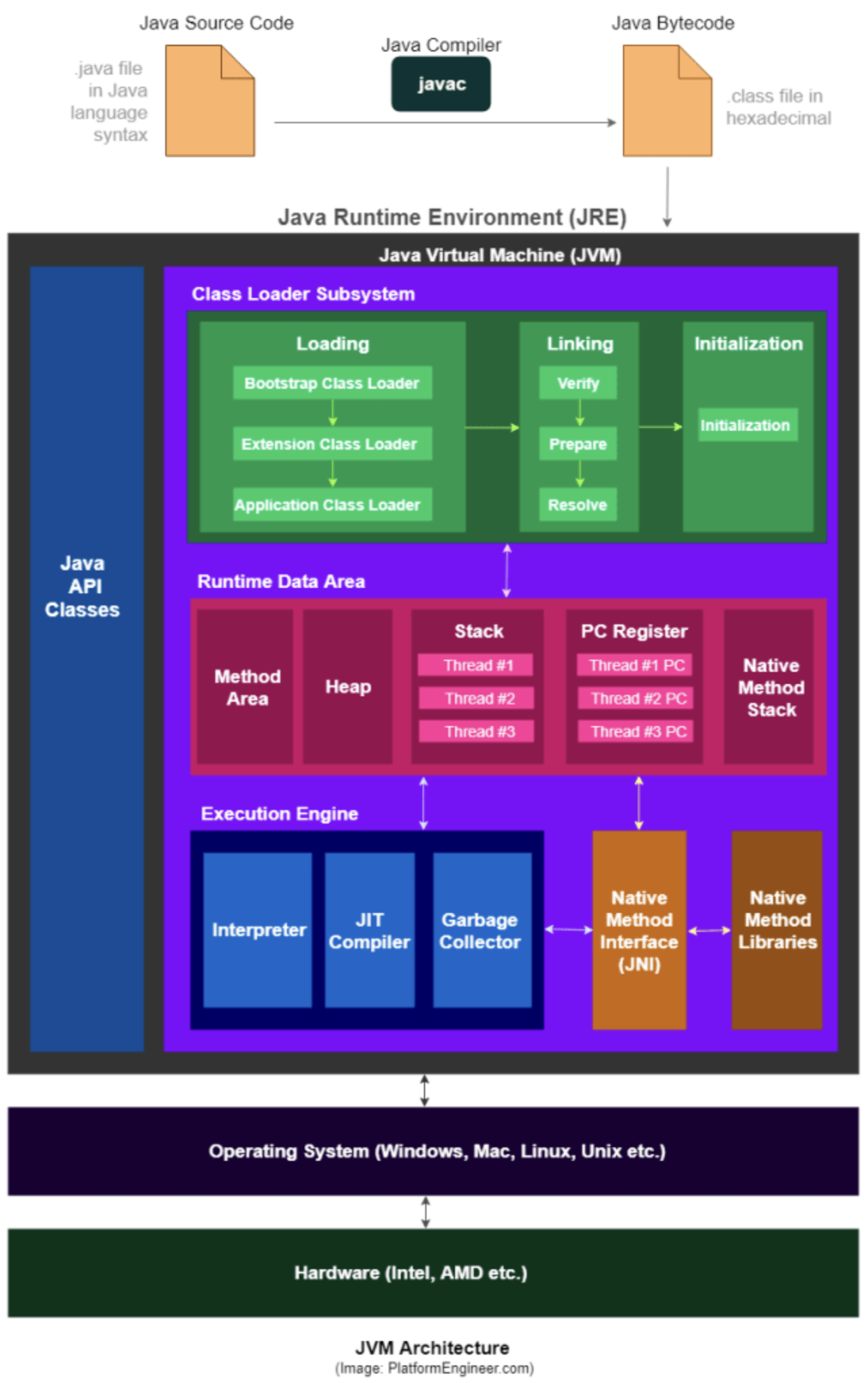
클래스 로더 시스템(Class Loader Subsystem) 🚀
- 클래스 로더 시스템은 자바 바이트코드(*.class)를 실행시점(RunTime)에 읽어들여서 JVM의 메모리 영역(Runtime Data Area)에 적절하게 배치시켜주는 역할을 합니다.
- 크게 로딩 -> 연결 -> 초기화 과정을 거칩니다.
로딩(Loading)
- .class 파일을 읽고, 그 내용에 따라 적절한 바이너리 데이터를 만들고 메소드 영역에 저장하는 동작을 수행합니다. 이때 메소드 영역에 가장 먼저 저장되는 것은 우리가 알고 익히 알고 있는 static main() 메소드부터 시작됩니다.
연결(Linking)
- 로드된 클래스나 인터페이스를 검증(verify)하고 준비(prepare)하는 과정입니다.
- 로드된 클래스 데이터는 3단계의 Verify(검증) -> Prepare(준비) -> Resolution(실행) 과정을 거치게 됩니다.
Verify(검증)
읽은 클래스의 바이너리 데이터에 대한 유효성 검사를 실시합니다.
.class 파일 형식이 유효한지부터 시작하여 여러가지 체크를 진행한 후 .class 파일 데이터인 경우 그 다음 단계를 진행합니다.Prepare(준비)
JVM에 의한 데이터 구조나 static 저장공간을 위해서 메모리를 할당하는 과정이다. static field는 기본 값으로 생성되고 초기화된다.
Resolution(실행)
이 단계에선 Symbolic reference가 direct reference로 대체된다. 다시 풀어서 이야기하면 참조하고자 하는 대상의 이름만 가지고 참조 관계를 구성하는 것이 아닌, 실제 객체의 주소를 참조하게 된다. 여기서 실제 객체의 주소를 참조한다는 것은 메모리에 할당된 실제 주소를 코드에 반영하고 실행 가능한 바이너리 코드가 된다는 것이다.
초기화(Initialization)
- static 변수의 값을 할당합니다. static 블럭은 이때 실행됩니다.
메모리(Runtime Data Area) 🚀
- 자바 컴파일러가 컴파일한 byte code를 ClassLoader를 이용해 메모리(Runtime Data Area)에 실행 가능한 상태로 적재하는 곳입니다.
- Runtime Data Area는 JVM이 프로그램을 수행하기 위해 OS로부터 별도로 할당받은 메모리 영역이라고 말할 수 있습니다.
- Runtime Data Area는 Program Count(PC), JVM Stacks, Method Area, Heap, Native Method Stacks으로 구성됩니다.
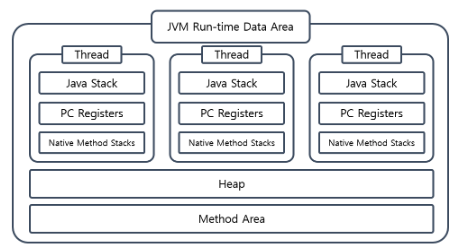
이 중 PC Register, JVM Stacks, Native Method Stacks은 각 스레드 별로 존재한다. 그리고 각 스레드마다 서로 다른 메모리가 할당 된다.
PC Register (프로그램 카운터)
- 현재 수행 중인 명령어의 주소를 가리킨다.
- 스레드가 생성될 때마다 생기는 공간으로 스레드가 어떠한 명령을 실행하게 되는지에 대한 부분을 가리키고 있습니다.
JVM Stack
- 각각의 스레드가 시작될 때 생성
- Stack Frame을 저장하는 스택
- 메소드가 수행될 때마다 하나의 스택 프레임이 생성되어 해당 스레드의 JVM stack에 추가되고(push), 메소드가 종료되면 스택 프레임이 제거된다.(pop)
Native Method Stack
- 자바 스레드와 네이티브 코드(C, C++)로 작성된 코드 사이를 매핑하는 역할을 수행합니다.
Method Area
- 모든 스레드들이 공유하는 메모리 영역이다.
- 더 쉽게 이야기하자면 static 키워드가 붙은 데이터를 위한 공간입니다.
Heap Area
- new 키워드를 통해 생성한 객체를 위한 공간이다.
- new 키워드를 통해 객체를 생성하는 공간이기 때문에 런타임 시 동적으로 할당하여 사용하는 영역이기도 합니다.
- 참조하는 변수나 필드가 없다면 의미 없는 객체로 분리되어 GC의 대상이 됩니다.
실행 엔진(Execution Engine) 🚀
- 클래스 로더를 통해 Runtime Data Area에 배치된 바이트코드를 명령어 단위로 읽어서 실행합니다.
- 이때 두가지 방식 (JIT 컴파일러, 인터프리터)의 조합을 통해 실행됩니다.
인터프리터(Interpreter)
- 바이트코드 명령어를 하나씩 읽어서 해석하고 실행합니다. 이 과정에서 바이트코드가 기계어로 변환됩니다.(비유하자면 삼겹살 1줄 굽고 먹고, 1줄 다시 굽고 먹는 방식 🥓)
JIT 컴파일러(Just In Time Compiler)
- 전체를 컴파일하지 않고, 인터프리터가 자주 사용하는 메소드를 저장하여, 후에 해당 메소드를 사용할때 인터프리터로 해석하지 않고 이미 저장된 기계어를 가져옵니다. (비유하자면 삼겹살 3줄을 미리 굽고 먹는 방식 🥓)
