✍️ 이번에 다루어 볼 것은 위드클라우드 이다.
-
초연결 시대 사회에서 SNS혹은 이커머스에서는 해시태그를 통한 검색 최적화가 필수적이다.
예를들어, 스마트스토어를 하고있을때 중복된 상품을 판매하는 사람은 수십, 수백명이 될 수 있다.
따라서 이들과 경쟁에서 우위를 선점하기 위해서는 잠재적 고객들이 들어올 수 있게 적절한 태그를 사용하여 검색 최적화작업이 필수적이다. -
이러한 이유로 인터넷 상에는 수많은 태그들이 존재하며 이를 통해 인사이트를 얻을 수도 있고, 필요한 것을 쉽게 찾을 수 있다. 바로 이러한 태그를 활용한 데이터 분석기법중 하나인 위드클라우드를 사용 해 보았다.
(데이터 셋은 캐글의 " Sales of summer clothes in E-commerce Wish " 에서 가져왔다)
# 데이터프레임의 tag확인하기
df['tags']
>>>
0 Summer,Fashion,womenunderwearsuit,printedpajam...
1 Mini,womens dresses,Summer,Patchwork,fashion d...
2 Summer,cardigan,women beachwear,chiffon,Sexy w...
3 Summer,Shorts,Cotton,Cotton T Shirt,Sleeve,pri...
4 Summer,Plus Size,Lace,Casual pants,Bottom,pant...
...
1565 Summer,Leggings,Fashion,high waist,pants,slim,...
1567 bodycon jumpsuits,nightwear,Shorts,slim,Body S...
1568 bohemia,Plus Size,dandelionfloralprinted,short...
1570 runningshort,Beach Shorts,beachpant,menbeachsh...
1572 Summer,Leggings,slim,Yoga,pants,Slim Fit,Women...
Name: tags, Length: 1304, dtype: object해당 데이터의 경우 쉼표로 태그들이 구분되어 있으며 "#" 혹은 "/" 로 구분되어 있는 경우도 많다.
순서대로 진행해 보았다.
# 태그 나누기
tags_total = []
for tags in df['tags']:
tags_list = tags.split(',') # 쉼표로 나누어 준다.
for tag in tags_list:
tags_total.append(tag)
tags_total
>>>
['Summer',
'Fashion',
'womenunderwearsuit',
'printedpajamasset',
'womencasualshort',
"Women's Fashion",
'flamingo',
'loungewearset',
'Casual',
'Shirt',
'casualsleepwear',
'Shorts',
'flamingotshirt',
'Elastic',
'Vintage',
'Tops',
.
.
.위와 같이 태그들을 쉼표별로 구분을 지어 담아 주었습니다.
다음은 빈도수를 집계해주는 모듈을 이용하여 각 단어별로 빈도를 집계하겠습니다.
from collections import Counter
tag_counts = Counter(tags_total)
# 가장 많이 사용된 태그 50개 확인
tag_counts.most_common(50)
>>>
[("Women's Fashion", 1092),
('Summer', 1074),
('Fashion', 904),
('Women', 805),
('Casual', 736),
('Plus Size', 523),
('sleeveless', 469),
('Dress', 446),
('Shorts', 445),
('Tops', 426),
('sexy', 279),
('Beach', 272),
('Sleeve', 244),
('short sleeves', 241),
('Print', 239),
('Shirt', 238),
('Tank', 220),
('T Shirts', 203),
('V-neck', 198),
('printed', 197),
('Necks', 195),
.
.이런식으로 가장 많이 등장한 단어를 순서대로 뽑아줍니다.
이제 워드 클라우드를 사용하여 만들어 보겠습니다.
import wordcloud import WordCloud
wordcloud = WordCloud(background_color = 'white', max_words = 100, relative_scaling = 0.5, width = 800, height = 400).generate_from_frequencies(tag_counts)
plt.figure(figsize = (15,10))
plt.imshow(wordcloud)
plt.axis('off')이렇게 넣어주시면 아래와 같이 출력이 됩니다.
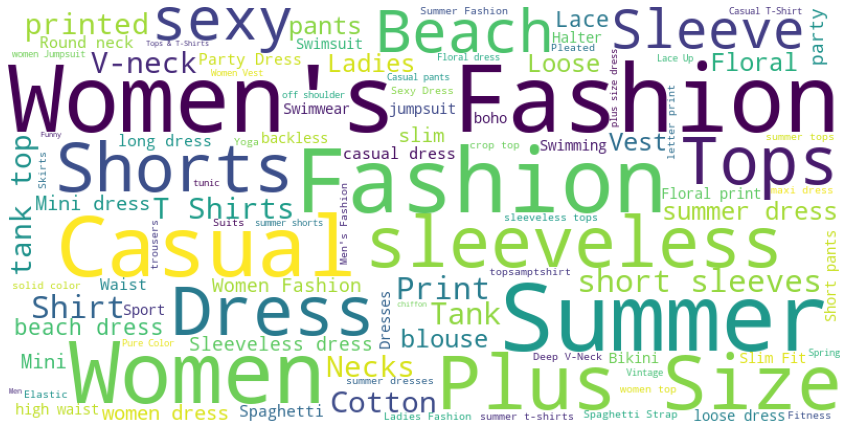
해당 이미지는 출력할때마다 색이나 위치가 조금씩 바뀝니다.
하지만 여기서 mask기법을 활용하여 좀 더 퀄리티를 올려 볼 수 있습니다.
from PIL import Image
mask = np.array(Image.open('증명사진.jpg'))
mask
>>>
array([[[255, 255, 255],
[255, 255, 255],
[255, 255, 255],
...,
[255, 255, 255],
[255, 255, 255],
[255, 255, 255]],
[[255, 255, 255],
[255, 255, 255],
[255, 255, 255],
...,
[255, 255, 255],
[255, 255, 255],
[255, 255, 255]],이렇게 사진 한장을 불러와 줍니다.
plt.figure(figsize =(8, 8))
plt.imshow(mask, cmap = plt.cm.gray, interpolation='bilinear')
plt.axis('off')
plt.show()그리고 사진을 확인을 해 봅니다.
이후 워드클라우드를 불러옵니다.
wordcloud = WordCloud(background_color = 'white',
max_words = 100,
relative_scaling = 0.5,
width = 800,
height = 400,
mask =mask).generate_from_frequencies(tag_counts)
plt.figure(figsize = (15,10))
plt.imshow(wordcloud)
plt.axis('off')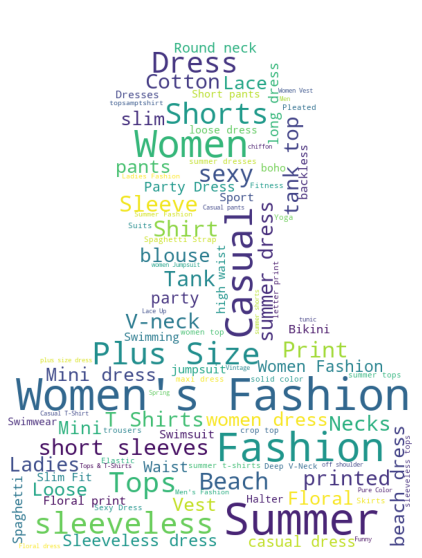
이러면 사진의 흰색부분을 제외한 곳에 단어가 채워집니다!! 다양한 사진을 활용하여 좀 더 꾸밀수 있으니 참고하시길 바랍니다.
