SQL이란??
SQL(Structured Query Languae)은 데이터베이스와 소통할 수 있는 구조화된 쿼리 언어이다.
쿼리란??
파이썬과 다르게 쿼리(query)라는 단어가 나오게되는데 이 쿼리(query)는 무엇일까??
직역을 했을 때 "질의문" 이라고 볼 수 있다. 예를들어 검색을 할 때 입력하는 검색어도 일종의 쿼리라고 볼 수 있다.
즉, SQL이란 데이터베이스 용 프로그래밍 언어이다. 따라서, 데이터베이스에 쿼리를 보내 원하는 데이터만 가져올 수 있다.
그리고 이름에서 알 수 있듯이 SQL은 structured즉 relation이라고도 불리는, 데이터가 구조화된 테이블을 사용하는 데이터베이스 에서 활용 가능하다.
반면 데이터 구조가 고정되어 있지 않은 데이터베이스들은 NoSQL이라고도 불린다. 관계형 데이터베이스와는 달리 테이블을 사용하지 않고 다른 형태로 데이터를 저장한다. 예를들어 MongoDB와 같은 문서 지향의 데이터베이스가 있다.
관계형 데이터베이스의 간단한 키워드 정리
- 데이터 : 각 항목에 저장되는 값.
- 테이블(relation) : 사전에 정의된 행과 열로 구성되어 있는 체계화된 데이터
- 필드(column) : 테이블의 열
- 레코드(tuple) : 테이블의 한 행의 저장된 정보
- 키 : 테이블의 각 레코들을 구분할 수 있는 값, 각 레코드마다 고유값이어야 하며 기본키(primary key)와 외래키(foreign key)등이 있다.
기본키(primary key)와 외래키(forign key)
- 기본키는 설계자가 여러 후보키 중 하나를 선택하여 정의한 식별자로서 기본키의 모든 필드의 값은 null이 될 수 없다. 예를들면
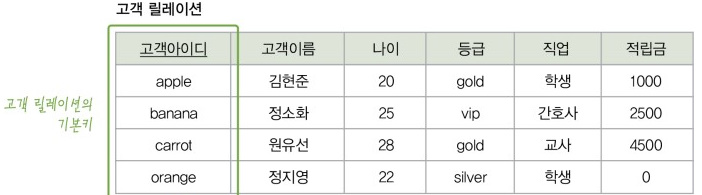
< 사진출처 : 네이버 지식백과 >
위와 같이 고객릴레이션이라는 테이블에서 고객아이디와 같은것을 기본키 라고 한다. 외래키 설명을 통해 이해를 도울 수 있다.
- 외래키는 다른 테이블의 기본키를 참조한다. 외래키의 모든 필드는 참조하는 기본키와 동일한 값의 종류나 범위를 갖는다. 외래키의 모든 필드의 값은 기본키와 동일하거나 null이다.

< 사진출처 : 네이버 지식백과 >
이 둘의 관게 를 정리하면 다음과 같다.
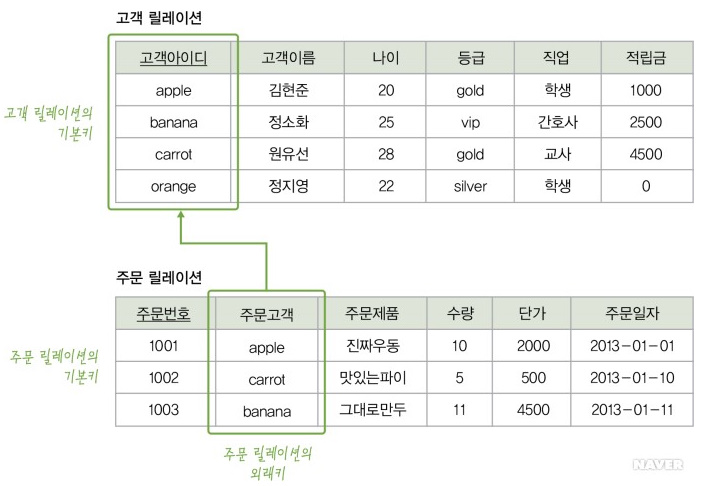
< 사진출처 : 네이버 지식백과 >
참고) Primary키는 unique즉, 중복이 없고, NULL값이 있으면안되며 수정,업데이트가 되어서는 안된다. 기본키가 수정및 업데이트 되면 다른 테이블도 변경을해줘야하기 때문(외래키있는테이블)
테이블간의 관계
데이터 베이스에는 여러 테이블들이 서로 관계를 가지고 있는 경우가 많다. 종류로는 1:1 관계, 1:N관계, N:N관계, 테이블자체관계(self referencing) 이렇게 네가지가 있다.
1:1 관계
테이블의 레코드 하나당 다른 테이블의 한개의 레코드와연결된 경우이다.
위의 사진을 예로 들었을때 고객아이디(고객)당 주문번호가 1개인것을 의미한다. 사실 이런경우는 흔치않다. 왜냐하면 고객한명당 여러개의 주문이 존재할 가능성이 크기때문이다.
1:N 관계
한명의 고객이 여러개의 주문번호를 가지고 있는경우이다. 또 다른 예로 한 유자가 가지고 있는 전화번호가 여러개 일 수 있다는 예시를 들 수 있다. 하지만 반대는 성립이 될 수없다. 즉, 한 전화번호는 한 명의 유저만 가질 수 있다.
N:N 관계
여러 개의 레코드가 여러 개의 레코드를 가지는 관계이다.
이런경우 조인함수를 사용하여 따로 테이블을 만들어 관리해야한다.
예를들어 여행 상품이 있다고 가정했을때 여러 개의 여행 상품이 있고 여러명의 고객이 있을때, 한고객은 여러 여행상품을 사용할 수 있고, 한 여행상품은 여러 고객을 가질 수 있다.
N:N관계는 1:N관계 두개로 만들 수 있다.

위와 같은 형태로 '조인 테이블'로 만들어 볼 수 있다.
자기 참조 관계
때때로 테이블 내에서 관계가 필요한 경우도 있다. 예를들어 추천인을 파악하는것인데, 한명의 유저가 한명을 추천할 수 있으면 추천을 받는 유저는 여러명에서 부터 추천을 받는것이 된다.
이를 자기참조 관계라고 부른다.
기본문법
순서
SELECT, FROM, WHERE, ORDER BY, LIMIT, DISTINCT, INNER JOIN, OUTER JOIN, LEFT JOIN
SELECT
단어 뜻 그대로 데이터셋에 포함될 특성들을 특정한다.
FROM
테이블과 관련이 있는 경우 필수로 명시해야 하는 명령어이다. 결과를 도출할 데이터베이스 테이블을 명시하는 것이다.

위 그림을 해석하면 SELECT *은 전체를 선택한다는 뜻입니다. FROM은 사용한 테이블을 지정을 해주어 tracks라는 테이블을 가져와 전체를 확인한다는 뜻입니다. 출력을 하게되면 아래와 같이 출력이 된다.
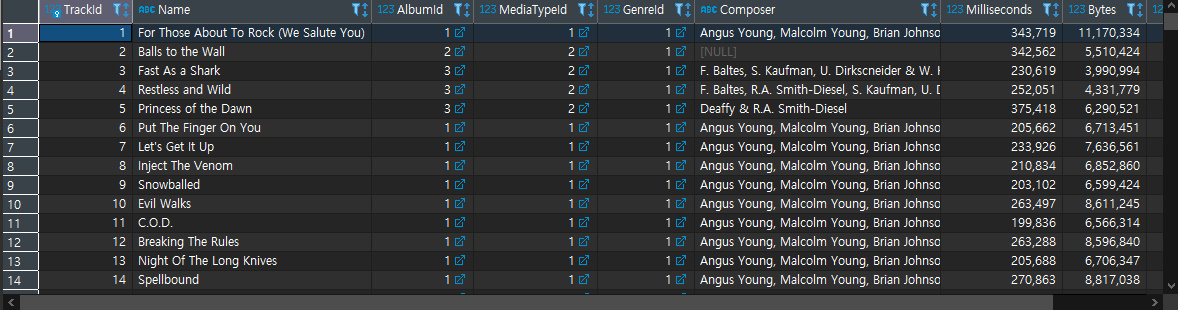
그렇다면 코드를 SELECT Name FROM tracks ; 이렇게 해준다면
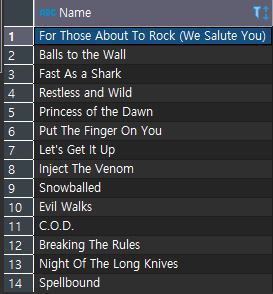
위와 같이 Name만 출력이된다.
즉 SELECT은 가져오고자 하는것을 입력하고 FROM은 테이블을 선택하는것이다.
이때 주의해야 할 점은 쿼리문 마지막에는 항상 ;을 붙여주어야 한다.
그리고 이후에 많은 테이블을 불러올때 혼란을 방지하기 위한 코드작성법을 알아보았다.
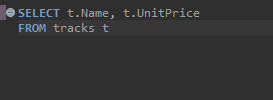
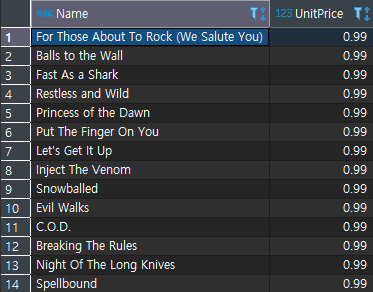
tracks라는 테이블을 불러올때 뒤에 t를 적게되면 tracks를 t로 저장해서 불러오겠다는 뜻이다. tracks는 너무 길기때문에 변수로 불러오는것이다. 이것이 효과적인 이유는 SELECT를 보면 두개의 컬럼을 지정한것을 알 수 있다. 현재는 한개의 테이블이지만 join을 하여 여러개의 테이블을 합쳤을때는 어떤 테이블의 변수인지를 알기 위해 변수를 앞에 붙이고 뒤에 컬럼명을 써줌으로서 혼란을 방지할 수 있다. 이를 출력해 보면 다음과 같다.
WHERE
WHERE는 필터역할을 하는 쿼리문입니다. 즉, 파이썬에서의 if문과 비슷한 역할을 합니다.
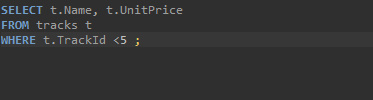
위와 같이 WHERE에 t.TrackID <5 ;를 주었다고 해보자, 이는 tracks테이블의 TrackID가 5보다 작은 조건을 말한다. 즉 5보다 작은것만을 가져오는것으로 필터를 넣어준 것이다. 결과값을보면
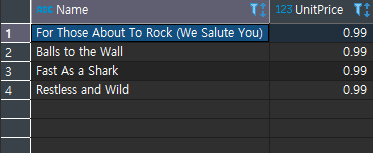
필터가 적용되어 출력되는것을 알 수 있다.
이 외에도 여러가지가 있다.
- 특정 값을 제외한 데이터 찾기 : <>
- 문자열에서 특정값과 비슷한 값들을 필터할때 : LIKE "%특정 문자열%"
- 리스트 값과 일치하는 데이터를 필터할 때 : IN
- 값이 없는 NULL과 같은 경우를 찾을때 : IS
- 값이 없는 경우를 제외할때 : NOT
위의 경우의 수를 순서대로 아래에 출력해 보겠다.
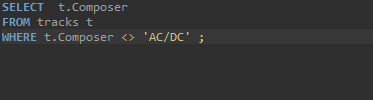
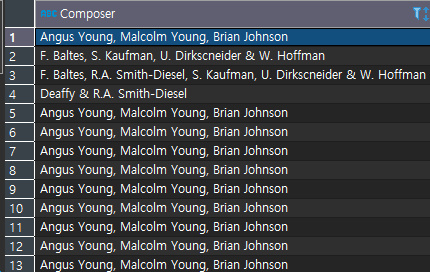

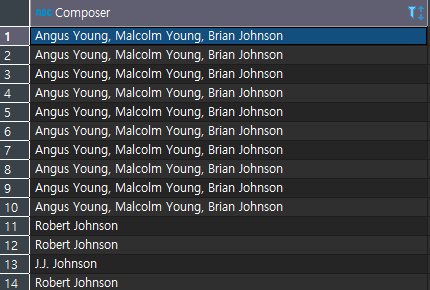
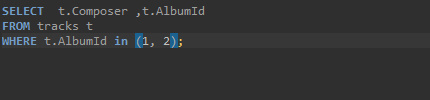
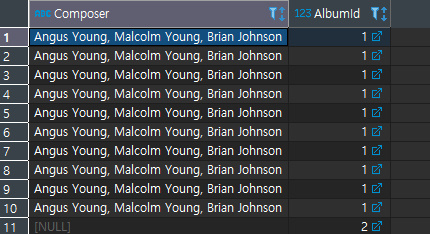
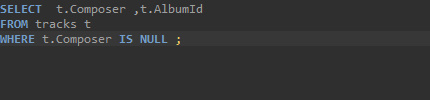

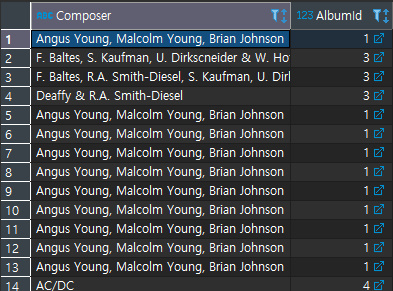
ORDER BY
- 이것은 돌려받은 데이터 결과를 어떻게 정렬할것인가 에 대한 것이며, 기본정렬은 오름차순이다. 만약 내림 차순을 하고자 한다면 특성뒤에 DESC를 넣어주면된다.(DESC = descending)
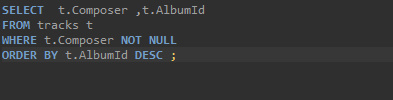

LIMIT
- 돌려받는 데이터 결과 갯수를 정할 수 있다. 쿼리문을 사용할 때는 마지막에 추가를 해야 한다.
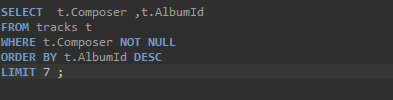

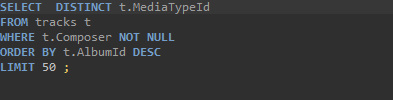
DISTINCT
-
유니크한 값들을 받고 싶을 때에는 SELECT뒤에 붙여 사용할 수 있다.

-
특성이 여러개일때 똑같이 DISTINCT를 붙이면 어떻게 될까

이런식의 구조를 가지고 있을때에는
특성_1, 특성_2, 특성_3의 유니크한 조합 값들을 선택한다.
JOIN
- join은 두개 의 테이블을 합칠 때사용하는 것이다.
- 종류로는 INNER JOIN(=JOIN), LEFT OUTER JOIN, RIGHT OUTER JOIN, OUTER JOIN이렇게 구분되어 있다.
INNER JOIN
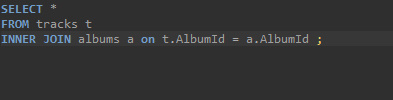
-
INNER JOIN 테이블_2 ON 테이블_1 특성 = 테이블_2 특성
-
이때 주의할 것은같은 특성끼리 합쳐져야 하며 이때 같은특성은 같은 KEY를 뜻한다.
-
합쳐질때 INNER JOIN이므로 둘의 특성의 공통된것들이 합쳐진것이다(교집합).
-
그렇다면 OUTER JOIN은?? OUTER JOIN을 하면 합집합 즉, 전체를 JOIN해 준다.
-
LEFT JOIN은 왼쪽에 있는 것과 같은것을 오른쪽 테이블에서 가져와 JOIN해 준다.
