💡 웹 스크레핑/ 크롤링 소개
웹에서 특정 정보를 얻고 싶을 때 보통은 포털사이트에서 검색을 하게 된다.
그리고 검색된 정보를 바탕으로 해결을 하게된다.
하지만 인간이 아닌 기계가 정보를 얻을 때에는 시간이 더 단축되기도 한다.
간단한 정보모으기 등도 자동화를 통해 굳이 사람이 하지 않아도 된다.
웹 크롤링이란 웹을 돌아다니면서 정보를 수집하는 행위를 뜻한다. 크롤링을
번역해 보자면 '기어다니다' 라는 뜻을 가지고 있다. 웹에서 사이트들을 방문하며
필요한 정보를 수집하는 것이다.
이와 비슷한 용어로 웹 스크레이핑이라는 것이 있다. 크롤링과 비슷하면서도 살짝 다르게
사용되는 용어이다. 크롤링은 자동화에 초점이 맞춰져 있어 알아서 돌아가게 하는 것이며,
스크레핑은 특정 정보를 가져오는 것이 목적이라면 크롤링은 주로 인터넷에 있는 사이트들을
인덱싱하는 목적을 두고 있다.
이렇게 차이점이 존재하지만 정보수집을 목적으로 지니고 있다는 면에서 비슷하다고 볼 수 있다.
💡 Practice
구직사이트 중 하나인 '사람인'에서 '데이터분석'을 검색했을때 나오는 구인공고문을 스크래핑해오는 것을 연습해 보았습니다. 또한, 추가적으로 검색어를 다르게 입력하여도 해당 검색어로 구직을 공고문을 스크랩 할 수 있습니다.
from urllib.request import urlopen # url을 html로 열기위함.
from urllib.parse import quote_plus # 한글인식을 위함.
from bs4 import BeautifulSoup
Base_url = 'https://www.saramin.co.kr/zf_user/search?search_area=main&search_done=y&search_optional_item=n&searchType=search&searchword='
Plus_url = input('검색어를 입력하세요: ')
url = Base_url + quote_plus(Plus_url) # 한글을 검색하게 되면 urllib.parse.quote_plus을 앞에 붙여줘야한다.
html = urlopen(url).read()
soup = BeautifulSoup(html, 'html.parser')
title = soup.select('.job_tit a')
for i in title:
print(i['title'])
print('https://www.saramin.co.kr' + i['href'])
print()- 검색어를 받아서 해당 검색어에 따른 구인공고문을 스크랩 하기 위해서 input을 통해 url2개를 만들어 합쳐 주었다.
- urlopen을 통해서 만들어준 url을 html로 변경해 주었고 변수 html에 저장을 하였다.
- 기본적이면서 빠른 html.parser를 사용하여 BeautifulSoup정의해주었다.
- select로 진행을 하였기 때문에 클래스를 뜻하는 .을 사용하여 job_tit라는 클래스 안에있는 a태그를 title로 지정해 주었다.
- 반복문을 통해 a태그 안에 있는 title을 가져와 주었다. 이것이 공고문 문장이다.
- 뒤에 있는것이 해당 공고문의 상세페이지 url을 접속하기 위한 것이다.
<select -> find_all>
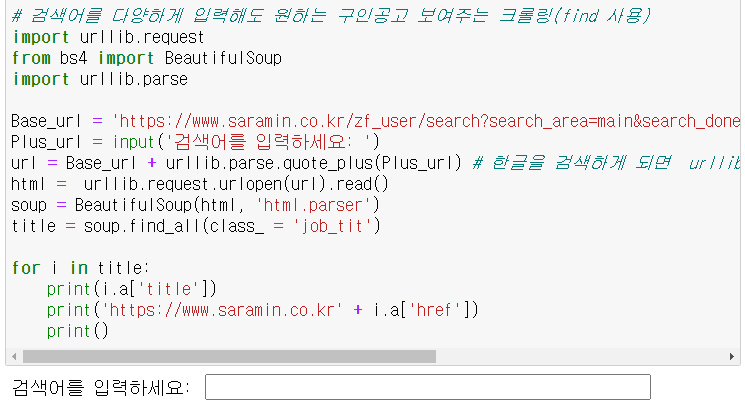
from urllib.request import urlopen # url을 html로 열기위함.
from urllib.parse import quote_plus # 한글인식을 위함.
from bs4 import BeautifulSoup
Base_url = 'https://www.saramin.co.kr/zf_user/search?search_area=main&search_done=y&search_optional_item=n&searchType=search&searchword='
Plus_url = input('검색어를 입력하세요: ')
url = Base_url + quote_plus(Plus_url) # 한글을 검색하게 되면 urllib.parse.quote_plus을 앞에 붙여줘야한다.
html = urlopen(url).read()
soup = BeautifulSoup(html, 'html.parser')
title = soup.find_all(class_ = 'job_tit')
for i in title:
print(i.a['title'])
print('https://www.saramin.co.kr' + i.a['href'])
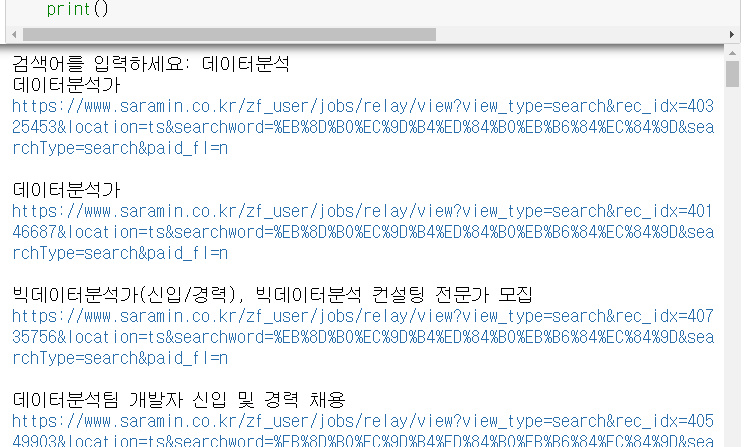
print()출력 모습

문제를해결하는도구로서의"데이터"