
문서들간의 유사도를 측정하는 방법에 대해 알아보겠습니다.
코사인 유사도(Cosine Similarity)
코사인 유사도는 가장 많이 쓰이는 유사도 측정방법입니다.
수식으로 표현하면 아래와 같습니다.
이를 쉽게 그림으로 아래에서 표현해 보겠습니다.
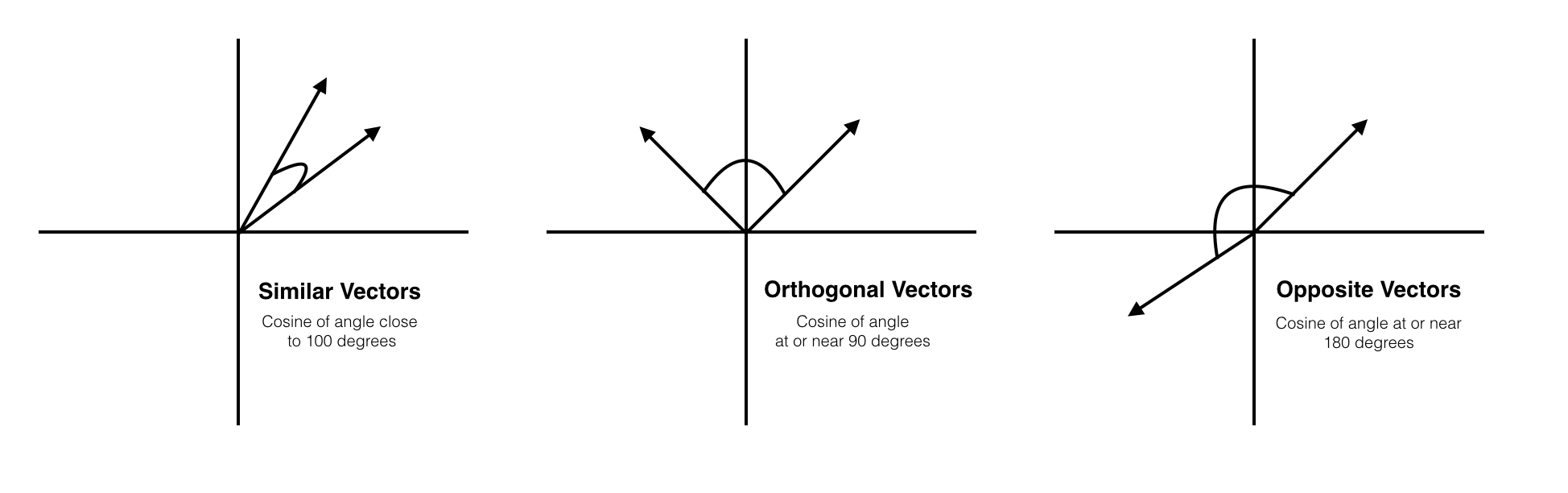
이그림을 풀이해 보면 화살표끝이 각 문서의 벡터값이라고 보면됩니다. 원점(0,0)을 기준으로 각 문서들의 벡터와 연결해 보면 그 사이의 코사인 각도가 나오게 됩니다.
첫번째 부터 보면 각다고 낮습니다. 이런경우 유사도가 높다고 할 수 있습니다. 이때를 1이라고 합니다. 그리고 두번째 90도의 각도를 이룰때는 0, 마지막 반대를 이룰때는 -1입니다. 이는 상관관계에서 나왔듯이 1이 가장관련이 있는것이 0은 관련이 없고 -1은 반대라고 보면됩니다.
- 완전히 같을경우 1
- 90도 각도를 이룰경우 0
- 반대방향을 이루면 -1
이제 코드로 넘어가서 NearestNeighbor (K-NN, K-최근접 이웃)을 이용하여 가장 가까운 상위k개의 근접한 데이터를 찾아서 k개 데이터 유사성을 기반으로 추정하거나 분류하는 예측분석에 사용할 수 있다.
먼저 알고리즘으로 학습을 진행한다
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(n_neighbors = 5, algorithm = 'kd_tree')
nn.fit(dtm_tfidf_amazon) # 아마존 리뷰데이터에 TF-IDF를 적용한 데이터를 학습특정인덱스의 문서와 가장 가까운 문서5개의 거리와 인덱스를 알아보자
nn.kneighbors([dtm_tfidf_amazon.iloc[2]])
>>>
(array([[0. , 0.64660432, 0.73047367, 0.76161463, 0.76161463]]),
array([[ 2, 7278, 6021, 1528, 4947]]))이렇게 찾아지는것을 볼 수 있습니다
문서 검색
Amazon Review의 Sample을 가져와서 문서검색에 사용해 보자
# 출처 : https://www.amazon.com/Samples/product-reviews/B000001HZ8?reviewerType=all_reviews
sample_review = ["""in 1989, I managed a crummy bicycle shop, "Full Cycle" in Boulder, Colorado.
The Samples had just recorded this album and they played most nights, at "Tulagi's" - a bar on 13th street.
They told me they had been so broke and hungry, that they lived on the free samples at the local supermarkets - thus, the name.
i used to fix their bikes for free, and even feed them, but they won't remember.
That Sean Kelly is a gifted songwriter and singer."""]new = tfidf_vect.transform(sample_review) # TF-IDF로 벡터화히기
nn.kneighbors(new.todense())
>>>
(array([[0.69016304, 0.81838594, 0.83745037, 0.85257729, 0.85257729]]),
array([[10035, 2770, 1882, 9373, 3468]]))# 가장 가깝게 나온문서중 하나를 확인해 보자
df['reviews.text'][10035]
>>>
Doesn't get easier than this. Good products shipped to my office free, in two days:)
문제를해결하는도구로서의"데이터"