.png)
SW과정 머신러닝 1020(11)
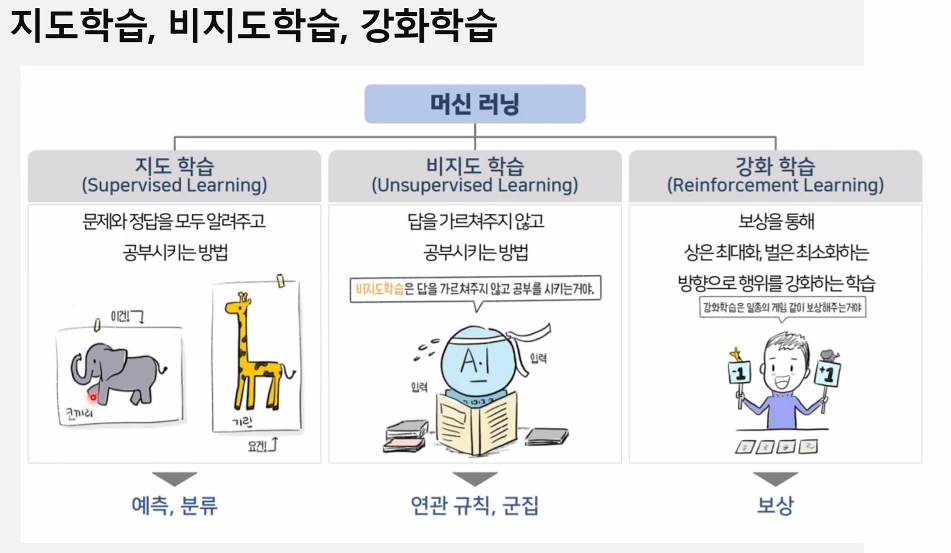
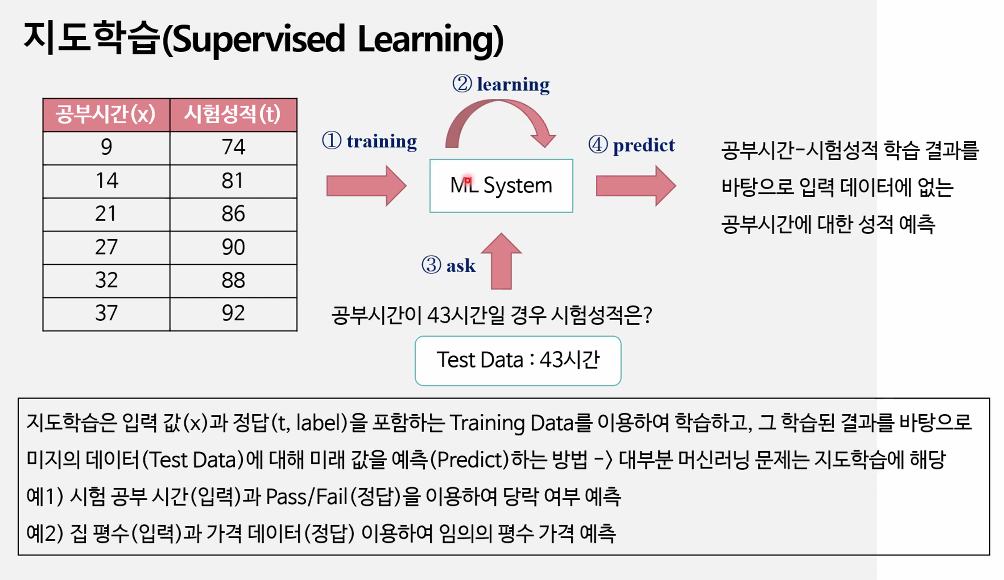
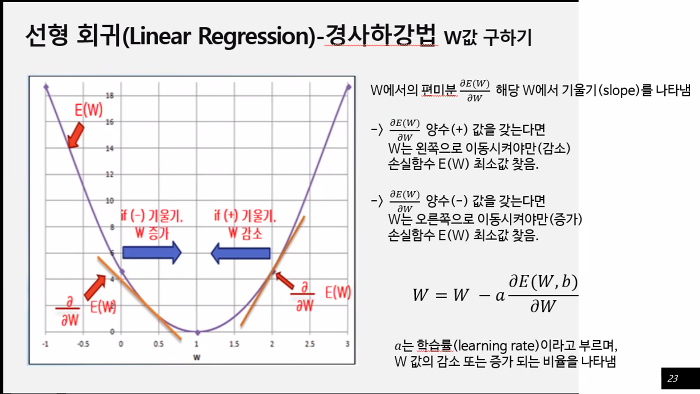
1. 머신러닝


Visual Studio Tools 설치(Tools for Visual Studio 2019)
Visual Studio 2019용 Build Tools
int32 vs unsignint 32

import numpy as np
array1 = np.array([1,2,3]) #np.array로 nd array를 만들 수 있음
type(array1)
array1.shape
array2 = np.array([[1,2,3],[2,3,4]])
array2
array2.shape
array3 = np.array([[[1,2,3],[2,3,4]],[[1,2,3],[2,3,4]]])
array3.shape
array1.ndim
array2.ndim
array3.ndim
array1.dtype
list2=[1,2, 'test']
array2 = np.array(list2)
array2.dtype
array_int = np.array([1,2,3])
array_float = array_int.astype('float64')
array_int.dtype
array_float.dtype
np.arange(10)
np.zeros(3)
np.zeros((3,3,3))
np.zeros((3,3,3),dtype='int32')
np.ones((3,3,3),dtype='int32')
array1 = np.arange(10)
array1
array1.reshape(1,10) #행안에 갯수가 맞아야함, 5,2 or 2,5 or 10,1
array1 = array1.reshape(-1,5) #5개의 열을 만들고 나머지를 출력해주는 것
array1.tolist()
array1 = np.arange(1,10)
array1
array1[2]
array1[-2]
array2 = array1.reshape(3,3)
array2
array2[1,1] #indexing, indexing(몇번째 리스트, 리스트 안에 몇번째)
array2[0:2,1:2]
org_array = np.array([3,1,9,5])
org_array
np.sort(org_array)[::-1] #[::-1] 이 코드는 내림차순 정렬
org_array.sort()
A = np.array([[1,2,3],[4,5,6]])
B = np.array([[7,8],[9,10],[11,12]])
np.dot(A,B)
np.dot(B,A)
A.T #pandas의 transform
2. Sklearn(Scikit-learn(사이킷 런))
import sklearn
sklearn.__version__ #Label 정답값을 뜻함
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
iris = load_iris()
iris_data = iris.data
iris_df=pd.DataFrame(data=iris.data,columns=iris.feature_names)
iris_df.head(2)
iris_df['label'] = iris.target
iris_df.head(2) #0 setosa 1 versicolor 2 virginica
iris_df.info() #기본 전처리를 끝낸 상태라서 null값이 없다.
#이걸 다 학습에 쓰면 어떤 일이 발생할까? 시험지랑 답지를 다 주고 공부를 시키는 것과 같음 그래서 정답이 100점이 나옴
X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target, test_size=0.2, random_state=11)
#x값은 문제들을 뜻함, y값은 label을 의미함
y_test.shape
dt_clf = DecisionTreeClassifier(random_state=11)
dt_clf.fit(X_train, y_train) #학습시키기
pred = dt_clf.predict(X_test) #검증하기(예측하기)
from sklearn.metrics import accuracy_score #얼마나 많이 맞췄는지 확인하기
accuracy_score(y_test, pred) #0.9333 93% 확률
DataEngineer Lee.