Annotation
@Entity
DB 테이블에 대응하는 하나의 클래스. JPA가 관리한다.
기본 생성자가 필수(파라미터가 없는 public 또는 protected)
@Table
엔티티와 매핑 할 테이블 지정
@Id
데이터베이스 PK와 매핑
@GeneratedValue
PK를 자동으로 생성해주는 애노테이션
(strategy = GenerationType.IDENTITY) - 데이터베이스에 위임
(strategy = GenerationType.SEQUENCE) - 데이터베이스 시퀀스 오브젝트 사용
(strategy = GenerationType.TABLE) - 키 생성용 테이블 사용
(strategy = GenerationType.AUTO)
@Column
객체의 필드를 테이블의 컬럼과 매핑
@JoinColumn
외래키를 매핑할 때 사용
@Embedded
값 타입을 사용하는 곳에 표시
@Embeddable
값 타입을 정의하는 곳에 표시
@Enumerated(EnumType.STRING)
자바 enum 타입을 매핑할 때 사용
@Temporal
날짜 타입(java.util.Date, java.util.Calendar)을 매핑할 때 사용
JPA에서 가장 중요한 2가지
- 객체와 관계형 데이터베이스 매핑하기
- 영속성 컨텍스트
EntityManager
JPA의 모든 동작은 엔티티 매니저를 통해서 이루어진다. 엔티티 매니저는 내부에 데이터소스를 가지고 있고, 데이터베이스에 접근할 수 있다.
EntityManager를 사용할 때 여러 쓰레드가 동시에 접근하면 동시성 문제가 발생한다. 쓰레드 간에는 EntityManager를 공유해서는 안된다.
JPA의 모든 데이터 변경은 트랜잭션 안에서 실행
@PersistenceContext
private EntityManager em;
@Autowired
private EntityManager em;@PersistenceContext를 통해 주입해야 한다.
You shouldn't use @Autowired. "@PersistenceContext" takes care to create a unique EntityManager for every thread.
Entity
DB 테이블에 대응하는 하나의 클래스
@Entity 가 붙은 클래스는 JPA가 관리하며, DB의 테이블과 자바 클래스가 매핑이 된다.
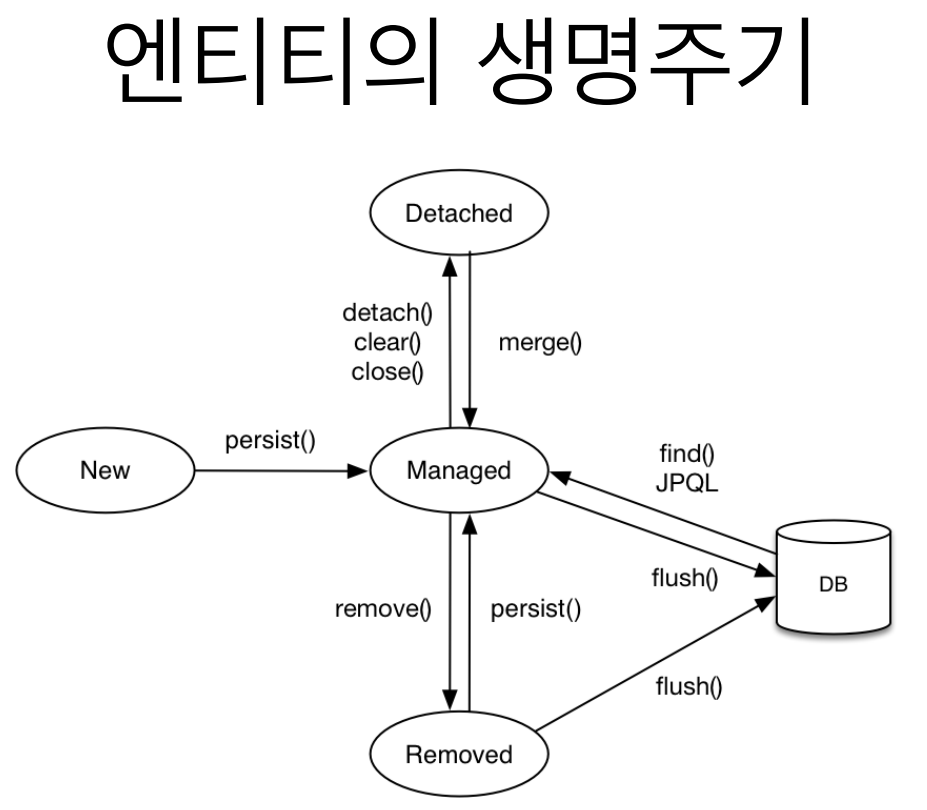
엔티티의 생명주기
- 비영속 (new/transient)
영속성 컨텍스트와 전혀 관계가 없는 새로운 상태 - 영속 (managed)
영속성 컨텍스트에 관리되는 상태 - 준영속 (detached)
영속성 컨텍스트에 저장되었다가 분리된 상태. DB에 한번 저장되었지만(=id값이 존재) 영속성 컨텍스트가 관리하지 않는 상태. - 삭제 (removed)
삭제된 상태
영속성 컨텍스트
엔티티를 영구 저장하는 환경
엔티티 매니저를 통해서 영속성 컨텍스트에 접근
__특징
- 1차 캐시 - 캐시에서 먼저 조회, 없으면 DB에서 조회
- 동일성(identity) 보장
- 트랜잭션을 지원하는 쓰기 지연(transactional write-behind) - 커밋하는 순간 DB에 INSERT SQL을 보낸다.
- 변경 감지(Dirty Checking) - 값만 바꿔도 updateQuery 날려준다.
- 지연 로딩(Lazy Loading)
Fulsh
영속성 컨텍스트의 변경내용을 데이터베이스에 반영
쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송
- 영속성 컨텍스트를 비우지 않음
- 영속성 컨텍스트의 변경내용을 데이터베이스에 동기화
- 트랜잭션이라는 작업 단위가 중요 -> 커밋 직전에만 동기화 하면 됨
플러시 하는 방법
- em.flush() - 직접 호출
- 트랜잭션 커밋 - 플러시 자동 호출
- JPQL 쿼리 실행 - 플러시 자동 호출
엔티티 매핑
- 객체와 테이블 매핑: @Entity, @Table
- 필드와 컬럼 매핑: @Column
- 기본 키 매핑: @Id, @GeneratedValue
- 연관관계 매핑: @ManyToOne,@JoinColumn
- 멤버변수로 내가 정의한 클래스가 있을 떄: @Embedded, @Embeddable
연관관계 매핑
객체와 테이블이 관계를 맺는 차이
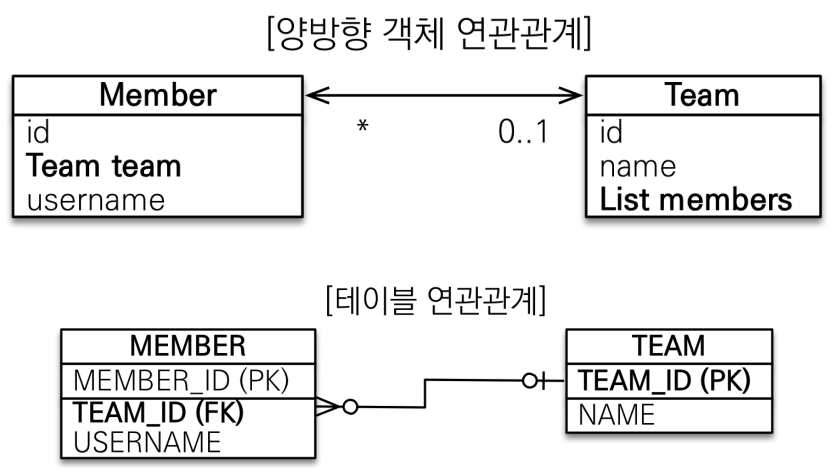
테이블은 외래 키로 조인을 사용해서 연관된 테이블을 찾는다.
객체는 참조를 사용해서 연관된 객체를 찾는다.
- 객체 연관관계 = 2개
- 회원 -> 팀 연관관계 1개(단방향)
- 팀 -> 회원 연관관계 1개(단방향) - 테이블 연관관계 = 1개
- 회원 <-> 팀의 연관관계 1개(양방향)
객체의 양방향 관계는 사실 서로 다른 단뱡향 관계 2개다.
테이블은 외래 키 하나로 두 테이블의 연관관계를 관리
양방향 연관관계
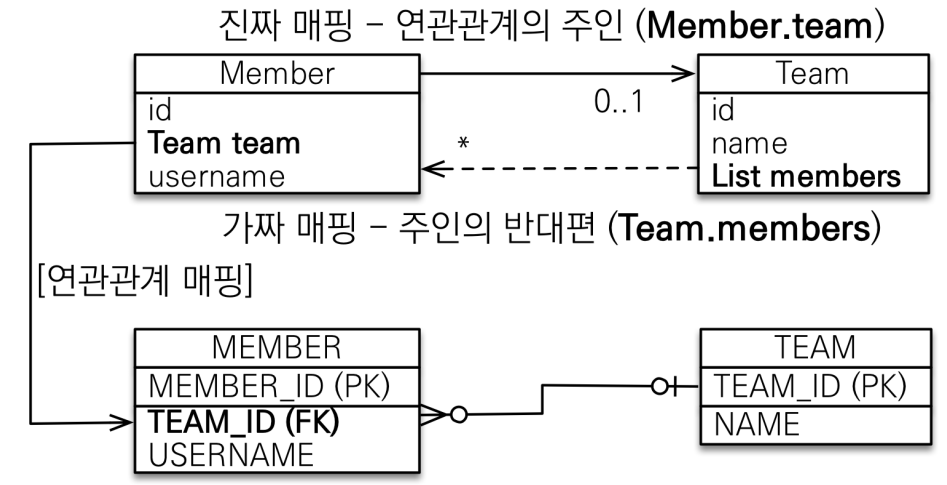
연관관계의 주인
외래 키가 있는 곳이 주인
외래키가 무조건 __N(多)
예시1-Team:Member=1:N
@Entity
public class Member {
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "TEAM_ID")
private Team team;
}
@Entity
public class Team {
@OneToMany(mappedBy = "team")
List<Member> members = new ArrayList<Member>();
}
-----------------------------------------------------------
예시2-Member:Order=1:N
@Entity
public class Member {
@OneToMany(mappedBy = "member")
private List<Order> orders = new ArrayList<>();
}
@Entity
public class Order {
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn
private Member member;
}__🔅양방향 연관관계에서 필수로 해야되는 것🔆
1. 연관관계 주인 설정 -> @OneToMany(mappedBy = "~")
2. @~ToOne -> fetch = FetchType.LAZY
3. 연관관계 편의 메서드
@JoinColumn 이해
컬럼명을 직접 지정할 게 아니면 생략 가능
- name 속성 = 테이블에 들어갈 멤버변수의 컬럼명을 지정. 다시 말해 Member 엔티티의 team 필드를 어떤 컬럼명으로 Member 테이블에 설정할 것인지를 나타내주는 것. 위의 예시에선 Member테이블에 TEAM_ID라는 컬럼명이 정의된다.
- referencedColumnName 속성 = Join할 컬럼명을 지정. 보통 생략한다. 그 이유는 referencedColumnName을 생략하면 대상 테이블의 PK로 자동 지정되기 때문이다.
연관관계 편의 메서드
연관관계 주인에 값을 입력해야 SQL Table에 값이 입력된다.
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
member.setTeam(team); <-연관관계 주인에 값 설정
team.getMembers().add(member); <-SQL Table에는 영향이 없음
em.persist(member);순수 객체 상태를 고려해서 항상 양쪽에 값을 설정하자 => 연관관계 편의 메서드
다대다 [N:M]
문제
관계형 데이터베이스는 정규화된 테이블 2개로 다대다 관계를 표현할 수 없음
다대다를 쓰면 JPA가 연결테이블을 알아서 만들지만 다른 데이터가 들어올 수 없음 -> 하지만 다른 데이터가 들어올일이 생김
연결테이블이 숨겨져 있기 때문에 예상하지 못한 쿼리들이 나간다.
해결
반드시 연결테이블을 추가해서 일대다, 다대일 관계로 풀어내야함
일대일 [1:1]
연관관계 주인이 외래키를 가짐
연관관계의 주인을 누구로 할 것인가?
엑세스를 많이 할 곳 or N(多)이 될 수도 있는 곳
즉시 로딩과 지연 로딩
모든 연관관계는 지연로딩으로 설정
실무에서 즉시 로딩 사용 절대X
즉시 로딩은 JPQL에서 N+1 문제를 일으킨다. 조인이 많아지면 예상하지 못한 쿼리가 나간다.
지연 로딩 = 우선 프록시 객체를 만들고 실제 값이 필요할 때 DB에 쿼리를 날리는 방식
@~ToOne(OneToOne, ManyToOne) 관계는 기본이 즉시로딩 -> LAZY로 설정
@OneToMany, @ManyToMany는 기본이 지연 로딩
@ManyToOne(fetch = FetchType.LAZY)상속관계 매핑
@Inheritance(strategy=InheritanceType.XXX)
- JOINED: 조인 전략
- SINGLE_TABLE: 단일 테이블 전략
@DiscriminatorColumn(name = "dtype")
dtype이라는 컬럼명이 생긴다. 부모에 있다.
@DiscriminatorValue("M")
dtype 컬럼에 들어가는 기본값은 엔티티이름(=클래스이름)인데 M으로 바꿀 수 있다.
데이터베이스 스키마 자동 생성
애플리케이션 로딩 시점에 자동으로 테이블 생성 -> 내가 DB에 테이블을 만들 필요가 없다.
옵션
- create : 기존테이블 삭제 후 다시 생성 (DROP + CREATE)
- create-drop : create와 같으나 종료시점에 테이블 DROP
- update : 변경분만 반영(운영DB에는 사용하면 안됨)
- validate : 엔티티와 테이블이 정상 매핑되었는지만 확인
- none : 사용X
__운영 서버에서는 절대 create, create-drop, update 사용하면 안된다. - 개발 초기 단계는 create 또는 update
- 테스트 서버는 update 또는 validate
- 스테이징과 운영 서버는 validate 또는 none
연관관계 엔티티 옵션
cascade=CascadeType.XXXXX
엔티티를 영속화할 때 연관된 엔티티도 함께 영속화하는 편리함을 제공
오직 하나의 부모가 자식들을 관리할 때 쓰면 유용
- ALL: 모두 적용
- PERSIST: 영속만 같이
- REMOVE: 삭제 - 엔티티를 제거할 때, 연관된 엔티티도 모두 제거
orphanRemoval = true
부모 엔티티와 연관관계가 끊어진 자식 엔티티 를 자동으로 삭제
참조하는 곳이 하나일 때 사용해야함!
기본적인 CRUD
저장
em.persist();
변경
변경감지 사용
트랜잭션 안에서 엔티티를 다시 조회, 변경할 값 선택 -> 트랜잭션 커밋 시점에 변경 감지
삭제
em.remove();
단건 조회
em.find(em.find(Member.class, id);
전체 조회
em.createQuery("select m from Member m", Member.class)
.getResultList();
카운트
em.createQuery("select count (m) from Member m", Long.class)
.getSingleResult();
JPQL
특징
- SQL을 추상화한 객체 지향 쿼리 언어. 특정 데이터베이스 SQL에 의존X
- 엔티티 객체를 대상으로 쿼리 (vs SQL은 데이터베이스 테이블을 대상으로 쿼리)
- JPQL은 결국 SQL로 변환된다.
em.createQuery의 타입 - TypeQuery: 반환 타입이 명확할 때 사용
- Query: 반환 타입이 명확하지 않을 때 사용
__결과 조회 API - query.getResultList(): 결과가 하나 이상일 때, 리스트 반환
- query.getSingleResult(): 결과가 정확히 하나, 단일 객체 반환
페치 조인(fetch join)
- JPQL에서 성능 최적화를 위해 제공하는 기능
- 연관된 엔티티나 컬렉션을 SQL 한 번에 함께 조회하는 기능
- join fetch 명령어 사용 (LEFT OUTER JOIN 사용)
- 왜 사용하는가? 조회할 때 지연로딩으로 설정되어 있으면, 실제 필요로하는 시점(=조회하는 시점)에 쿼리를 날린다. 그러다 보면 쿼리가 하나씩 나가면서 N+1문제가 발생하고 성능이 낮아진다.
[JPQL]
select m from Member m join fetch m.team
->변환
[SQL]
SELECT M.*, T.* FROM MEMBER M INNER JOIN TEAM T ON M.TEAM_ID=T.ID페치 조인의 한계
- 페치 조인 대상에는 별칭을 줄 수 없다.
- 둘 이상의 컬렉션은 페치 조인 할 수 없다.
- 컬렉션을 페치 조인하면 페이징 API(setFirstResult, setMaxResults)를 사용할 수 없다.
