CPython 10장, 11장
10장. 병렬성과 동시성
- OS는 병렬성과 동시성을 활용해 multitasking 을 처리함
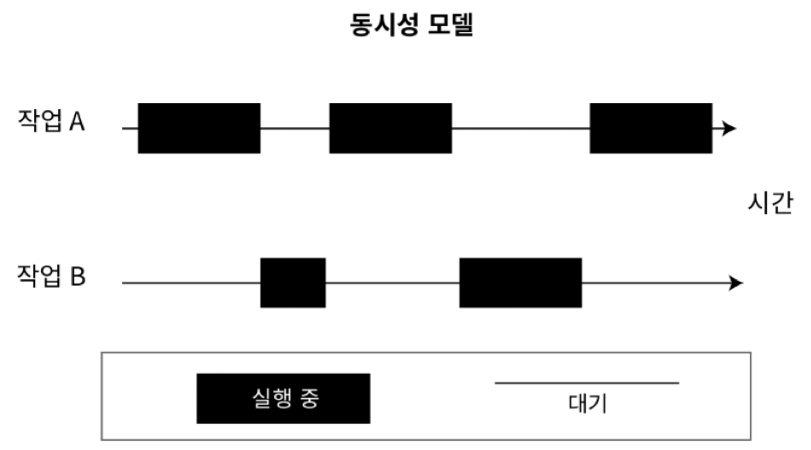
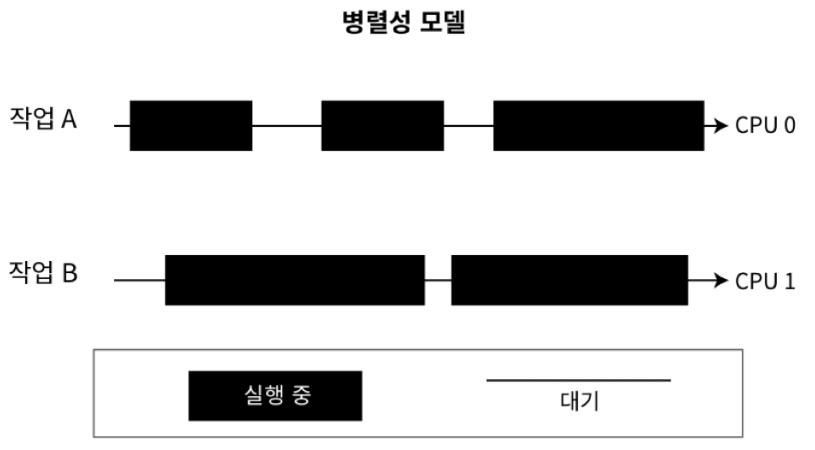
병렬성 활용: CPU 와 같은 연산 유닛이 다수 필요동시성 사용: 유휴 상태의 리소스가 자원을 점유하고 있지 않도록 자원 스케쥴링
10.1 병렬성과 동시성 모델

10.2 프로세스의 구조
[POSIX Process가 OS에 등록된 최소한의 Property]
- 제어 터미널
- 현재 작업 디렉터리
- 유효 그룹 아이디 & 사용자 아이디
- file descriptor & file mode 생성 mask
- process group id & process id
- 실제 group id & user id
- root directory
[Process 실행 시 필요한 추가 데이터]
- 실행 중인 명령이나 명령을 실행하는 데 필요한 다른 데이터를 보관하는 Register
- Program Sequece 의 어떤 명령을 실행 중인지 저장하는 Program Counter
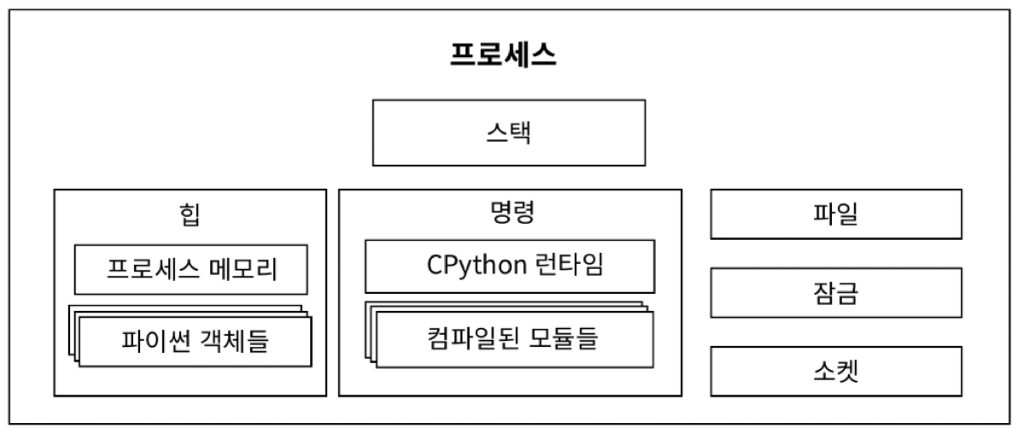
- CPython process 는 compile 된 CPython interpreter 와 module 로 구성
- module 을 runtime 에 불러들여서 CPython 평가 루프를 통해 명령으로 변환
[Process 명령 병렬 수행]
1. 다른 process fork
2. thread 스폰
10.3 Multiprocess 를 활용한 병렬 실행
Process fork: 실행 중인 Process 가 호출할 수 있는 저수준 운영 체제 API
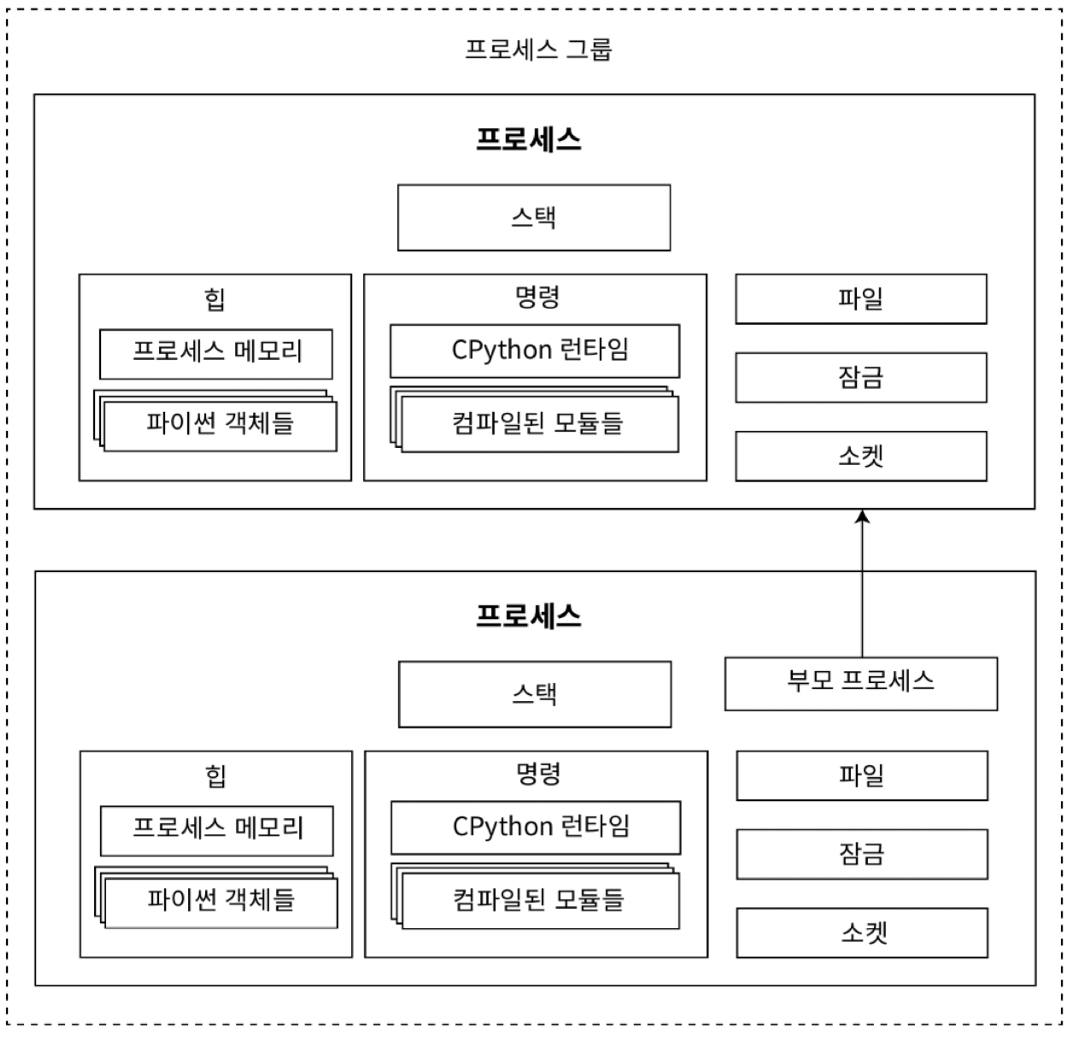
- parent process 는 child process 가 완료되기 전 별도의 exit code 와 함께 종료
- OS 는 관련된 process 를 쉽게 제어하기 위해 process group 에 자식 process 를 추가
[multi process 의 단점]
- child process 가 parent process 의 완벽한 복제본
ex) CPython 의 경우
- process fork > 두 개 이상의 CPython interpreter 실행
- interpreter 가 따로 module & library 를 부르면서 상당한 overheaad 발생
fork 시 쓰는 overhead 보다 더 큰 작업일 경우 쓰는 것이 좋음
- 자식 프로세스는 부모의 heap 을 읽어들일 수 있지만,
- 부모 프로세스에 정보를 다시 보낼 때는 IPC를 활용
10.3.3 multiprocessing package
- CPython 은 간편한 multiprocessor 기반 병렬 실행 API 제공
- 이 API 는 OS의 process fork API 에 기반
10.3.4 연관된 소스 파일 목록

10.3.5 Process 스폰 & fork
+) Spawn과 fork의 차이
spawn은 좀 더 최소한의 코드만 담아서 실행하는 개념에 가깝다면,
fork는 완전한 자기복제의 의미가 가깝다.
[multiprocessing package 의 3가지 병렬 process 시작 방법]
- interpreter fork (POSIX 전용)
- 새 interpreter process 스폰 (POSIX/Window)
- fork server 실행 후 원하는 만큼 process fork (POSIX)
- 자식 프로세스 생성 및 직렬화 과정 :
Lib/multiprocessing/popen_spawn_posix.py에서 확인 가능
10.3.6 queue 와 semaphore 를 사용해 데이터 교환 (부모 <-> 자식)
semaphore
- 자원이 잡겼거나 대기 중이거나 잠기지 않았다는 신호를 보내는 방법
Mocules/_multiprocessing/semaphore.c에서 찾을 수 있음
queue
- 여러 process 간 작은 데이터를 주고 받기 좋은 방법
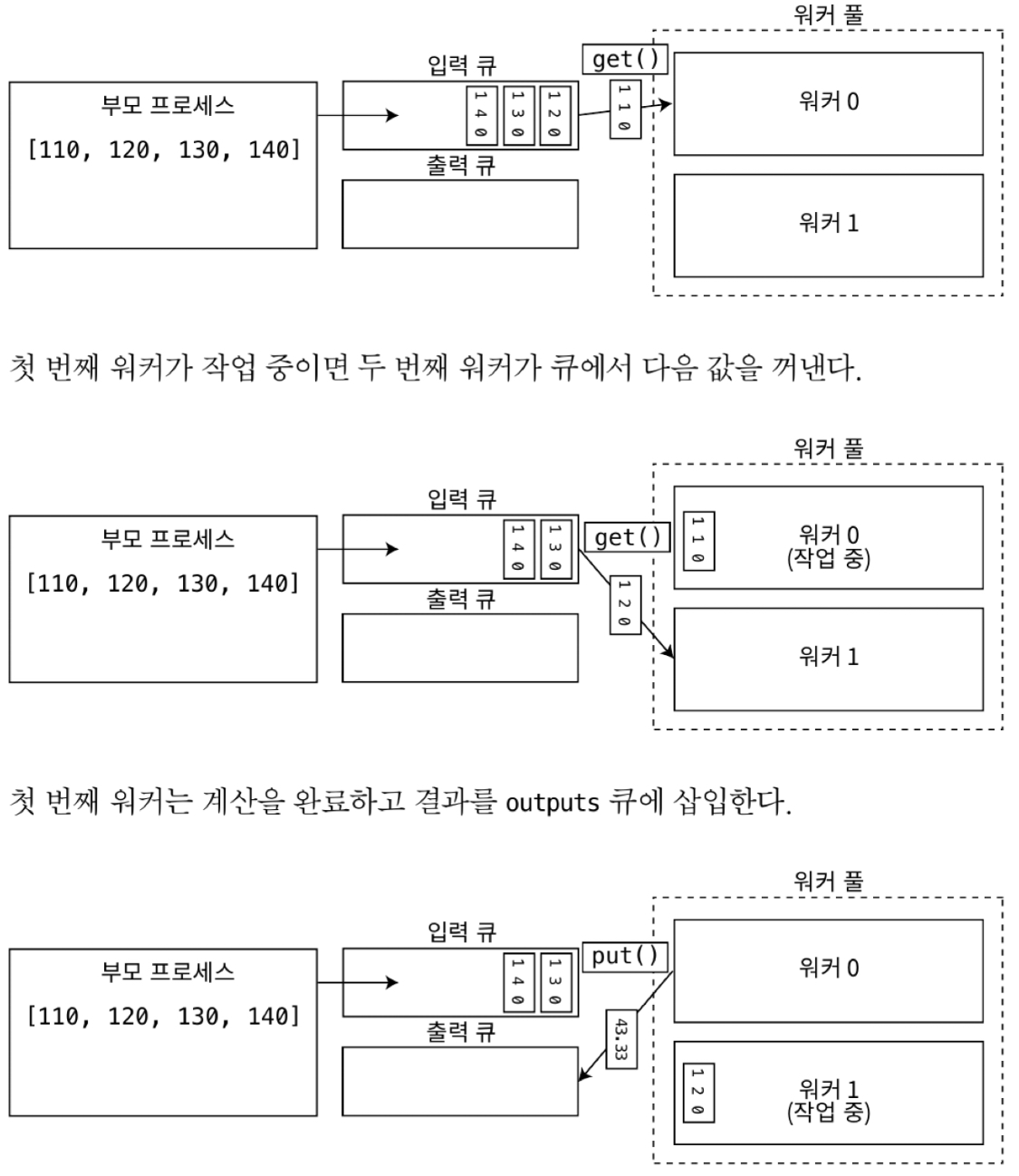
pipe (file)
- pipe 를 instance 화 하면 부모 쪽 연결과 자식 쪽 연결, 두 개의 연결이 반환
+) file 을 하나 만들어서 거기에 썼다 지웠다
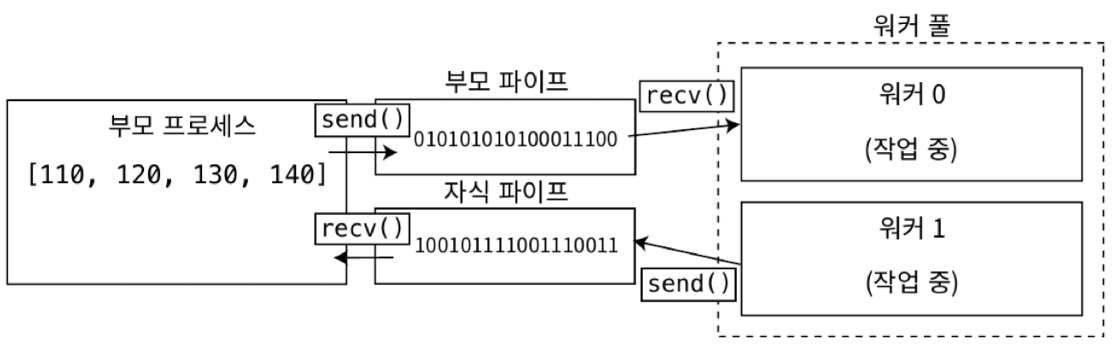
+) The pipe() function shall create a pipe and place two file descriptors, one each into the arguments fildes[0] and fildes[1], that refer to the open file descriptions for the read and write ends of the pipe
- 여러 개의 프로세스가 하나의 pipe 에 동시에 쓰거나 읽지 못하게 하기 위해 semaphore 사용이 필요
10.3.7 process 간 공유 상태 (자식 <-> 자식)
- 고성능 공유 메모리 API : 공유 메모리 맵 & 공유 C 타입
- 유연한 서버 프로세스 API : Manager class 를 통해 복잡한 타입 지원
10.4 MultiThreading
[CPython Threading]
1. pthreads : POSIX thread (linux, macOS)
2. nt thread : NT thread (window)
- subroutine stack
- memory heap
- os file 잠금, sockeet 에 접근할 수 있는 권한 등
- 단일 프로세스의 가장 큰 제약 >
OS가 실행 파일마다 하나의 Program Counter 를 가짐 - 이 문제를 해결하기 위해
Thread로 분기
- 각 Thread 는
다른 PC를 가지지만,host process 와 resource 공유 - 각 Thread 는
별도의 call stack을 가지고 있어 다른 함수 실행 가능 - Thread 가 같은 메모리 공간을 읽고 쓸 수 있기 때문에 충돌이 일어날 수도 있음
- 이를 해결하기 위해 메모리 접근 전 잠겨있는지 확인하는 Thread 안정성이 필요
10.4.1 GIL
- CPython 의 Thread 는 C API 를 기반으로 실행하지만 결국 Python 기반
- 모든 Python thread 는 평가 loop 를 통해 python bytecode 를 실행
- Python 평가 루프는 thread safe 하지 않음
- garbage collector 를 비롯해 interpreter 상태를 구성하는 많은 부분은 전역적이고 공유 상태
[GIL(Global Interpreter Lock) 구현]
- frame 평가 루프에서 명령 코드를 실행 전, Thread 는 GIL 을 얻고 명령 코드를 실행한 후 GIL 해제
- 장점 : thread safe 제공
- 단점 : 긴 시간이 걸리는 명령이 실행 중이면 다른 thread 들은 그 시간동안 GIL 이 해제되기만을 기다림
_PyEval_EvalFameDefault():take_gil(),drop_gil()- 특정한 frame 실행 작업이 GIL 을 영원히 보유하는 것을 막기 위해 평가 루프 상태에서는
gil_drop_request라는 flag 가 있음
10.4.2 연관된 소스 파일 목록
10.4.3 Python Thread 시작하기
- MultiThread 는 단일 Thread 보다 10배 정도 빠르게 실행
- multithreading 의 overhead 는 multiprocessing 을 사용한 구현보다 50~60% 빠르게 실행
[GIL 예외 처리 매크로 세트]
- HTTP 요청
- local HW 와 상호작용
- data encryption
- file R/W
등에서 300군데 이상 사용
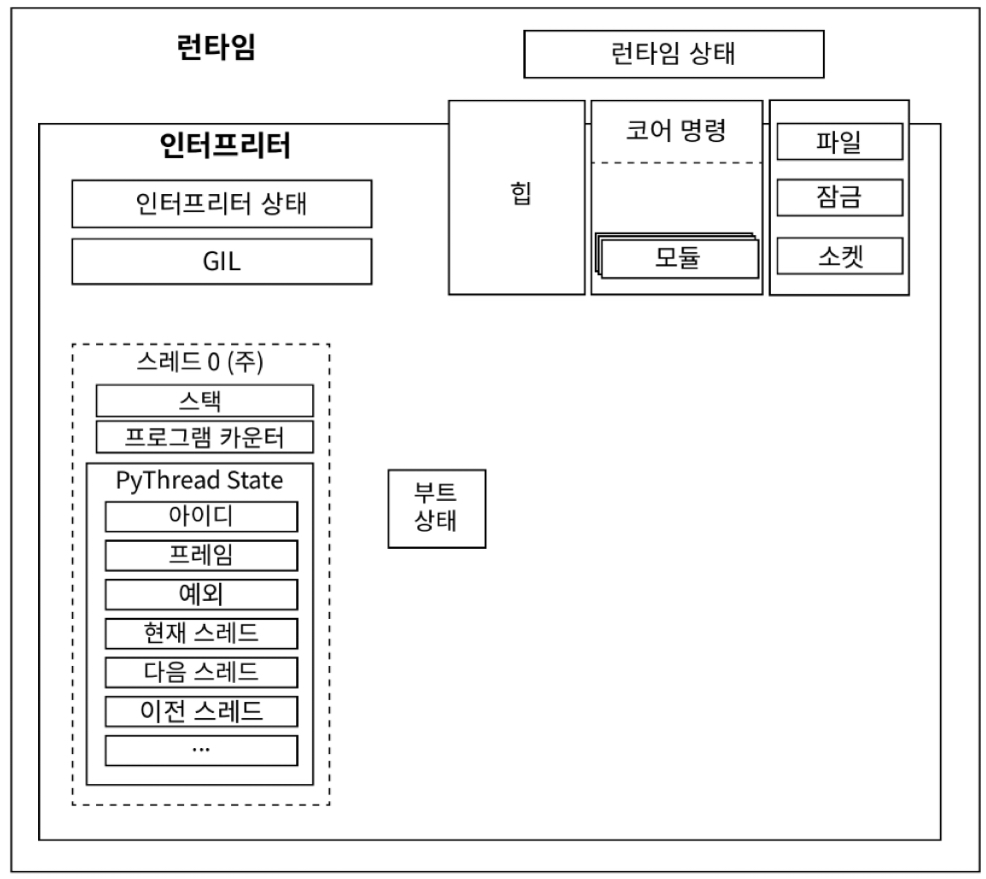
10.4.4 Thread state
- 독자적인 Thread 관리 구현 제공
- Thread가 평가 루프에서 Python bytecode 를 실행해야 하기 때문에 CPython 에서 Thread 를 실행하는 것은 OS Thread 를 spawn 하는 것만큼 간단하지 않음
- Python Thread = PyThread 라고 부름
- Python thread 는 code object 실행 시 interpreter 에 의해 spawn
- CPython 은 runtime 이 하나, 이 runtime 은 상태를 가지고 있음
- CPython 은 하나 이상의 interpreter 를 가질 수 있음
- interpreter 는 interpreter state 를 가짐
- interpreter 는 code object 를 일련의 frame object 로 변환
- interpreter 는 thread를 최소 하나 가짐
- frame object 는 frame stack 위에서 실행
- CPython은 value stack 에서 value 참조 가능
- interpreter state 는 thread 를 linked list 로 가짐
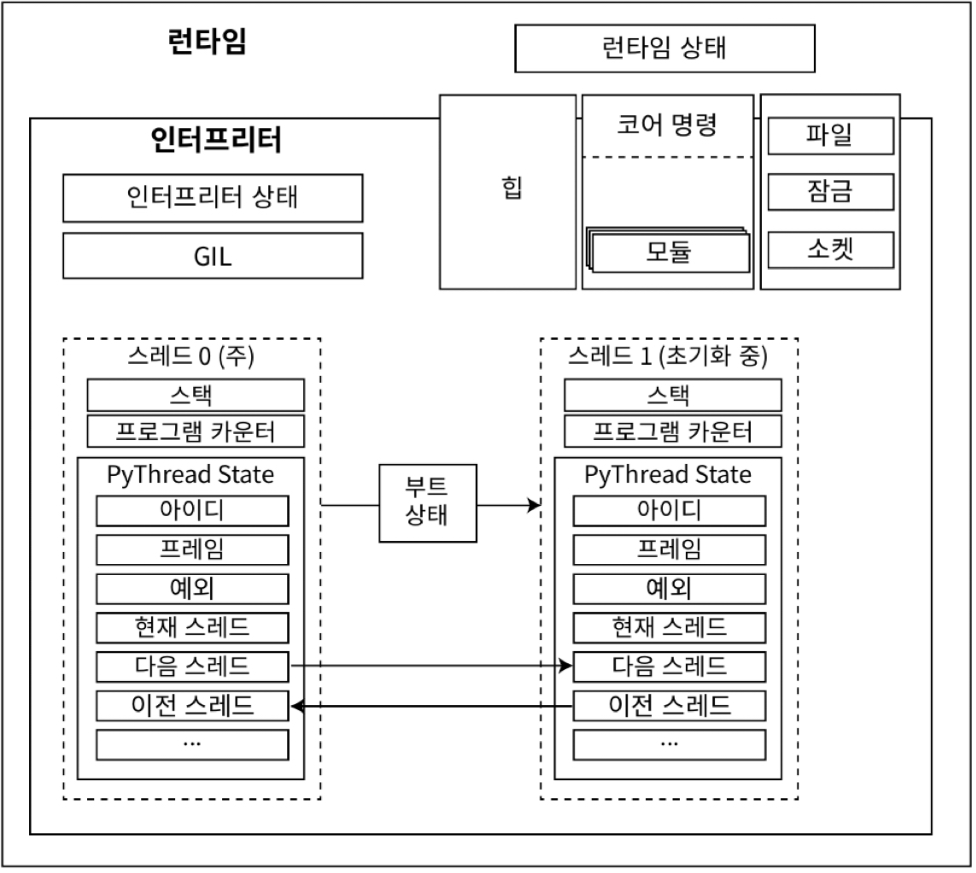
- Multiprocessing 준비 데이터 처럼 Thread 도 boot state 가 필요하지만 Thread 는 부모와
메모리 공간을 공유하기 때문에 데이터를 직렬화해서 file stream 으로 전달할 필요 없음
- Thread 는 threading.Thread type 의 instance
- threading.Thread 는 PyThread type 을 추상화하는 고수준 모듈
- PyThread instance 는 C 확장 모듈
_thread가 관리 _threadmodule 은 새 thread 를 실행하기 위한 진입점으로thread_PyThread_start_new_thread()제공
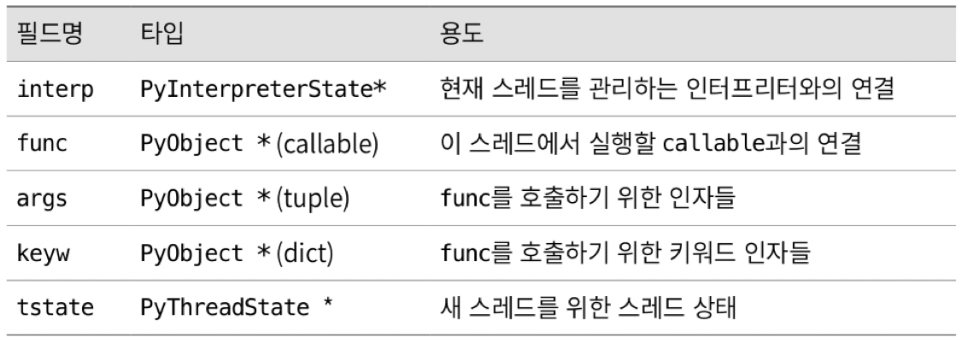
[new thread instance 화]
- bootstate 생성 후 args, kwargs 인자와 함께 target 에 연결
- bootstate 를 interpreter 상태에 연결
- 새 PyThreadState 를 생성하고 현재 interpreter 에 연결
PyEval_InitThreads()를 호출해 GIL 이 활성화되지 않았을 경우 GIL 활성화- OS에 맞는
PyThread_start_new_thread구현을 사용해 새 Thread 시작
[bootstate property]
10.4.5 POSIX Thread
Python/thread_pthread.h에서 찾을 수 있음- pthread.h C API 를 추상화하고 몇 가지 추가 안전장치와 최적화 제공
- pthread 도 자체적인 stack size 를 가지고 있기 때문에 Python depth limit 과 충돌이 발생 가능
- thread stack size 가 python maximum frame depth 보다 작다면 RecursionError 가 발생하기 전에 Python Process 전체가 충돌할 것
- Python depth 제한은
sys.getrecursionlimit()을 통해 runtime 에 결정
10.5 비동기 프로그래밍
- async keyword 로 future 생성하기
- yield from keyword 로 coroutine 실행
10.6 generator
- yeid 문으로 값을 반환하고 재개되어 값을 추가로 반환할 수 있는 함수
- 주로 file, database, network 같은 큰 datablock 의 값을 순회할 때 memory 효율 측면에서 유리하기 때문에 사용
- return 대신 yield 를 사용하면
값 대신 generator 객체가 반환
def letters():
i = 97
end = 97 + 26
while i < end:
yield chr(i)
i += 1
for letter in letters():
print(letter)- for 문 구현 : iterator protocol 을 이용
- for, while 문은 builtin 함수인 next 를 사용해서
__next__()를 가진 객체 반복
- generator 가 특별한 이유 =
__next__()구현이 generator 함수를 마지막 상태에서부터 다시 호출 - generator 는 background 에서 작동하지 않고 정지
- generator 에서 다음 값을 요청할 때 실행이 재개
- generator 객체 구조는 마지막으로 실행한 yield 문의 frame object 유지
10.6.1 generator 구조
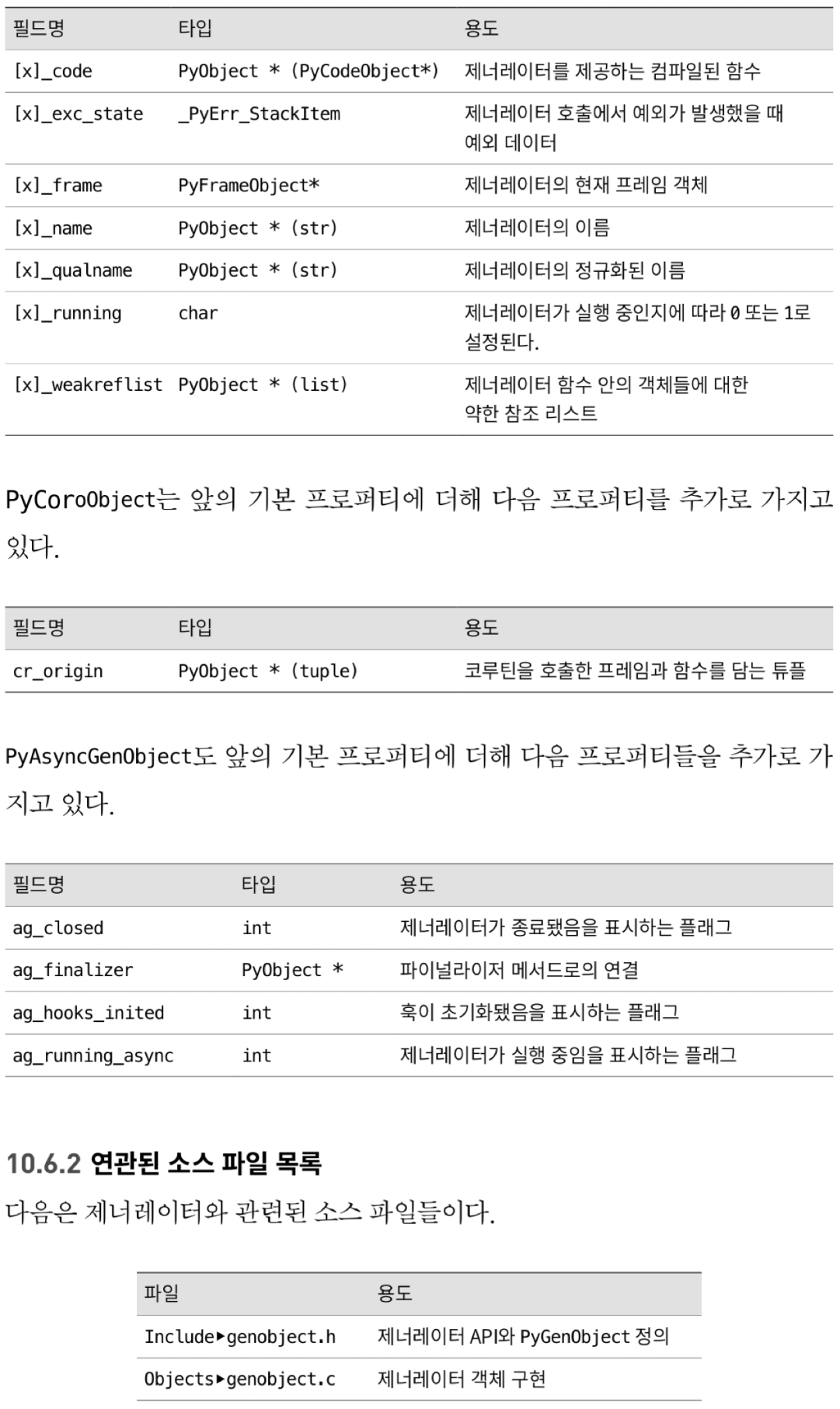
10.6.3 generator 생성하기
- gi_code property 에 compile 된 code object 설정
- generator 가 실행 중이 아니라고 표시 (gi_running=0)
- 예외와 약한 참조 리스트를 NULL 로 설정
10.6.4 generator 실행하기
__next__()를 호출하면gen_iternext()가 generator instance 와 함께 호출Objects/genobject.c의gen_send_ex()호출
등등 여러 개가 있음 : 정리 못함
11장. 객체와 타입
- Python 의 모든 type 은 내장된 기반 타입인 object 를 상속
Object/object.c : object type 의 기본 구현 > 순수한 c code
[Python object 구성요소]
1. core data model 과 compile 된 함수를 가리키는 포인터
2. 모든 custom attribute 와 method 를 담는 directory
11.1 내장 타입
- Python 의 core data model 은 PyTypeObject 가 정의
Object/typeobject.c, Object/rangeobject.c

11.2 객체와 가변 객체 타입
- PyObject 는 모든 Python object 의 기본 data segment
- Python object 를 가리킬 때 PyObjct * 이 사용
PyObject_HEAD(PyObject): 일반적인 type 위한 macroPyObject_VAR_HEAD(PyOVarObject): container type 을 위한 macro
11.3 type 타입
- Python object 는 ob_type 이라는 property 를 가짐
- 내장 함수 type() 으로 해당 property 값을 얻을 수 있음
- type() 의 return value 는 PyTypeObject instance
11.3.1 type slot
Include/cpython/object.h에서 정의- 각 type slot 은 property name 과 definition signature 를 가짐
- 모든 type slot 은
Include/typeslots.h에 정의된 대로 이 상수들을 사용
11.3.3 type property dictionary
- Python 에서는 class keyword 로 새 type 정의 가능
- 사용자 정의 type 은 type object module 의
type_new()가 생성 - 사용자 정의 타입은
__dict__()로 접근할 수 있는 property dictionary 를 가짐 - 사용자 정의 클래스의 property 에 접근하면 기본
__getattr__()구현은 property dictionary에서 접근할 property 를 찾음
11.4 bool, long type
- bool type 은 내장 타입 중 가장 간단한 구현을 가진 타입
- 이 type 은 long 을 상속하며 dictionary 에 정의된 상수인 Py_True 와 Py_False 를 가지고 있음
- 이 상수들은 Python interpreter 가 instance 화 될 때 만들어지는 불변 인스턴스
Objects/boolobject.c
11.4.1 long type
long type
- 가변 길이 숫자를 저장 가능
- PyObject 변수 header 와 숫자 list 로 구성되어 있음
- 숫자 list ob_digit 의 크기는 처음에는 1로 설정 > 초기화되면 길이가 늘어남
정수의 최대 길이: 컴파일된 binary 에 설정되어 있음
ex) 24601
- ob_digit [2, 4, 6, 0 1]
_PyLong_New(): 새 long 메모리를 할당- 이 함수는 고정된 길이가
MAX_LONG_DIGITS보다 작은지 확인한 후에 ob_digit 에 맞춰 메모리 재할당
- C의 long을 Python long 으로 변환하려면 먼저 C long 값은 숫자 list로 분해하고 Python long 에 메모리를 할당한 후에 각 자리의 숫자 설정
한 자릿수 숫자일 경우: long object 에 이미 길이 1로 ob_digit이 초기화 되어 있기 때문에 추가 메모리 할당 없이 바로 객체에 설정
Objects/longobject.c
- double 숫자를 Python long 으로 변환하려면
PyLong_FromDouble을 사용
11.5 unicode character type
[Python unicode character encoding 지원]
1. 1byte : Py_UCS1
2. 2byte : Py_UCS2
3. 4byte : Py_UCS4
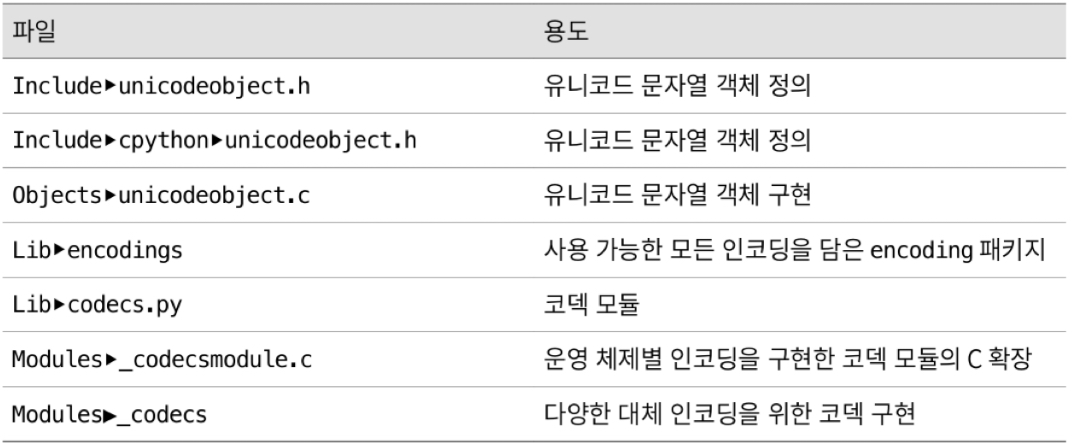
11.5.2 unicode code point 처리하기
- CPython은 UCD 사본을 포함하고 있지 않기 때문에 unicode standard가 변경될 때마다 CPython을 업데이트 하지 않아도 됨
- CPython unicode character 이 처리하는 것은 encoding 뿐
- code point 를 올바른 script 로 나타내는 거은 OS 의 책임
- UCD 가 포함된 unicode 표준에는 새로운 문자와 script, emoticon 이 정기적으로 업데이트
- OS는 patch 를 통해 update 를 반영
- UCD 는 code block 이라는 section 들로 나뉘어 있음
- CPython 을 web server 로 사용할 경우 system 의 unicode encoding 이 사용자에게 반환되는 HTTP header 의 encoding value 와 일치해야함
11.5.3 UTF-8 대 UTF-16
[일반적인 encoding 방법]
- UTF-8 은 UCD 에서 1~4 byte code point 인 모든 문자를 지원하는 8bit character encoding (일반적으로 사용)
- UTF-16 은 16bit character encoding 으로 UTF-8 과 비슷하지만 ASCII 등의 7~8bit character encoding 과는 호환되지 않음
11.5.4 wide character type
- CPython source code 에서 encoding 방식을 알 수 없는 Unicode character 을 처리할 경우 c type wchar_t 가 사용
- wchar_t 는 확장 문자를 사용하는 문자열을 위한 C 표준으로, unicode character 을 memory 에 담기에 충분
11.5.5 byte order mark
- file 등의 입력을 decoding 할 때 CPython 은 byte order mark, BOM 을 보고 byte 순서를 인식
- BOM 은 unicode byte stream 의 시작 부분에 나타나는 특수 분자
- 수신자에게 이 stream 에 어떤 byte 순서로 데이터가 저장되어 있는 지 알려줌 (ex) big endian, little endian)
UTF-8
- BOM 지원 > 의미가 없음
- encoding data sequence 첫 부분에
b'\xef\xbb\xbf'와 같이 나타냄 - 시작부분이 다음과 같으면 data stream 의 encoding 이 UTF-8 일 확률이 높음
- UTF-16, UTF-32 는 big endian, little endian 모두 BOM 을 지원
11.5.6 encoding package
Lib/encodings : CPthon 을 위해 100개 이상의 encoding 지원
- character, byte stream 의 .encode(), .decode() method 는 호출될 때마다 이 package 에서 encoding 검색
11.5.7 codec module
- data 를 특정한 encoding 으로 변환
- getencoder(), getdecoder() 를 사용하면 특정한 encoding 의 encoding 함수와 decoding 함수를 가져올 수 있음
11.5.8 codec 구현
Objects/unicodeobject.c
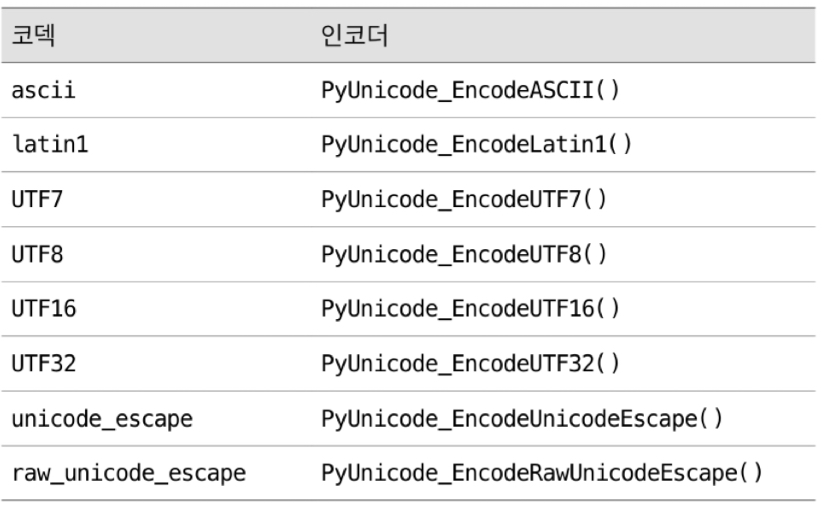
11.5.9 내부 codec
- 내부 encoding 은 CPython 의 고유 특성으로 일부 standard library 함수와 source code 작성에 유용하게 사용
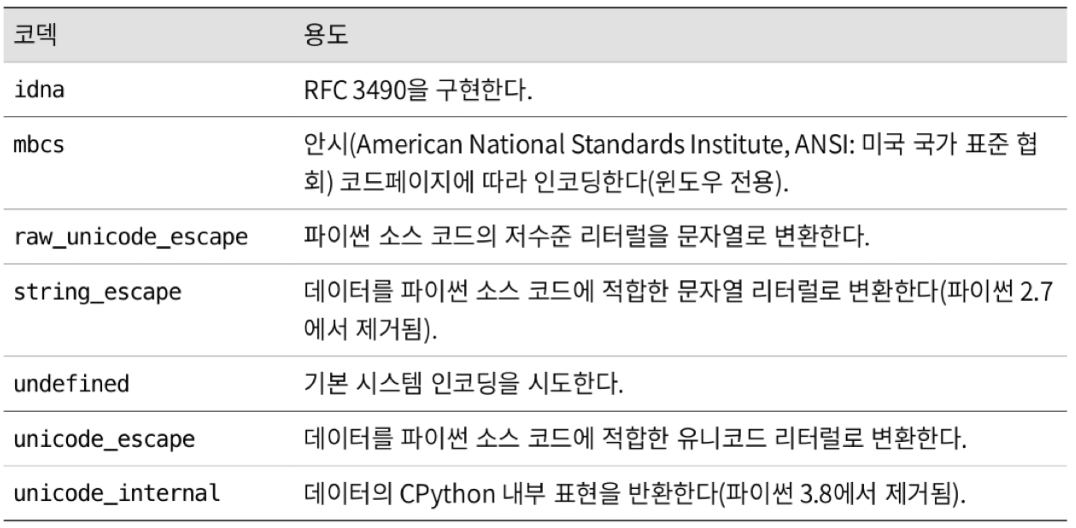
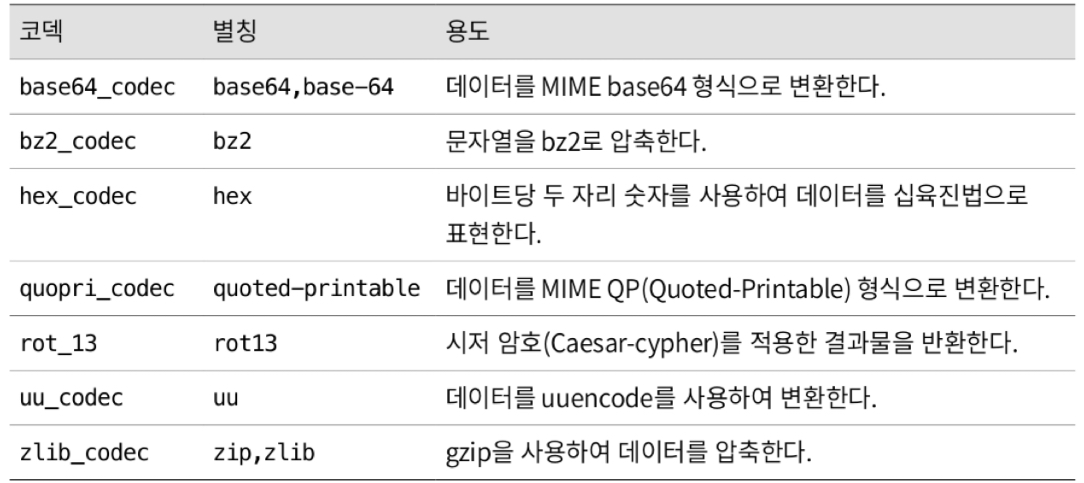
11.6 dictionary type
11.6.1 hashing
- 모든 내장 불변 타입은 hash function (tp_hash type slot 에 정의) 제공
- 사용자 지정 타입의 경우
__hash__()를 이용해서 hash function 정의 - hash value 는
pointer 와 크기가 동일(64bit system > 64bit, 32bit system > 32bit) - hash value 가 해당 값을 메모리 주소를 의미하지는 않음
- 값이 동일한 두 불변 instance 의 hash 는 같아야 함
11.6.3 dictionary 의 구조
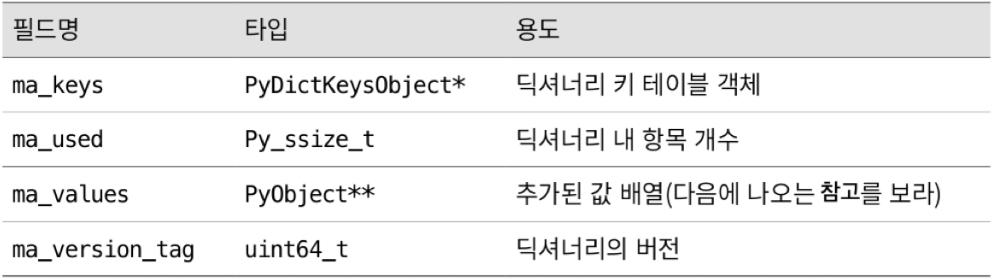
PyDictObject : dictionary object
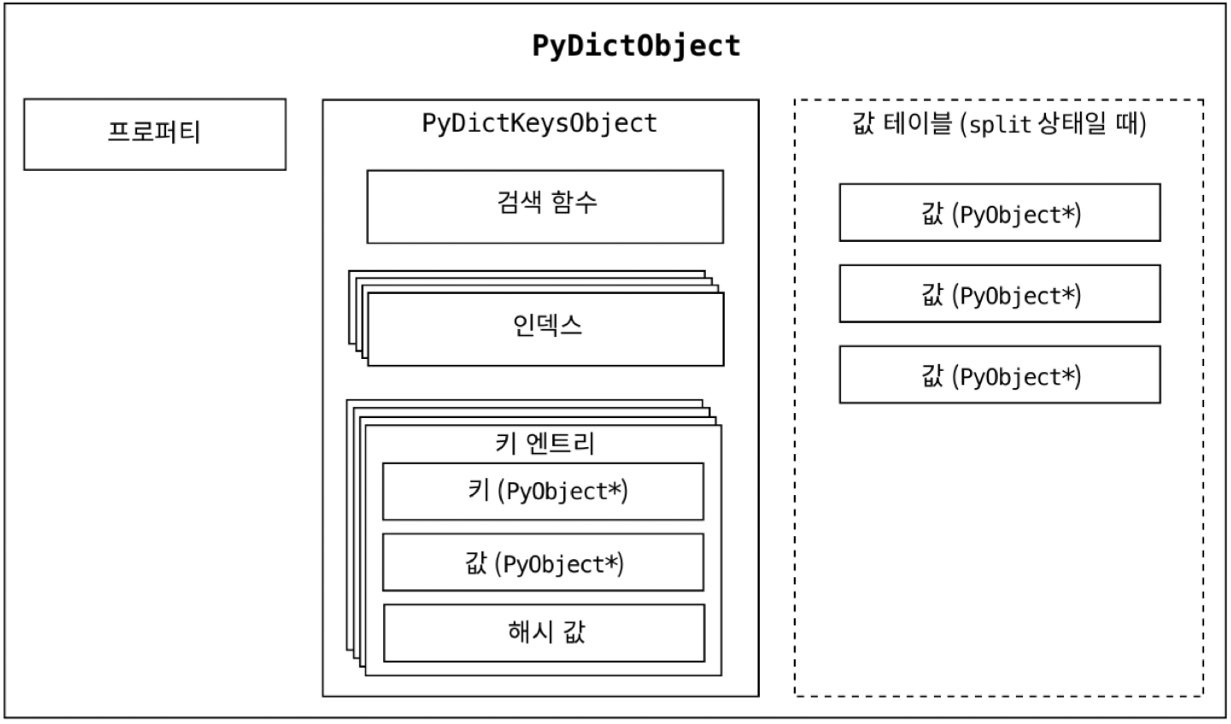
PyDictKeysObject : Dictionary key table
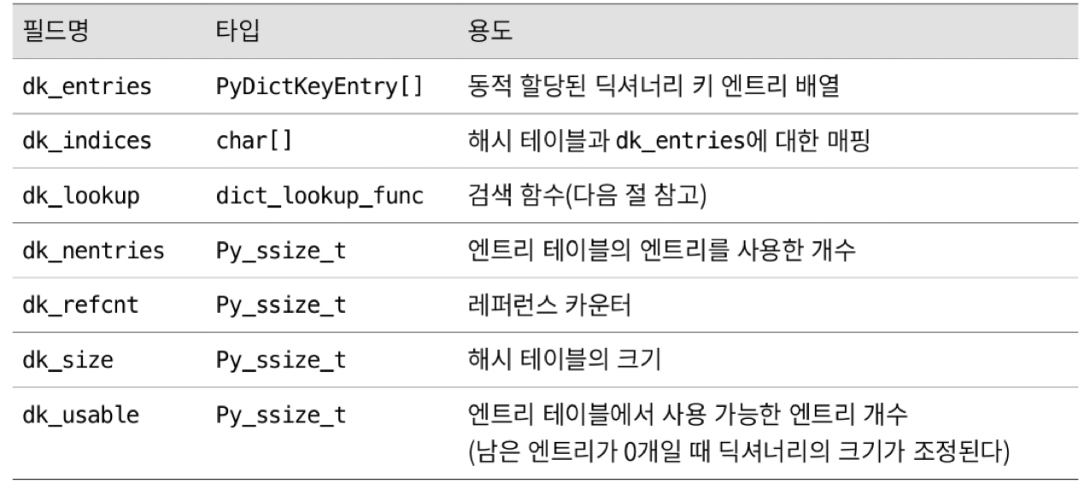
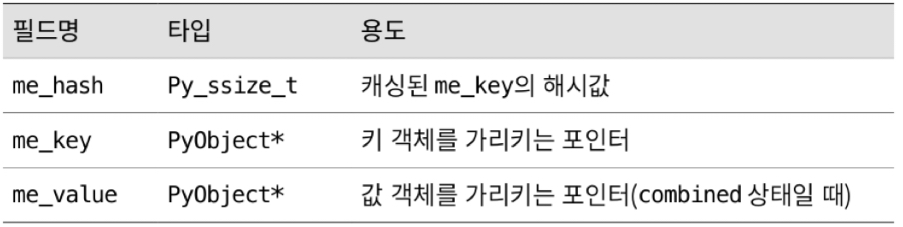
11.6.4 검색
lookdict()
- 주어진 key 의 memory address 를 key table 에서 찾을 수 있는 경우
- 주어진 key object 의 hash value 를 key table 에서 찾을 수 있는 경우
- dictionary 에 해당 key 가 없는 경우
[검색 순서]
1. ob의 hash value 를 구함
2. dictionary key 중 ob의 hash value 와 일치하는 값을 찾아 index ix 를 구함
3. ix 값이 비어있을 경우 DKIX_EMPTY 반환
4. 주어진 index 로 key entry ep 를 찾음
5. ob 와 key 의 값이 일치하면 ob 는 key 와 동일한 값을 가리키는 pointer 이기 때문에 찾은 값을 반환
6. ob 의 hash 와 key 의 hash 가 일치할때도 찾은 값을 반환
