Transformer는 최근에 NLP 뿐만 아니라 CV 분야에서도 많은 각광을 받고 있다. "Attention Is All You Need"는 이러한 Transfromer 구조를 처음 제시한 논문이다.
Attention Is All You Need 원본 사이트
1. Introduction
- 기존의 seq2seq 모델은 encoder, decoder를 포함하여 Recurrent, Convolution 신경망에 기반을 두어 사용하고 있음.
- 이 논문에서는 recurrent, convolution 신경망을 전혀 사용하지 않는 Transformer라는 새로운 Network architecture을 소개함.
- Transformer 모델은 기계 번역 작업에서 병렬화가 가능하여 기존 모델에 비해 training시간을 훨씬 줄일 수 있음.
2. Background
-
Extended Neural GPU, ByteNet, ConvS2S 에서도 sequential computation 을 줄이기 위한 연구가 이루어졌는데, 모든 연구는 CNN을 기반으로 이루어짐.
-
위의 모델들은 input - ouput의 관련성을 파악하기 위해 거리에 계산량이 증가
-
반면 Transformer에서는 CNN, RNN을 사용하지 않고 Multi-Head Attention을 통해 상수 시간의 계산만으로 가능함.
3. Model Architecture
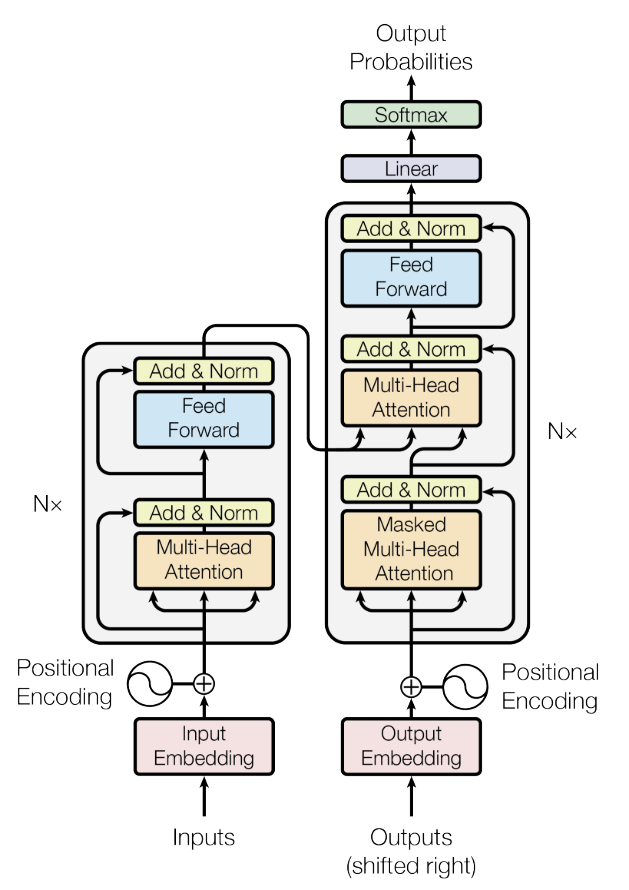
3-1. Encoder and Decoder Stacks
- Encoder: N=6의 동일한 레이어로 구성되어있음. 각각의 레이어는 multi-head self-attention, feed forward레이어로 구성됨.
- Decoder: Decoder 또한 N=6의 동일한 레이어로 구성되어있음. Encoder와 비슷한 구조를 가지지만 Masked Multi-Head Attention 레이어를 추가함.
3-2. Attention
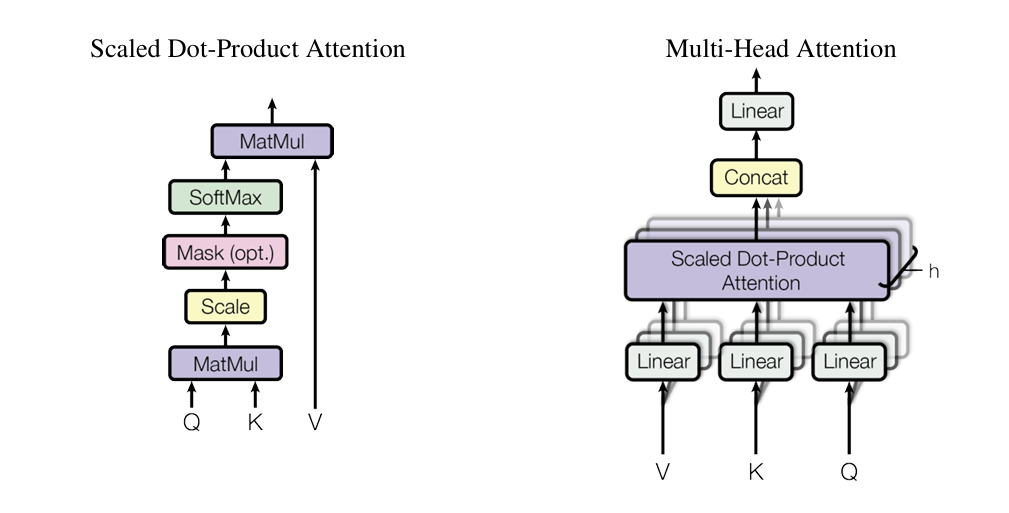
3-2-1. Scaled Dot-Product Attention
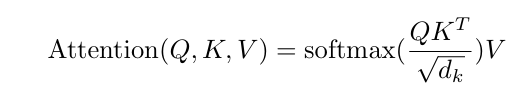
- Q, K, V는 각각 query(질문하는 주체->특정 단어), key(질문을 받는 주체->문장의 모든 단어들을 벡터화하여 stack한 Matrix), value(데이터의 값)을 의미함
- 로 나누어 large positive and large negative value들에 대해서는 매우 낮은 gradient를 학습이 잘 되지 않는 문제룰 해결함.( scaling을 통해 모든 값들이 0 근처에 오도록 만들어줌 )
3-2-2. Multi-Head Attention
3-3. Position-wise Feed-Forward Networks
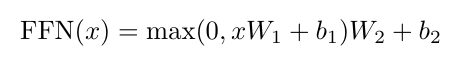
- 위의 모델 아키텍처에서 볼 수 있다시피 attention layer뿐만 아니라 Feed-Forward 레이어도 씀.
- input, output -> 512차원, inner-layer -> 2048차원
3-4. Embeddings and Softmax
- 다른 sequence 모델과 마찬가지로, input과 ouput token을 embedding layer를 거친 뒤 사용함.
3-5. Positional Encoding
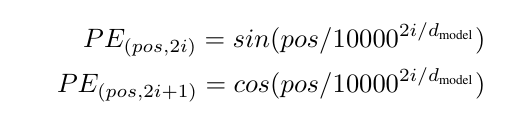
- 사인함수와 코사인함수 사용
4. Why Self-Attention
- self-attention, 즉 intra-attention은 단일 sequence 내의 서로 다른 위치를 연관시켜 sequence의 표현을 계산하는 attention 메커니즘임.
- 매우 긴 sequence 를 포함하는 작업에서 r의 이웃만을 고려하면 되므로 계산 효율성을 더욱 향상시킬 수 있음.

ai 개발자를 꿈꾸는 대학생