본 글은 네이버부스트코스트 "컴퓨터 비전의 모든 것" 강의를 정리한 내용입니다.
1. Semantic Segmentation
What is Semantic Segmentation?
- 이미지를 pixel 단위로 분류하는 task
- 여러 명의 사람을 각각 사람1, 사람2, ... 이런 식으로 한명한명 구분하진 않고 모두 "사람"으로 분류함.
활용되는분야
- 의료 이미지
- 자율 주행 등등..
- 컴퓨터를 이용한 사진 편집(computational photography)
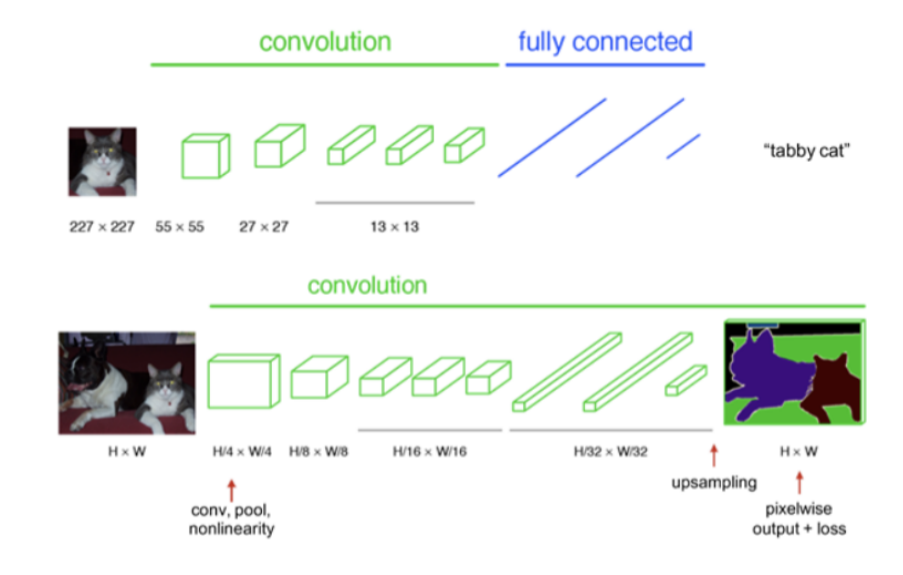
2. Semantic segmentation architectures
2-1.Fully Convolutional Networks(FCN)
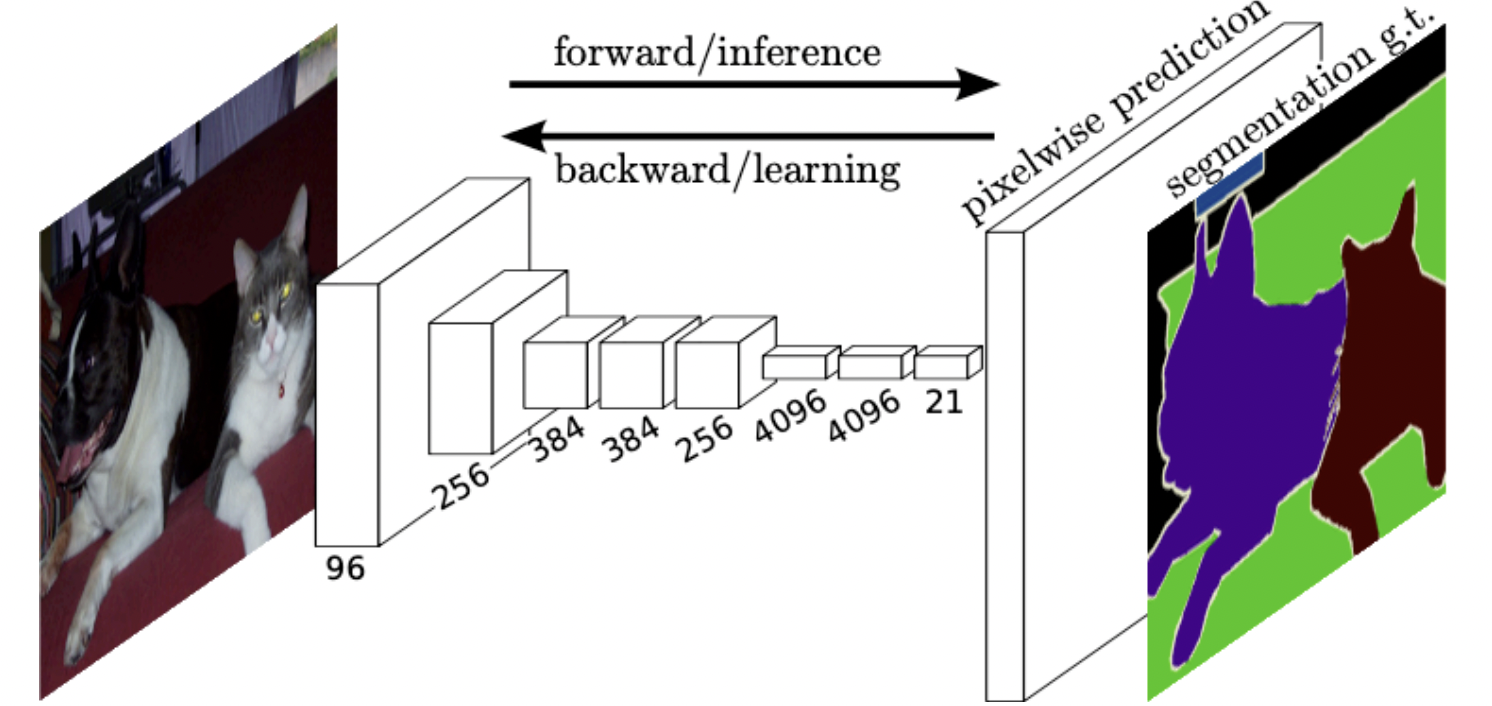
- Semantic segmentation의 첫 end-to-end 아키텍쳐.
end-to-end : 입력부터 출력까지 모두 미분가능한 Neural Net으로 구성되서, 입력과 출력의 pair만 있으면 학습을 통해서 target task를 해결.
- 입력으로 임의의 해상도를 넣을 수 있고 출력도 이에 맞춰 나올 수 있도록 설계됨.
Fully connected vs Fully convolutional
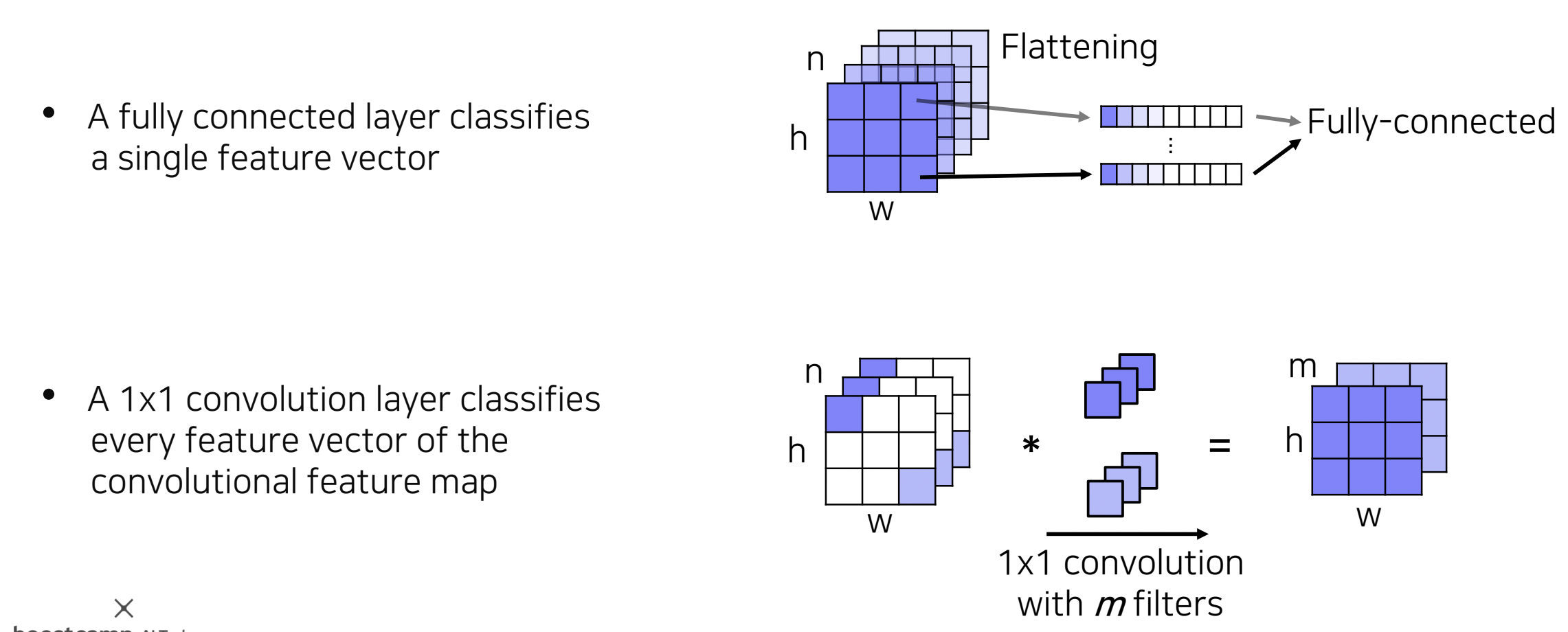
-
Fully connected : 이전 convolutional layer에서 출력된 feature map을 flattening해서 사용 --> 공간 정보 고려X
-
Fully convolutional : 채널축으로 1X1 convolutional 커널이 한 weight column으로 동작하여 Fully convolution을 진행, 채널 수 만큼의 feature map을 얻을 수 있고, 공간 정보 고려 O
-
Fully convolutional의 문제점 : 더 넓은 receptive field를 확보하기 위해 pooling을 진행할 수록 저해상도의 출력을 얻게됨.
receptive field : 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기
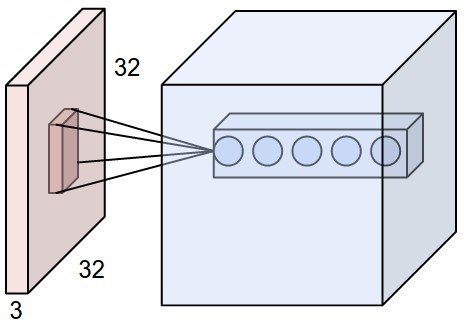 파란색 원이 뉴런 하나이고, 그에 영향을 미치는 분홍색 공간이 receptive field임
파란색 원이 뉴런 하나이고, 그에 영향을 미치는 분홍색 공간이 receptive field임
( 출처 : https://m.blog.naver.com/sogangori/220952339643)
Upsampling layer
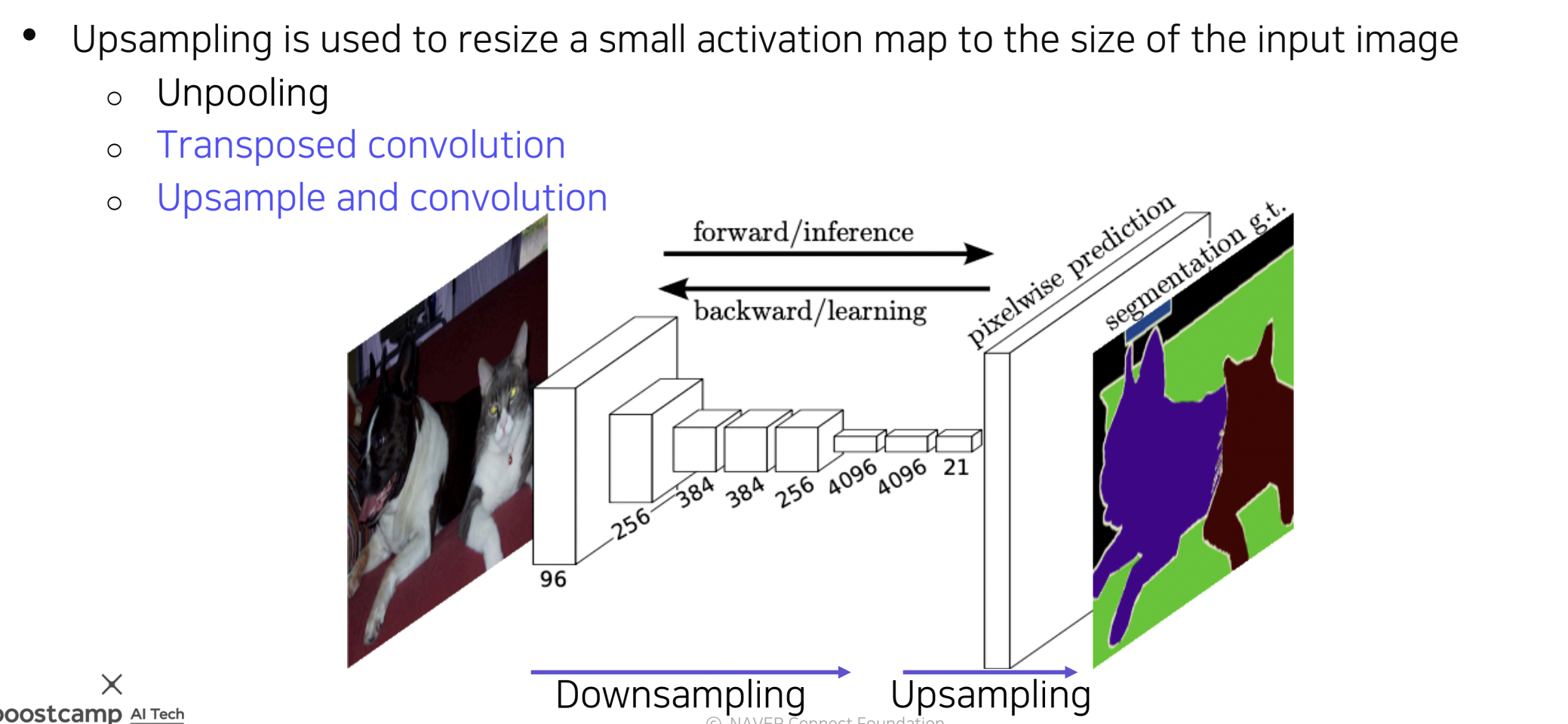
- 저해상도의 출력을 얻게되는 문제를 해결하기 위해 고안됨.
Upasampling #1 - Transposed convolution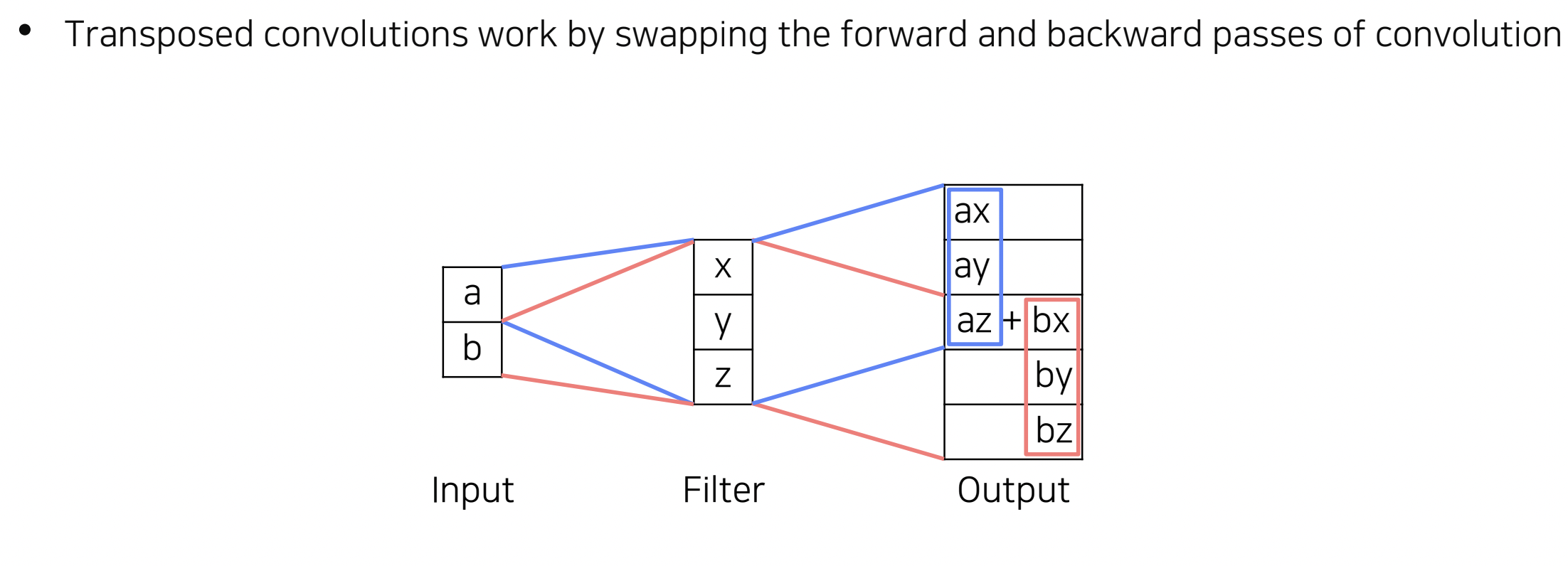
- 입력과 필터를 곱하여 각각 해당하는 위치에 출력하는 방식, 겹치는 위치의 경우 그 값을 합하여 출력
Upsampling #2 - Upsample and convolution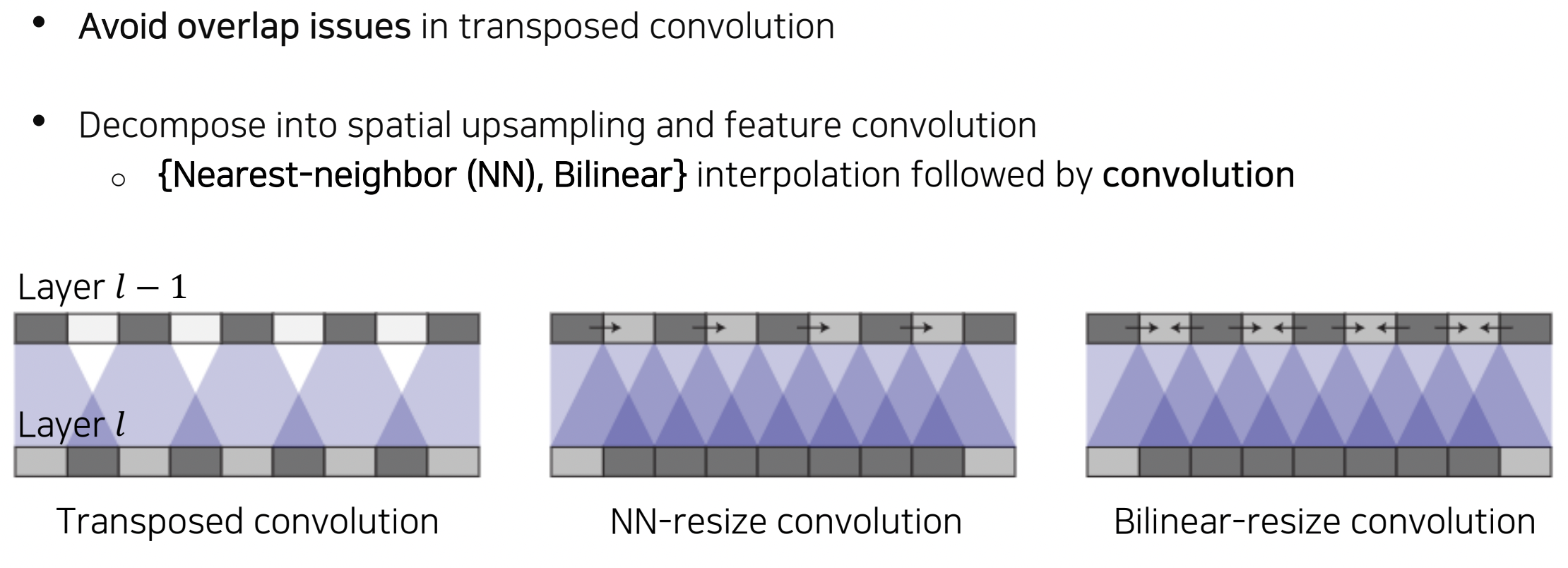
- upsampling 과정을 두 단계로 분리하여, 먼저 Nearest-neighbor, Bilinear interpolation 등의 interpolation 과정을 통해 upsample시키고, 다음으로 학습가능한 형태를 더해주기 위해 이를 convolution layer에 통과
FCN features
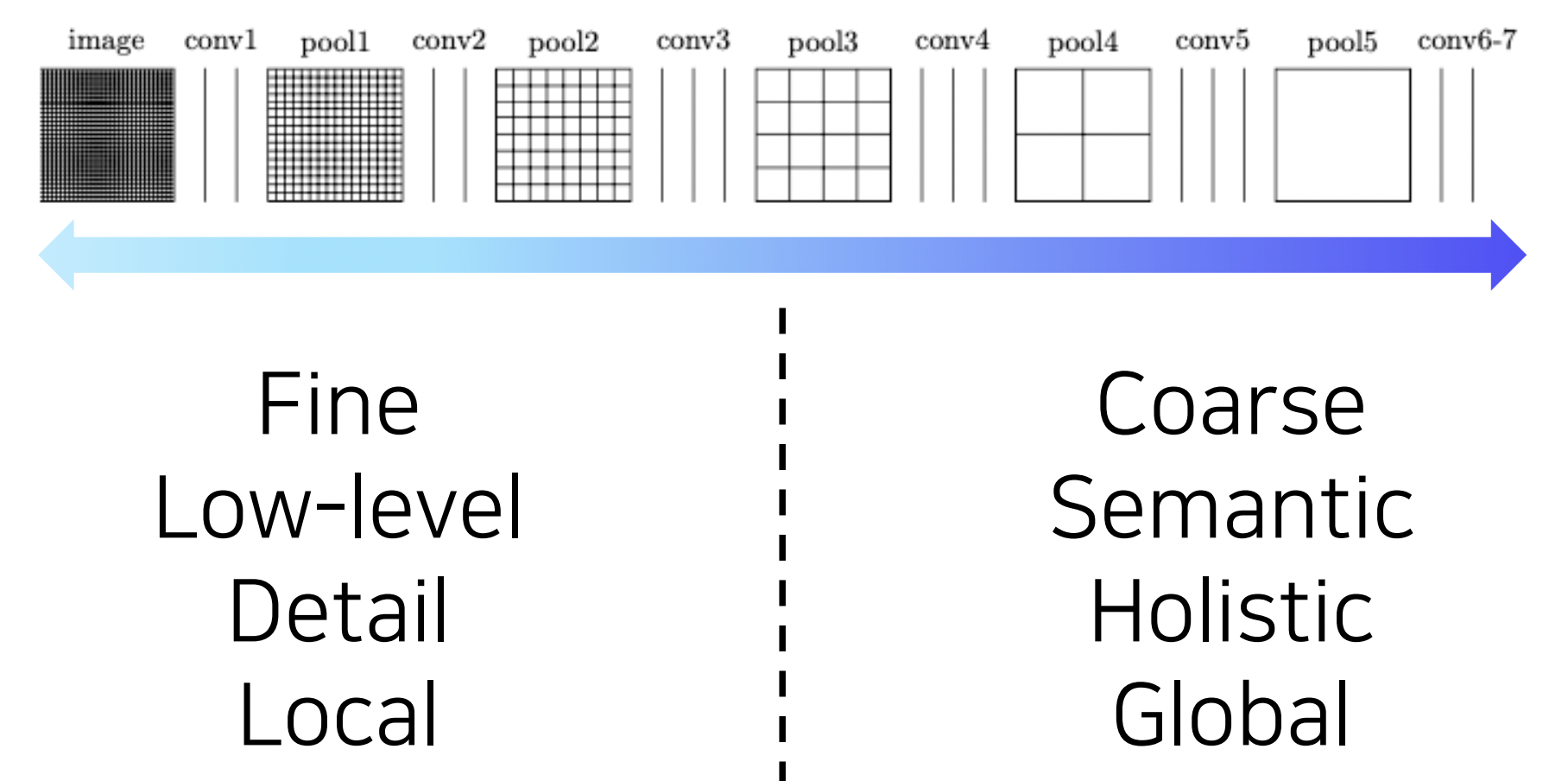
-
낮은 레이어의 경우 디테일한 부분들에 대한 특징, 높은 레이어의 경우 전반적이고 의미론적인 특징에 대한 정보를 담고 있음
-
semantic segmentation을 위해서는 두 가지 정보가 모두 필요함. 각 픽셀 별로 의미를 파악하고 영상 전체를 바라보면서 현재 픽셀의 경계부분을 디테일하게 파악해야하기 때문.
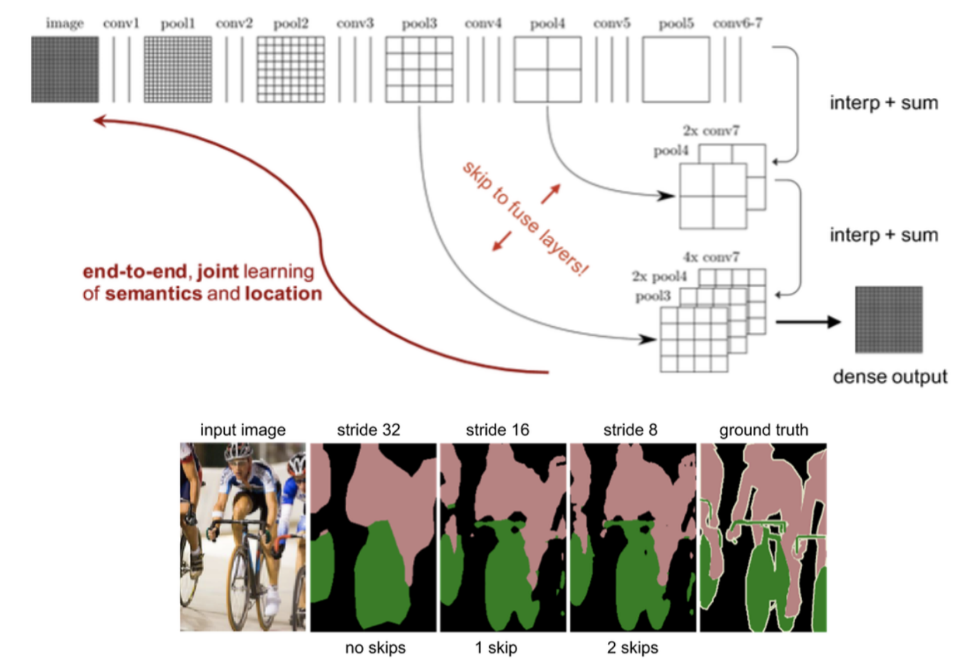
-
그래서 FCN에선 skip connection을 사용하여 낮은 레이어의 feature map을 직접적으로 고려할 수 있도록 설계됨.
skip connection : 입력 데이터가 네트워크의 여러 레이어를 건너뛰어 출력 레이어에 직접 연결
출처 : https://wikidocs.net/202621
2-2. Hypercolumns for Object Segmentation
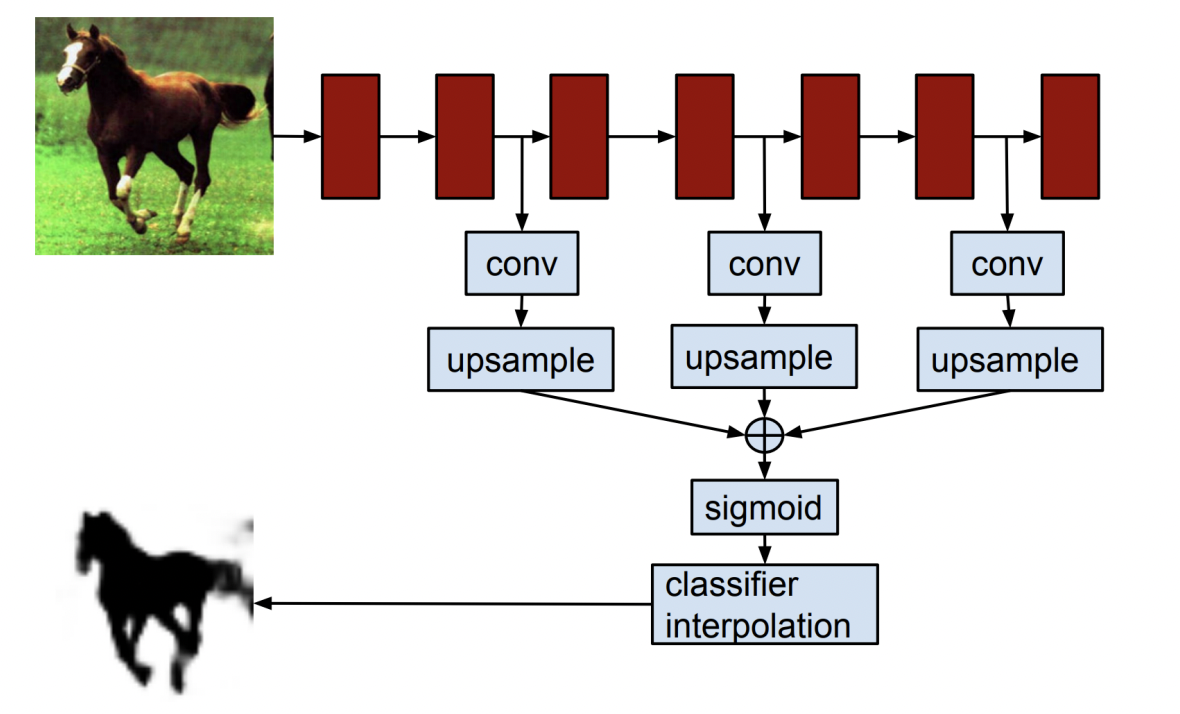
- end-to-end 방식이 아니라 별도의 알고리즘을 사용하여 얻은 물체의 bounding box를 입력으로 사용한다는 점에서 FCN과 차이가 있음.
2-3. U-Net
- FCN의 구조에서 따옴
- 낮은 layer의 feature와 높은 layer의 feature를 잘 결합함.
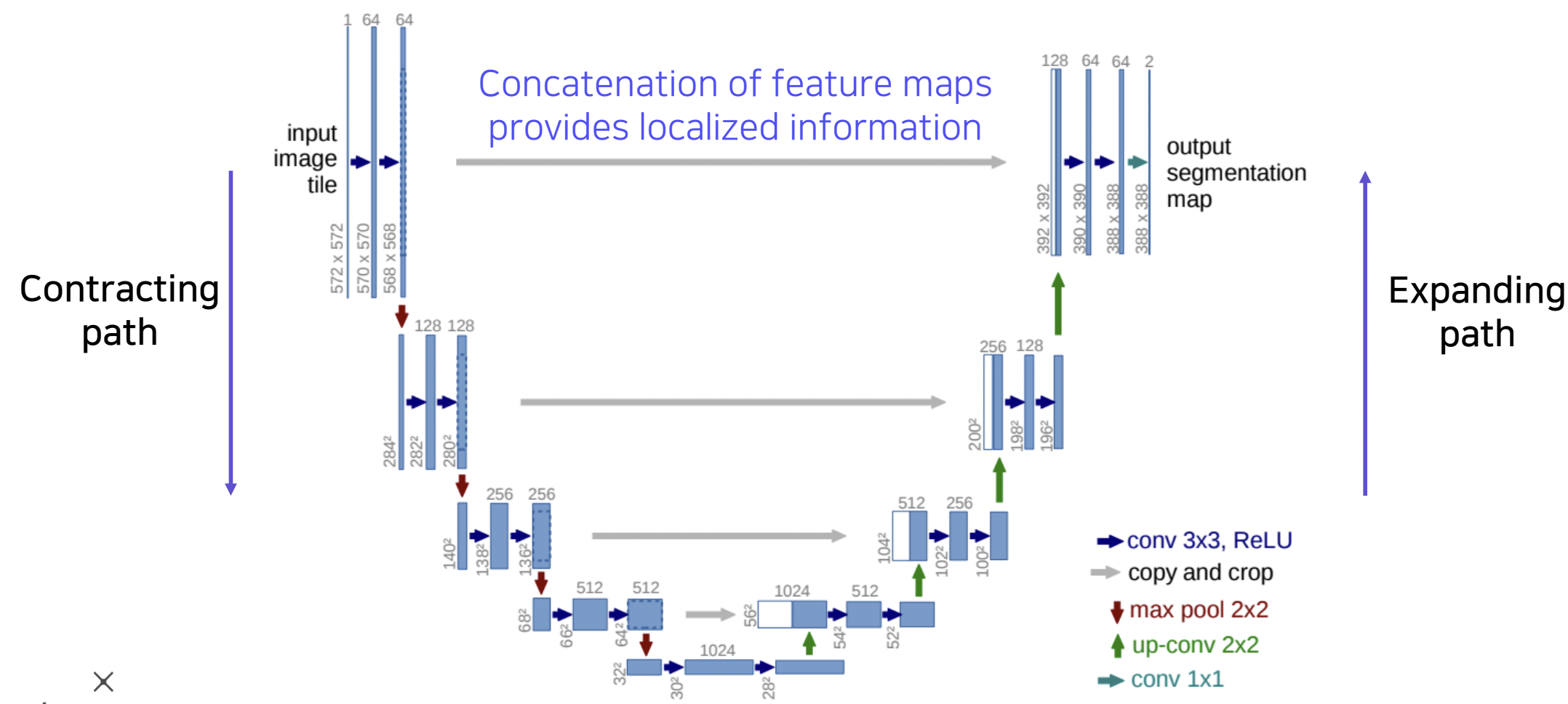
- 대칭적인 downsampling, upsampling 과정을 거치는 구조.
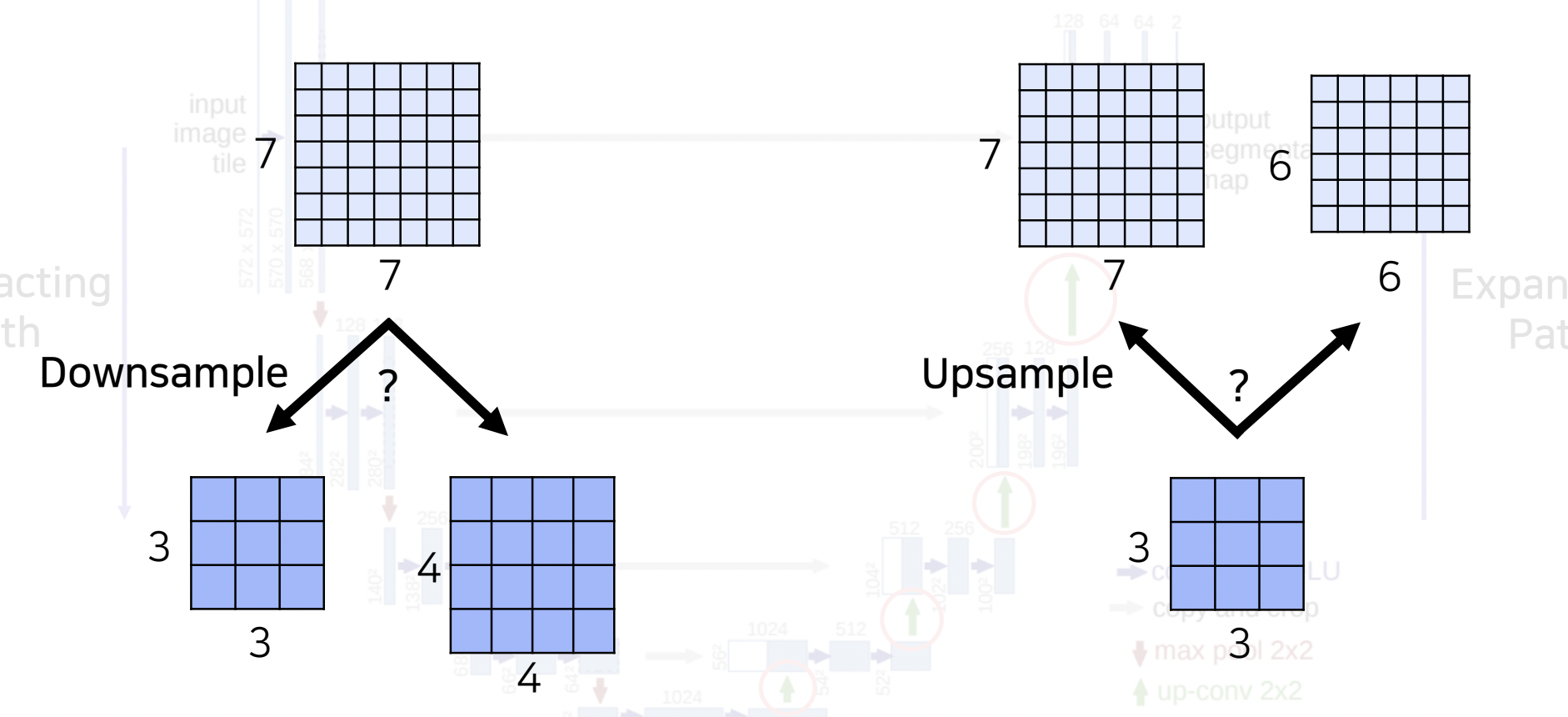
- Downsampling 과정에서는 pooling을 통해 공간해상도를 절반으로 줄이고, 채널 수를 두배로 늘리는 방식, upsampling 과정에서는 반대로 공간해상도를 두배로 늘리고, 채널 수는 절반으로 줄이는 방식
- skip connection을 통해 지역적인 정보를 담고있는 downsampling 과정에서의 feature map을 upsampling 과정의 segmentation map에 합해줌.
- 주의할점 : 공간해상도가 맞아야 함
2-4. DeepLab

Conditional Randon fields(CRF)

- sementic segmentation에서 결과를 뽑아보면 위에서 2번째 그림과 같이 굉장히 흐릿한 결과가 나옴.
- 출력 score map과 경계선들을 이용해서 score map이 경계선에 잘 맞도록 반복적으로 확산 시켜줌.
Dilated Convolution
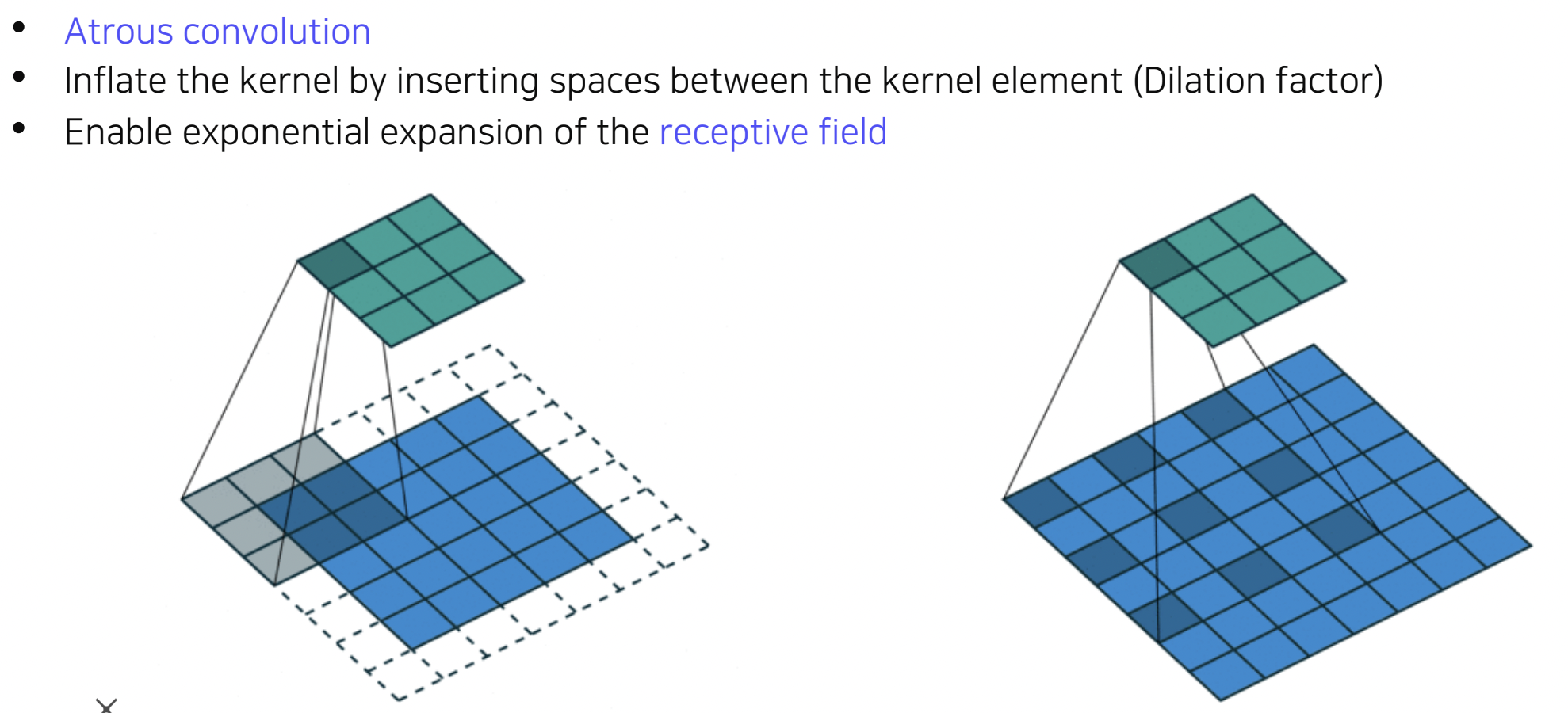
- convolution filter들 사이에 dilation factor 만큼 space를 넣어주는 방법
- convolution filter보다 넓은 영역을 고려할 수 있는, 즉 지수적으로 receptive field를 확장할 수 있는 방법
Depthwise separable convolution
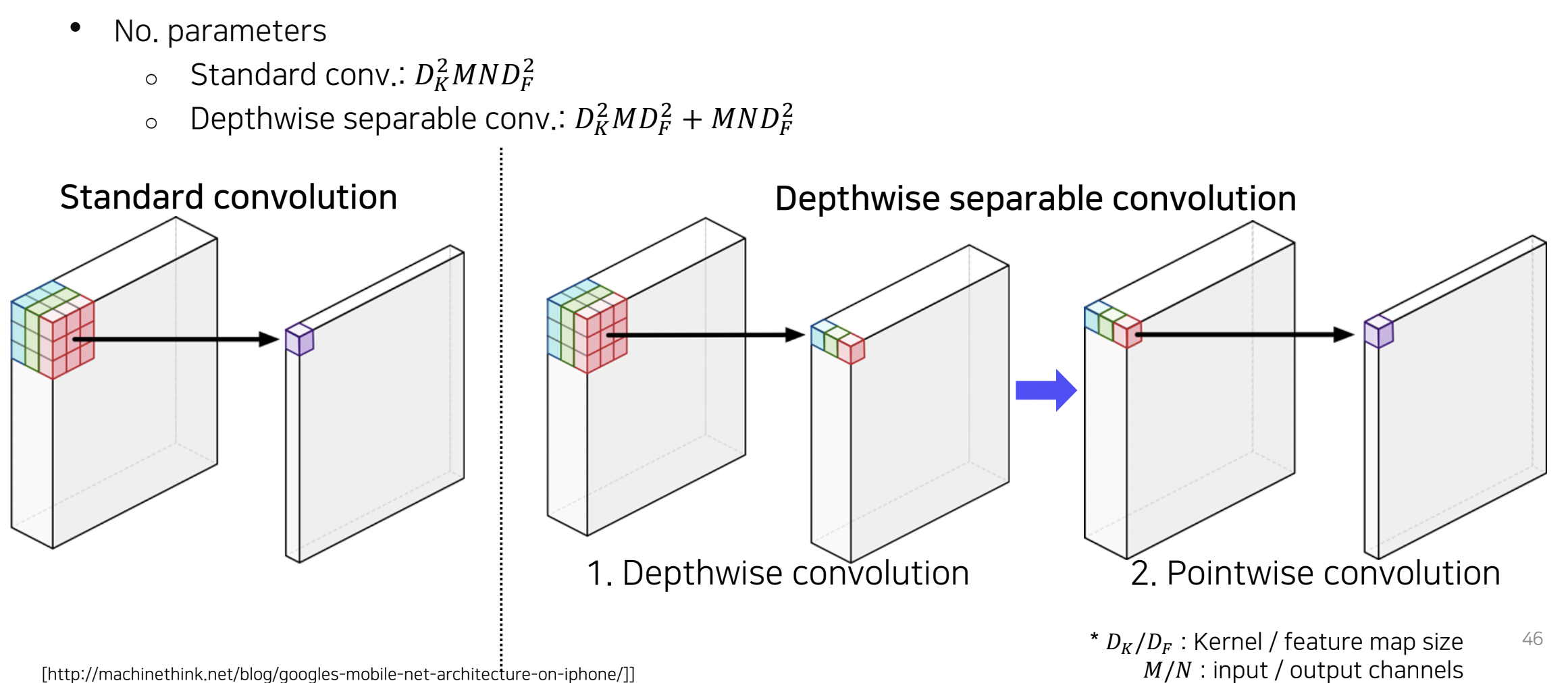
- . DeepLab v3+에서는 semantic segmentation의 입력 해상도가 워낙 크기 때문에 연산이 복잡해지는 것을 완화하기 위해 dilated convolution을 depthwise separable convolution과 결합하여 사용
- 기존 convolution layer는 하나의 activation값을 얻기 위해 channel 전체에 걸쳐서 내적을 해서 하나의 값을 뽑음.
- Depthwise separable은 이 절차를 두 개로 나눔
- Depthwise convolution : 각channel 별로 convolution 해서 값을 뽑음.
- Pointwise convolution : 1x1 convolution을 통해서 하나의 값이 나오도록 함.
