복잡도
알고리즘의 성능을 측정하는 복잡도에는 공간복잡도와 시간복잡도가 있다.
당연히 이 복잡도가 낮을수록 알고리즘은 효율적으로 동작한다.
하지만 이 공간복잡도와 시간복잡도는 일반적으로 trade-off 관계에 있어서 공간복잡도를 희생해 시간복잡도를 효율적으로 만들 수 있다.
반복되는 연산의 경우 해당 값을 저장해, 연산을 줄여서 시간복잡도를 감소시키는 것이다.
복잡도의 계산방법
측정
모든 연산에 카운트를 줘서 몇번의 카운트가 발생했는지 세는 방법
분석
반복문과 조건문을 확인해서 실행횟수를 분석하는 방법
Asymtonic notation
우리가 흔히들 착각하는게 Big O notation 이 최악의 경우에서 나오는 시간복잡도라고 알고 있는데, 이것은 완전히 잘못된 건 아니지만 설명이 필요한 부분이다.
밑의 내용은 퀵정렬을 예시로 들어 설명하면 조금 더 쉽게 이해할 수 있다.
먼저 알고리즘은 대상의 상태에 따라 작동이 다르게 될 수 있다. 퀵 정렬의 경우, 일반적으로 흩어진 경우, 피벗을 항상 최대값 혹은 최소값으로 선택할 경우에 시간복잡도가 다르다.
최악의 경우
빅오 노테이션이 최악의 경우에서의 시간복잡도라고 하는데 이는 거리가 좀 멀다. 최악의 경우든 평균적인 경우든 모두 big O notation, omega notation, theta notation이 존재한다.
따라서 최악의 경우라는 것은 알고리즘 대상의 상태에 따른 시간복잡도가 최악이라는 것이지, 이 상태가 big O notation이라는 것이 아니다.
평균적인 경우
평균적인 경우도 마찬가지로 일반적인 퀵소트가 O(nlogn) 이라고 하는데, 빅 오 노테이션이 최악의 경우의 시간복잡도라고 한다면 퀵 소트는 O(n^2)이 되어야 할 것이다.
즉 최악의 경우에 시간복잡도를 빅 오 노테이션이라고 말하는 것은 잘못되었다는 것이다.
Big O notation
그렇다면 얘기하는 big o notation 이 무엇인지 정확하게 짚고 넘어갈 필요가 있다. 간략하게 말하자면 big O notation은 집합이다. 특정 시간복잡도를 상한으로 하는 시간복잡도의 모든 집합을 big O notation 이라고 한다.

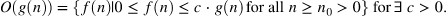
위의 식이 Big O notation을 나타내는 수식이다. 이 수식을 해석하자면, g(n)이 우리가 대상으로 삼을 함수이고, 모든 c에 대해서 c X g(n) 과 f(n) 이 만나지 않을 만큼 충분히 큰 n 일 때, c X g(n) 보다 작은 모든 f(n) 을 Big O notation이라고 부르는 것이다.
즉 c X g(n) 을 상한으로 하는, 모든 함수의 집합을 big O notation이라고 정의한다.

위의 예시이다.
즉 퀵정렬의 경우 O(n^2) 아닌 이유가 평균적인 상태와 최악의 상태를 구분지은 후에 big O notation 을 산출하기 때문에, 최악인 상태의 big O notation 과 평균적인 상태의 big O notation이 다른 것이다.
Omega notation
오메가 노테이션은 반대이다. Big O notation 이 특정 c x g(n) 을 상한으로 하는 알고리즘의 집합이었다면, 오메가 노테이션은 이 함수를 하한으로 하는 알고리즘의 집합이다.
Theta notation

세타 노테이션은 위의 그림과 같이 임의의 c1 과 c2 (0 < c1 < c2) 의 경우 c1 x g(n) < f(n) < c2 x g(n) 을 만족하는 모든 함수의 집합을 말한다.
간단하게 얘기해서 최고차항이 같은 함수를 의미한다.

결론
big O notaion을 사용하는 이유는 어떤 특정한 알고리즘이 동작할 때 일반적으로는 느리게 동작하지만 더 빠르게 동작하는 경우가 있다고 해서 그 경우를 빼버리지는 않는다.
예를 들어 일반적으로 n^2의 연산을 통해 동작하지만 특정 케이스에서는 1번의 연산만으로 동작하는 경우 이를 n^2 이 걸리지 않았다고 해서 이 알고리즘의 시간복잡도에 해당하지 않는다고 말할 수 없다. 때문에 n^2 을 상한으로 갖는 모든 연산동작의 집합을 의미하기 위해 big O notaion을 사용하고, 정확하게 일반적인 연산만을 시간복잡도로 나타내기 위해서는 theta notation을 사용하는 것이 맞을 것이다.
이렇게 보면 대충 big O notation이 최악의 시간복잡도를 가정해서 설정한 시간복잡도다 라는 것이 완전히 틀린 말은 아니지만, 더 정확한 논리 과정이 필요할 것이라고 생각한다.
