재귀(recursion)
재귀 호출
-
함수가 자기 자신을 호출하는 것을 재귀 호출이라 한다.
-
분할 정복(Divide & Conquer), 점화식 등을 구현하는 데에 많이 사용된다.
-
재귀 호출을 통해 분할한 후 문제를 해결하면, 모든 원소 O(n)에 대하여 문제를 해결해야되었던 것이, 분할 하는 횟수(logN) 만큼의 처리횟수를 가져갈 수 있으므로 시간복잡도를 줄일 수 있다.
-
대표적인 분할 정복 알고리즘은 merge sort 인데, 분할 한 후, 분할 된 대상
-
-
재귀 구현은 항상 반복(Iteration) 구현으로 변환될 수 있다.
- 함수 호출 자체가 오버헤드가 큰 작업이기 때문에, 반복문으로 사용하는 것이 좋다. 하지만 재귀식으로 작성했을 때는 한 눈에 들어오는 코드가 반복문으로 작성하면 굉장히 복잡한 경우가 많다. 어느 정도의 성능 감소를 감수해도 되는 경우라면 가독성을 위해 재귀식으로 구현하는 것을 고려할만 하다.
점화식
-
재귀식(Recursion relation)이라고도 부르며, 수열의 항 사이의 관계를 나타낸다.
-
일부 점화식은 일반식으로 풀이할 수 있다. 수열을 n에 대한 식으로 표현하는 것을 '풀이한다'고 한다.
- 피보나치 수열을 일반식으로 풀이한 것을 binet's formula라고 한다.
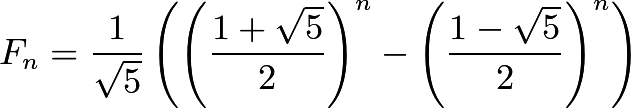
- 피보나치 수열을 일반식으로 풀이한 것을 binet's formula라고 한다.
-
점화식의 예
- 피보나치 수열: f(n) = f(n-1) + f(n-2)
- 팩토리얼: f(n) = n * f(n-1)
- 등차 수열: f(n) - f(n-1) = d
- 등비 수열: f(n) / f(n-1) = r
재귀 호출
재귀 호출을 통한 재귀식을 구현하는데에는 두 가지 조건이 있다. 이것은 반복문에서도 적용되는 문제이므로 특별히 재귀에만 해당되는 문제가 아니라, 반복을 구현할 경우에 해당되는 조건이다.
- 재귀 호출을 할 때에는 반드시 '탈출 조건'이 필요하다.
- 탈출 조건이 없으면, 재귀 호출은 무한히 계속된다.
- 반복문에서도 while 뭐시기 하면서 탈출 조건을 반드시 달아놓는다. 이게 없으면 무한 루프에 빠지게 된다.
- 점화식에 의거하여 재귀 호출을 수행한다.
- 입력 파라미터를 달리하여, 결국 탈출 조건에 도달할 수 있게 한다.
- 반복문에서도 특정 변수를 계속 증가하게 하거나, 특정한 iterate한 조건을 달아서 반복되면서 탈출 조건에 가까워지게 구현한다.
def fibonacci(n):
if n < 2: # 탈출 조건
return n
return fibonacci(n-1) + fibonacci(n-2) # 재귀 호출(점화식 구현)분할정복
퀵소트
def quick_sort(x):
if len(x) <= 1:
return x # 잘린 배열의 길이가 1 이하일 경우 정렬이 필요없으므로 return
pivot = len(x) // 2 # 중앙값을 사용, 어딜 사용하던 상관은없지만 중앙값이 일반적임
left_arr, right_arr = [], [] # 피벗을 기준으로 정렬될 배열을 만들어줌
for i in range(len(x)):
if x[i] > x[pivot] and i != pivot:
left_arr.append(x[pivot])
# 피벗보다 지금 보는 값이 작을 경우
elif x[i] <= x[pivot] and i != pivot:
right_arr.append(x[pivot])
# x 배열에 pivot도 포함이 되어있으므로 반드시 pivot 인덱스는 제외해주어야 함.
return quick_sort(left_arr) + [x[pivot]] + quick_sort(right_arr)
재귀 호출의 한계
- 여러번 재귀 호출이 발생하는 경우, 기하급수적으로 호출 횟수가 증가한다.
- 함수 호출 스택(Function call stack)의 크기에 제한이 있어, 일정 횟수 이상 호출이 불가하다. (파이썬의 경우 1000번 이하 - 강제로 늘릴 수는 있음)
- 실질적인 계산에 필요한 연산보다, 함수 호출에 의한 Overhead가 발생한다.
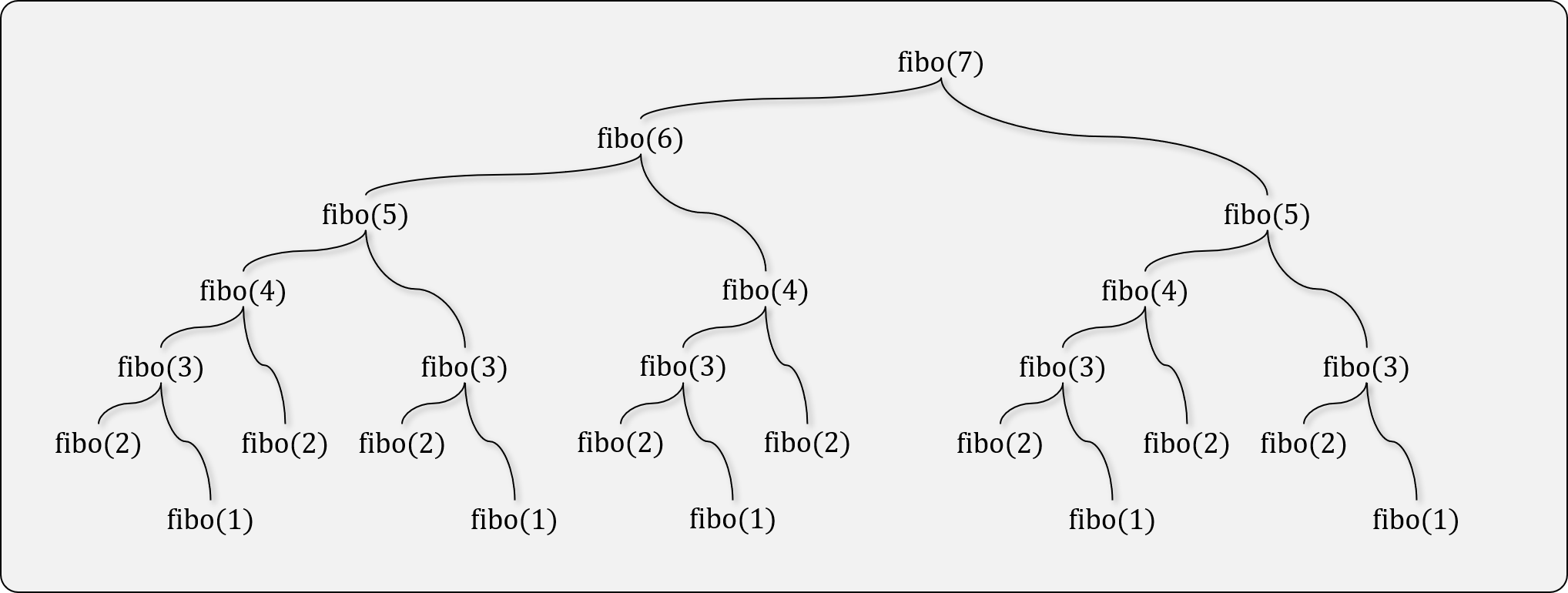
memoization
위의 문제를 해결하기 위해서 memoization 기법이라던지 다양한 해결방법을 도입한다. 특히 재귀식이 아니면 구현하기 까다로운 dp나 dfs 문제들은 stack이나 memoization 을 이용해서 재귀식을 구현하고, 최적화를 통해 성능을 챙기는 방법을 사용한다.
Tail recursion
위에서 함수 호출 자체가 굉장히 오버헤드가 큰 작업이라고 했고, 이 때문에 재귀 함수가 비효율적이라고 언급했다. 이를 해결하기 위한 또 하나의 방법이 tail recursion이다.
Tail recursion이란, 재귀 함수에서, 재귀 호출이 마지막에 단 한번 수행되는 것을 의미한다.
구체적으로 얘기하자면, 재귀 함수를 들여다보면 return 문이 두 개가 존재한다. 탈출 조건의 return 문과 일반 문들이 끝날 경우 다시 자신을 호출한 함수로 돌아가는 return 문이 존재한다. 이 return 문을 마지막에 선언했을 때, 어차피 함수는 이 리턴문을 마지막으로 해당 함수가 종료되고 사라질 것을 알고 있다. 때문에 함수 호출을 새로 하는 것이 아닌, 해당 함수를 재사용해서 그 즉시 함수를 overwrite 해버리는 기법이 tail recursion이다.
- 재귀 호출이 여러번 발생하는 경우, Tail Recursion 기법으로 재귀 횟수를 줄일 수 있다.
- 컴파일러에서 Tail Recursion 최적화를 지원하는 경우, 함수 호출 스택을 낭비하지 않을 수 있다.
- 재귀 호출 이후에는 함수에서 할 일이 남아있지 않으므로, 함수 호출 스택을 재활용한다.
- 컴파일러에서 최적화를 지원하지 않으면 적용되지 않는다. (Python은 미지원)
def fibonacci(n, a=0, b=1):
if n == 0:
return a
if n == 1:
return b
return fibonacci(n-1, b, a+b)위 처럼 생겼을 때 컴파일러에서 tail recursion을 지원하면 해당 기능을 사용할 수 있다.
