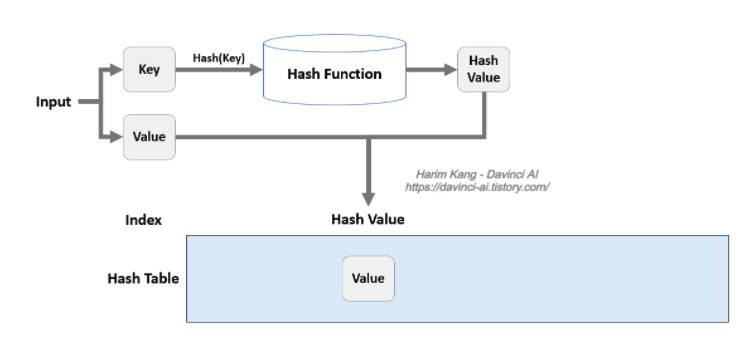
Hash Table
대량의 정보를 저장하고 특정 요소를 효율적으로 검색할 수 있는 복잡함 데이터 구조로, 테이블 내에 더 작은 서브 그룹인 버킷-배열(bucket)에 key(hash-index) - value를 한쌍으로 저장한다.
- 키(매핑전 원래 데이터 값)를 해시 함수로 해싱(hashing)하여 해시값이라는 고유한 숫자값(index)으로 변환하여 저장하고, 해시 숫자가 버킷의 index로 실제 값이 저장되는 버킷을 가리킨다. (매핑하는 과정 전체를 해싱이라고 한다)
- 원하는 값의 검색이 빠르고 효율적이지만, 공간을 일정 이상 늘어난다면 심각한 성능 저하를 나타낸다.
=> 대부분의 연산의 시간 복잡도는 O(1)이다. - 필요할때만 메모리 크기를 늘리고 가능한 작은 크기를 유지하는게 좋다.
- 해시값의 충돌이 최소화되고 해시 테이블 전체에 균일하게 분포되는 해시함수가 좋은 해시함수다.
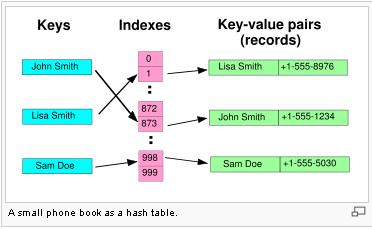
용어
- Hash
- 임의 값을 고정 길이로 변환하는것을 의미한다.
- Hash Function
- 특정 연산을 이용하여 키 값을 받아서 해시 값을 가진 공간의 주소로 바꿔주는 함수이다.
- Hash Table
- 해시 구조를 사용하는 데이터 구조이다.
- Hash value(or Address)
- key를 해시 함수에 넣어서 얻은 주소 값이다.(index)
- 실제 데이터가 담긴 버킷을 가리킨다.
- bucket(or slot)
- 한개의 데이터를 저장할 수 있는 공간을 의미한다.
해시 함수
일반적으로 modular연산을 이용한다.
key mod m 일 때, m이 해시 테이블 크기이다.
- m은 2의 멱수(거듭제곱수)에 가깝지 않은 소수가 좋다.
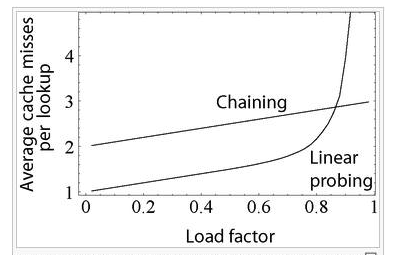
Load Factor
해시 테이블에 저장된 데이터 개수 n을 버킷의 개수 k로 나눈 것이다.
loadFactor = n / k
- 로드 팩터의 비율에 따라서 해시 함수를 재작성할지, 해시 테이블의 크기를 조정할 지 결정한다.
- 일반적으로 로드 팩터가 증가할수록 테이블 성능이 점점 감소하게된다.
- 로드 팩터는 언어마다 기본값이 다르고 Python = 0.66 / Java = 0.75 등
Hash 충돌시 해결하는 두가지 방법
-
Separate Chaining
- 추가 메모리를 사용하여 다음 데이터의 주소를 저장하는 것이다. (연결 리스트인 것이다.)
- 해시 테이블의 확장이 필요없고 간단하게 구현되고 삭제할 수 있다.
- 데이터가 많아지면 동일한 버킷에 연결되는 데이터가 많아지기 때문에 캐시의 효율성이 감소하고 최악의 경우 시간 복잡도가 O(N)까지 증가할 수 있다.

-
Open Addressing (세가지 방법이 있다.)
a. Linear Probing (선형 탐사)
- 최초 해시값의 버킷에 다른 데이터가 있다면 해당 해시 위치에서 고정폭만큼 이동하며 검색해 다음 해시에 버킷이 비어있다면 엑세스하고, 데이터가 있다면 반복되는 것이다.

b. Quadratic Probing
- 해시의 저장 순서 폭을 제곱으로 저장하는 방식이다.

c. Double Hashing Probing
- 해시의 값을 또 해싱하여 해시의 규칙성을 없애버리는 방식이다.

- 최초 해시값의 버킷에 다른 데이터가 있다면 해당 해시 위치에서 고정폭만큼 이동하며 검색해 다음 해시에 버킷이 비어있다면 엑세스하고, 데이터가 있다면 반복되는 것이다.
Hash map 구현
import collections
class ListNode:
def __init__(self, key=None, value=None):
self.key = key
self.value = value
self.next = None
class MyHashMap:
# 초기화
def __init__(self):
self.size = 1000
self.table = collections.defaultdict(ListNode)
# 삽입
def put(self, key: int, value: int) -> None:
index = key % self.size
# 인덱스에 노드가 없다면 삽입후 종료
if self.table[index].value is None:
self.table[index] = ListNode(key, value)
return
# 인덱스에 노드가 존재하는 경우 연결리스트로 처리
p = self.table[index]
while p:
if p.key == key:
p.value = value
return
if p.next is None:
break
p = p.next
p.next = ListNode(key, value)
def get(self, key: int) -> int:
index = key % self.size
if self.table[index].value is None:
return -1
# 노드가 존재할때 일치하는 키 탐색
p = self.table[index]
while p:
if p.key == key:
return p.value
p = p.next
return -1
def remove(self, key: int) -> None:
index = key % self.size
if self.table[index].value is None:
return
# 인덕스의 첫번째 노드일때 삭제 처리
p = self.table[index]
if p.key == key:
self.table[index] = ListNode() if p.next is None else p.next
return
# 연결 리스트 노드 삭제
prev = p
while p:
if p.key == key:
prev.next = p.next
return
prev, p = p, p.nextReference

요리사에서 프론트엔드 개발자를 준비하는중 입니다.