힙 정렬(Heap Sort)
- 힙 트리 구조를 이용하는 정렬 방법
- 추가 배열이 필요하지 않아 메모리 측면에서 효율적
- 단순 속도만 비교한다면 퀵정렬이 평균적으로 더 빠르다.
- 최솟값이나 최댓값을 빠르게 찾을 수 있다.
- 힙정렬을 하기 위해서는 정해진 데이터를 힙구조를 가지도록 만들어야 한다. (Heapify Algorithm)
- Heapify Algorithm -> 힙구조 만들기
- shift Down -> 정렬하기
힙구조란 무엇일까?
-
최소힙과 최대힙이 존재한다.
최대힙 : 완전 트리이면서 루트가 모든 경우에 자식들보다 커야한다.
-
모든 노드가 최소힙이나 최대힙 구조를 만족하는 완전 이진 트리를 기반으로 하는 트리구조
트리
가지를 뻗어나가는 것 처럼 데이터가 서로 연결되어 있다.
이진 트리
- 컴퓨터 안에서 데이터 표현 시 데이터를 각 노드에 담은 뒤 노드를 두 개씩 어어 붙이는 구조
- 모든 노드의 자식 노드가 2개 이하인 노드
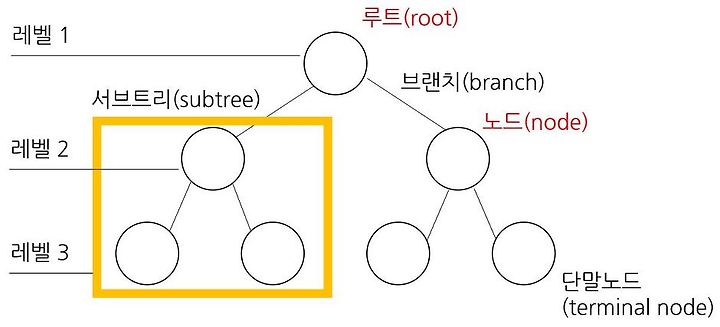
- 단말노드를 리프(Leaf) 라고도 함
완전 이진 트리
- 데이터가 루트 노드부터 시작해서 자식 노드가 왼쪽 자식 노드, 오른쪽 자식 노드로 차례대로 들어가는 구조
- 이진 트리의 노드가 중간에 비지 않고 가득 찬 구조
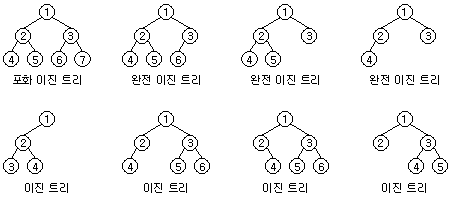
- 포화 이진 트리 : 리프 노드를 제외한 모든 노드가 자식을 둘씩 가지고 있는 구조
- 완전 이진 트리 : 잎 노드들이 트리 왼쪽부터 차곡차곡 쌓여진 트리
힙 생성 알고리즘 (Heapify Algorithm)
힙정렬을 수행하기 위해 힙 생성 알고리즘을 사용한다.
- 자식이 있는 노드만 실행하면 되기 때문에 Math.floor(arr.length / 2) 번만 실행해 주면 된다.
- 특정 노드의 두 자식중 더 큰 자식과 자신의 위치를 바꾸는 알고리즘
- 위치를 바꾼 뒤 바꾼 노드의 자식이 존재하는 경우 바꾼노드와 자식의 크기를 비교해서 또 위치를 바꾼다. (자식이 더이상 존재하지 않을 때 까지 반복)
힙 생성 알고리즘(Heapify Algorithm) 방법
-
Math.floor(n / 2) 번 노드 부터 시작한다.
-
루트 노드일때 까지 반복한다.
2-1. siftDown을 실행한다.
2-2. 이전 노드로 인덱스를 줄인다.
siftDown 방법
-
siftDown을 수행 할 노드의 인덱스를 인자로 받아 큰 값을 인덱스로 설정한다.
-
왼쪽 자식노드가 존재하고 큰 값보다 왼쪽 값이 더 크면
2-1. 큰 값은 왼쪽 자식 노드가 된다.
-
오른쪽 자식노드가 존재하고 큰 값보다 오른쪽 값이 더 크면
3-1. 큰 값은 오른쪽 자식 노드가 된다.
-
큰 값이 현재 수행 할 노드의 인덱스가 아니면
4-1. 현재 인덱스 값과 큰 값의 위치를 바꾼다.
4-2. 큰 값의 인덱스부터 다시 siftDown을 실행한다.
힙 정렬 방법
-
Heapify를 실행한다.
-
마지막노드 인덱스가 루트노드 인덱스보다 클때까지 반복한다.
2-1. 마지막 노드와 루트노드의 위치를 바꾼다.
2-2. 루트노드부터 다시 siftDown을 실행한다.
2-3. 마지막 노드의 인덱스를 하나 줄인다.
시간복잡도
O(N * log N)
코드

프론트엔드 개발자입니다 :)