데이터분석가 특강
#1 데이터 분석 업무 해부
- 데이터분석 왜 하는걸까?
-> 의사결정
-> 조직원들의 합의를 이끌어낼 수 있음
2. 데이터분석이 필요한 예시
-
대학생들이 많이 사는 지역에 카페를 열면 장사가 잘될까?
-
영어 교육 앱의 실제 효용 증명 (샘플링 고려 필요)
-
매출 하락 원인 분석 (논리적 사고 필요)
-> 로직트리 (매출을 쪼개서 문제 부분 찾기 위해 비교하기)
3. 데이터분석을 위해 필요한 과정
- 문제 정의
- 데이터 만들기 (인프라 잘 구축되어 있지 않다면)
- 데이터 선별, 조회
- 가설 검증
- 결과 공유
4. 데이터로 일하는 조직이 되기 위해 필요한 것
- 데이터분석을 위한 인프라
- 데이터 리터러시: 구성원들이 데이터를 보고 이해/소통할 수 있는 역량
5. 데이터 직군
- 프로덕트가 안정적으로 돌아가는지
-> 백엔드, 데이터 엔지니어 - 고객이 어떻게 행동했는지 중간 로그가 더 궁금
-> 데이터분석가
포폴 정리할 때
왜 했고 결과가 뭔지, 뭘 했다는 건지 잘 정리되게
- 결과, 인사이트를 담은 프로젝트 -> 포트폴리오
- 어려움(문제 해결) -> 자기소개서, 면접
이직, 동기의 확고함 (왜 여기로 오고 싶은지 + 거기서 나오고 싶은 이유) -> 설득
다섯명이라는 게 의미있는 숫자는 아니지만
인터뷰 질문의 깊이로 이 사람이 이거에 얼마나 해봤는지 알 수 있음
분석가 뿐만 아니라 기획자들도 높진 않더라도 분석역량 갖췄으면 싶음
기업 탐색시 데이터 리터러시를 갖췄다를 알 수 있는 방법 -> 채용공고 분석 (요구하는 게 구체적이고 다양함, 여기서 무슨일 하는지 보이는 기업)
논리적 사고 훈련 실습
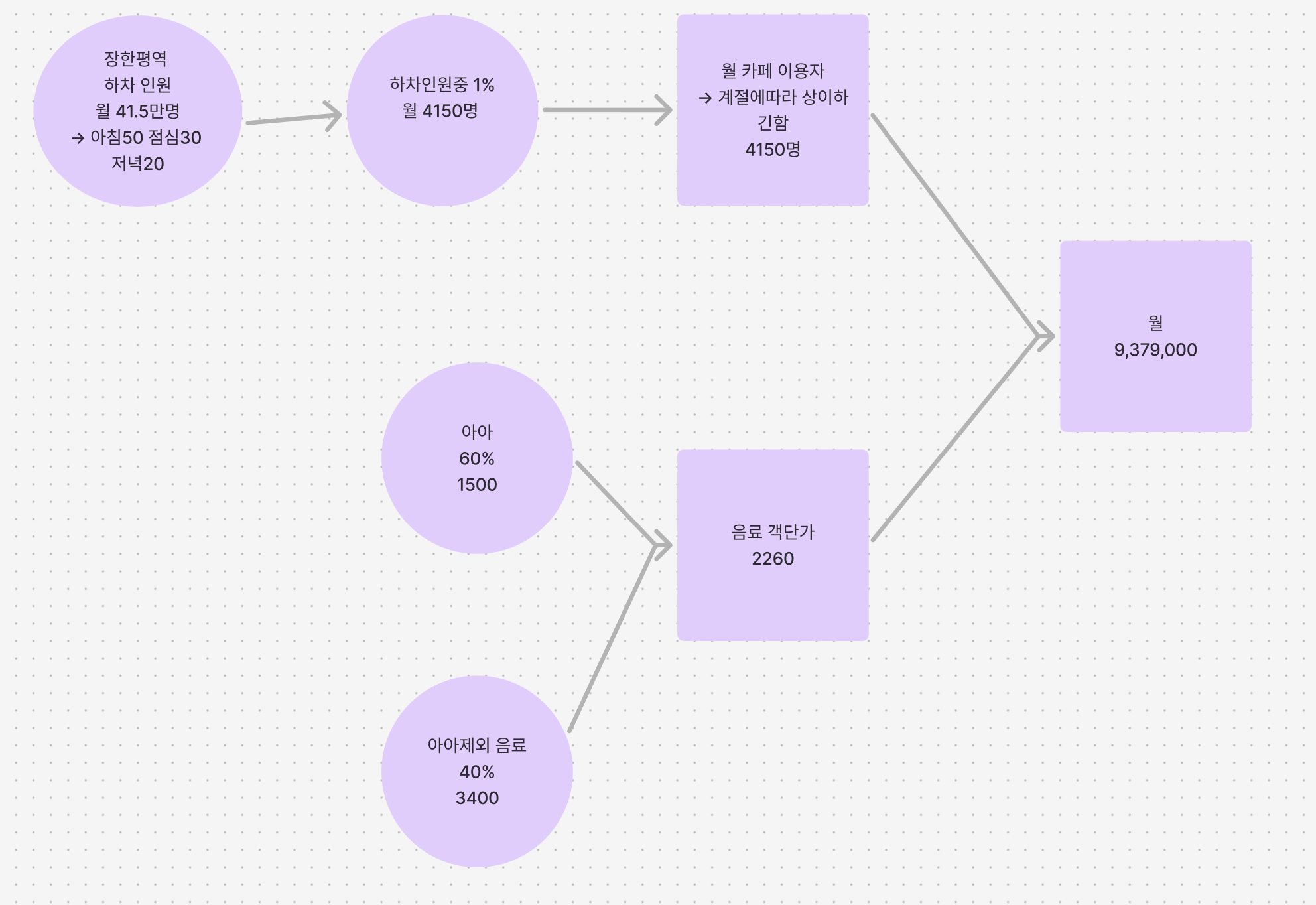
Q. 카페 연 매출은 얼마일지 추정해봅시다.
데이터 수집 방법과 논리 제안
페르미 추정
객 단가 * 평균 인원
장한평역으로 도착하는 요동인구 데이터
-> 평일 오전~점심, 영업일(휴무 파악) + 월 매출 계산할 때 계절도 고려
서울시 지하철 호선별 역별 시간대별 승하차 인원 정보 (http://data.seoul.go.kr/dataList/OA-12252/S/1/datasetView.do)
커피전문점 메뉴 분석 리포트
(https://data-lab.kcd.co.kr/reports/5)
-
역 하차인원
연 41만 5천
7~10시 사이 12만 -
시간대별 매출 비율
오전 50%
점심 30
저녁 20 -
판매 매출 비율
아아 60% 1500원
나머지 40% 3400원
하차인원 중 1%만 카페를 이용한다는 가정
예측 방법
-
전체 시장에 대한 -> 장한평역 예측
(비율 가정 근거 필요) -
1시간 샘플링에서 -> 장한평역으로 확장
(샘플링 시간대에 대한 고려 필요)
카페 시즌을 많이 탐
여름엔 얼음값 때문에 비싸짐
도메인 지식 - 카페업에 매출에 영향을 미치는 요소 필요
기업 특징 알기 위한 사이트 추천
-
혁신의 숲 -
벤처공시 > 재무정보 > 손익계산서 > 매출, 판매비와 관리비
-> 3년간 정보 매출액 증가 & 비용 증가 비례 여부 파악ex) 매출 & 급여비 같이 늘면 채용 많이 했구나 (수요가 많은 회사))
#2 인과 관계
1. 인과관계 예시
-
디지털 광고 VS 오프라인 광고
-
커머스 프로덕트 UI AB테스트
-
재고 확보 예측
(이전 데이터를 기반으로 예측 시
-> 과거의 추세가 이어지려면 성장하는 시장이어야하고, 과거 변수와 아주 동일해야함)
상관관계는 있지만 인과관계는 없다
- 상관관계: 원인과 결과가 아니라 같이 가는 상관성
데이터 분석시 잘못된 인과관계가 나오면 역효과가 난다
2. 인과관계 파악의 원리
처치효과(=개입효과): 액션이 만들어낸 효과
ex)
광고를 본다 > 한달에 20개 삼
광고를 안본다 > 한달에 10개 삼
-> 광고로 인한 처치효과 10개 증가
3. '랜덤'을 활용해 극복하기
- 가능하면 동일한 조건의 고객으로 (광고시청 유무만 다른)
- 집단으로 보기
무작위 대조 시행(RCT): 집단을 무작위로 나눠 각 집단의 평균 처치효과를 측정하는 방식
AB테스트 or 비교할 때 랜덤 활용하기
인과 관계 실습
Q. 캐치테이블의 예약금 환불 불가로 할 때 예약 취소가 줄어들지 실험
서비스 빈도 동일해야
인과관계를 파악할 수 있음
a집단: 취소율 높은 사람 (취소 불가 전달)
b집단: 취소율 낮은 사람
a집단이 예약 취소가 줄어들지 보려면
동일하게 해야하는 변수는?
-> 예약 시기, 선호하는 음식 카테고리, 서비스 만족도, 이용 빈도, 평일, 식당 위치, 유행병, 사회적 이슈, 가게 이슈, 웨이팅 숫자, 예약금 금액, 연령대, 성별, 날씨
사후 검증 할 때 랜덤 활용시
데이터 불균형 주의해야함 (사전에 최대한 필터링)
변수에 영향을 미친는 요소를 찾았으니 고려해서 집단을 나누려면 필요한 데이터 수집 방법은?
고객의 개인사정
-> 취소시 적는 취소사유 수집
동행자 정보
-> 수집하려면 예약시 미리 정보 수집
외부이슈
-> 뉴스 수집, 위치 정보, 날씨 정보
날짜, 시간, 요일, 웨이팅 수
-> 가게 요청해서 수입
재방문 여부, 연령대, 성별
-> 회원정보
#3 통계적 유의성
큰 수의 법칙: 샘플을 모을수록 점점 평균에 근접해진다
1. 유의성 검정의 원리
-
귀무가설
내 주장은 이건데
내 주장이 아니라고 해보자 (귀무가설)
-> 귀무가설이 틀렸다는 걸 증명하면 내 주장을 뒷받침할 근거가 됨 -
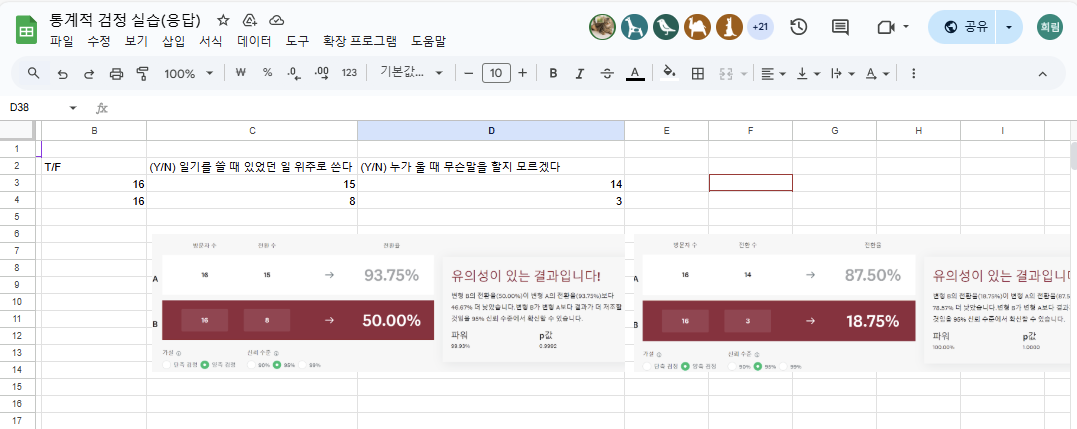
p-value 유의확률
유의 수준(0.05)보다 낮으면 가설이 틀렸다 (귀무가설 기각)
-> 내 주장이 맞다
느낀점
실제로 지난 학기에 ~의 변동 요인 분석 프로젝트를 했었는데 상관관계를 확인해 결과로 나타냈던 것이 생각이 남. 그 주제엔 인과관계를 파악했어야 하는 것이 아닌가 싶음
분석 과정에서 의미 있는 의사결정, 인사이트를 내기 위해 잘못된 인과관계를 내지 않도록 주의 필요
AB테스트를 위해 고려해야 할 변수 조건들이 정말 많구나를 새삼 느낌. 실제로 위에서 진행했던 프로젝트에 '인구 수도 고려해야 하는 거 아니냐'는 질문을 받았었는데 듣고 아차 싶었던 기억이 남.. 그땐 최종 발표 때라 어쩔 수 없어서 그냥 지나갔는데 이번에 다시 실습했으니 잘 기억해두기
