바이트 패딩
컴파일러는 성능 향상을 위해 CPU가 접근하기 쉬운 위치에 필드를 배치하게 되는데 이 때문에 중간에 빈 공간이 생기게 됨.
이것을 바이트 패딩이라고 함.
struct MEMBER
{
char Name; // 1Byte
int Age; // 4Byte
};위의 구조체는 char(1Byte) + int(4Byte) = 5Byte의 사이즈를 가지고 있지만 실제 CPU가 구조체 메모리를 읽을 땐 8Byte를 읽어오는데 이때 추가된 3Byte가 바이트 패딩이다.
CPU가 메모리를 읽어올 때 32bit OS에선 4Byte, 64bit OS에선 8Byte를 읽어온다.
64-Bit 운영체제에선 대부분 컴파일러는 데이터 멤버를 자동으로 정렬하여 CPU에서의 접근을 최적화 하려고 한다.
OS에선 구조체 내의 가장 큰 자료형을 기준으로 정렬하는데 위의 경우 가장 큰 자료형의 크기가 4Byte이므로 4Byte로 정렬된다.
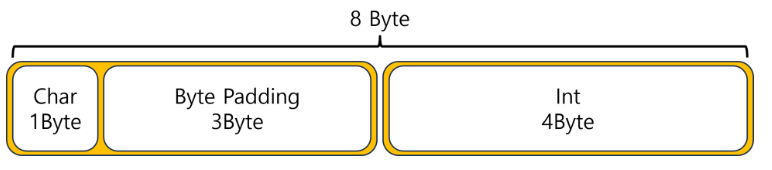
char형은 1Byte에 3Byte가 패딩되어 4Byte 크기를 맞춰준다.
따라서 구조체의 크기는 8Byte가 된다.
이러한 바이트 패딩은 구조체 변수의 위치에 따라서도 할당되는 메모리 크기가 달라질 수도 있는데,
struct MEMBER
{
char A; // 1Byte
int B; // 4Byte
long long C; // 8Byte
};위와 같은 구조체는 멤버변수중 가장 큰 자료형의 크기가 8Byte이고 순서대로 메모리 할당이 이뤄지는데, char(1Byte) + 7Byte , long long(8Byte), int(4Byte) + 4Byte즉, 총 24Byte 메모리가 할당된다.
struct MEMBER
{
long long C; // 8Byte
char A; // 1Byte
int B; // 4Byte
};순서를 바꾸어서 위와 같은 코드로 구현한다면 long long(8Byte), char(1Byte) + int(4Byte) + 3Byte 즉, 16Byte가 된다.
바이트 패딩으로 인해 구조체의 크기가 달라지는 점은 구조체를 전송할 때 중요한 문제가 된다.
운영체제와 컴파일러에 따라 구조체의 메모리가 정의되는 형태가 달라지는데, 이 문제를 해결하기 위한 방법으로 #pragma pack() 또는 직접 패딩 비트 넣어주기 를 통해 해결할 수 있다.
이 두가지 방법은 동일 플랫폼에서만 사용이 가능하므로 직렬화 과정을 거쳐 구조체를 송수신 하는 것이 가장 좋다.
직렬화 : 데이터를 바이트 스트림 또는 다른 형식으로 변환하여 저장하거나 전송하기 위한 과정
#pragma pack()
#pragma pack을 부르는 명칭은 Word Alignment이다.
64bit 프로세서 기반에서 데이터 처리를 위해 사용되는 버스가 8바이트이지만, #pragma pack(1)을 사용하면 데이터 처리를 위해 사용되는 버스를 1Byte로 정의한다.
잘 사용한다면 구조체 메모리를 낭비없이 사용할 수 있다.
수행속도가 느려지는 단점이 있지만 최근 하드웨어 사양에선 크게 문제가 되지않는다.
오히려 메모리가 중요한 임베디드 분야에선 유용하게 사용된다.
#pragma pack(push, n) | #pragma pack(pop)
#pragma pack(push, n)
struct MEMBER
{
long long C;
int A;
char B;
};
#pragma pack(pop)위와 같이 선언하게 되면 데이터의 정렬이 바뀐다.
pack(push, n)은 데이터 정렬 기준을 1Byte로 한다는 것이고, #pragma pack(pop)을 안하게 되면 # pragma pack(push, n)선언 이후의 변수 선언에 전부 적용이 됨.
이를 잘 신경써서 코드를 구현해야 한다.
