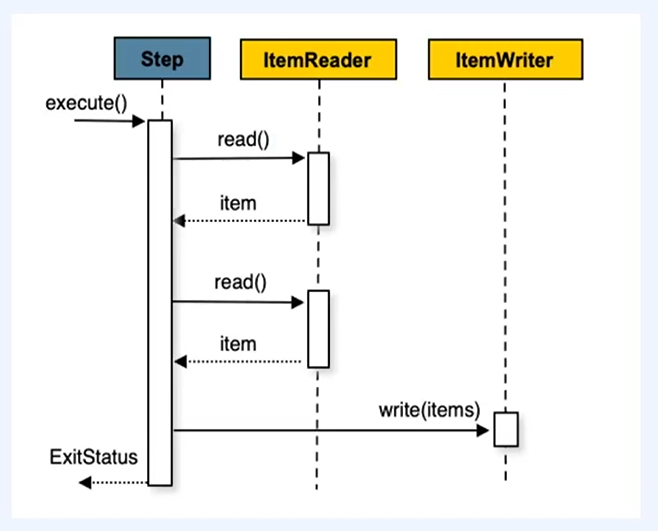
만료된 이용권을 Chunk 방식을 사용하여 처리하려고 함
Chunk
- 데이터 덩어리로 작업 할 때 각 커밋 사이에 처리되는 row 수
- 한 번에 하나씩 데이터를 읽어 Chunk라는 덩어리를 만든 뒤, Chunk 단위로 트랜잭션
- 실패할 경우엔 해당 Chunk 만큼만 롤백이 되고, 이전에 커밋된 트랜잭션 범위까지는 반영됨
Chunk-oriented Processing(청크 지향 처리 방식)
- 한번에 하나의 데이터를 읽어 들인다음, 하나의 트랜잭션 범위내에서 처리할 청크(chunks)들을 생성하여 chunk 단위로 트랜잭션 처리하는 것
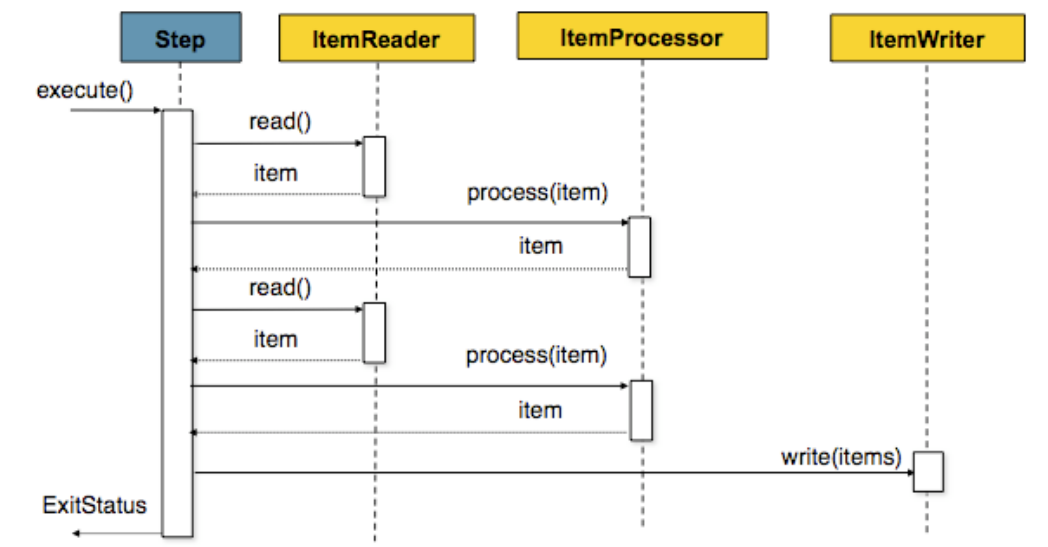
- ItemReader 가 하나의 아이템을 읽어 들임
- 그 아이템은 ItemProcessor 통하여 한곳으로 모여지게 됨
- 읽어들인 아이템의 숫자가 설정해 놓은 한번에 커밋할 갯수와 동일하게 되면 전체 청크가 ItemWriter 에 의해 처리되고 그 다음 트랜잭션이 커밋됨
Chunk-oriented Processing의 구성요소
-
ChunkOrientedTasklet: Chunk 지향 프로세싱을 담당하는 Tasklet의 구현체로 TaskletStep에 의해 반복적으로 실행되며 매번 새로운 트랜잭션으로 생성되어 처리됨. 예외가 발생할 경우 해당 Chunk는 롤백되며 이전에 커밋한 Chunk는 완료된 상태로 유지. 내부적으로 ChunkProvider와 ChunkProcessor 구현체를 가짐
-
ChunkProvider: ItemReader를 사용해 소스로부터 아이템을 chunk size만큼 읽어 Chunk 단위로 만들어 제공하는 객체로 만들고 내부적으로 반복문을 이용해 ItemReader의 read()를 계속 호출해 item을 Chunk에 쌓아 둠. ChunkProvider가 호출될 때마다 항상 새로운 Chunk가 생성됨
-
ChunkProcessor: ItemProcessor를 사용해 item을 변형/가공하여 ItemWriter를 이용해 Chunk 데이터를 저장하거나 출력함. Chunk를 만들고 앞에서 넘어온 Chunk의 item을 한 건씩 처리해 Chunk에 저장함. 외부로부터 ChunkProcessor가 호출될 때마다 새로운 Chunk가 생성됨
-
ItemReader: 다양한 입력으로부터 데이터를 읽어 제공하는 인터페이스. 입력 데이터를 읽고 다음 데이터로 이동함. 아이템 하나를 리턴하며 더 이상 아이템이 없는 경우 null을 리턴함.
-
ItemWriter: Chunk 단위로 데이터를 받아 일괄 저장하거나 출력하는 인터페이스. ItemWriter는 단위로 아이템 하나가 아니라 Chunk를 전달 받고 이 Chunk는 List와 같은 형식임. 출력 데이터를 아이템 리스트로 받아 처리하고 작업이 완료되면 트잰잭션이 종료되고 새로운 Chunk 단위 프로세스로 이동함
-
ItemProcessor: 데이터를 출력하기 전 데이터를 가공/변형/필터링하는 인터페이스. ItemReader와 ItemWriter와 분리되어 비즈니스 로직을 구현할 수 있고 ItemReader로 부터 받은 아이템을 다른 타입으로 변환해 ItemWriter에 넘기거나 필터링해 원하는 데이터만 넘길 수도 있음. 반드시 필요한 작업이 아닐 수도 있기 때문에 ChunkOrientedTasklet 실행 시 선택적으로 구성할 수 있음
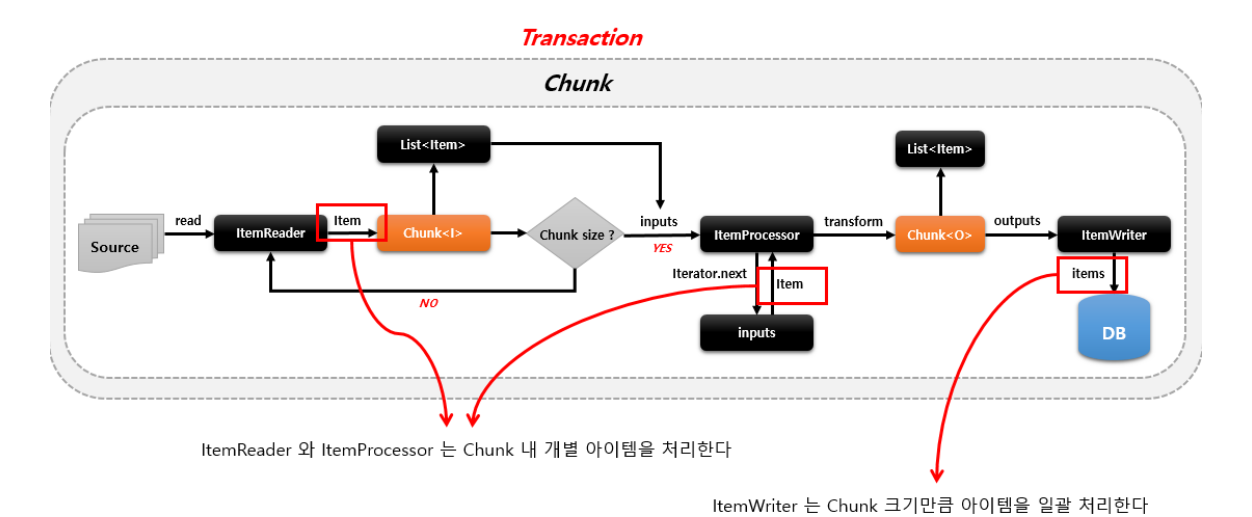
ItemReader는 데이터를 하나씩 읽고, 더 이상 읽을 게 없다면 결과물이 담긴 Chunk를 ItemProcessor에 넘김. 그리고 ItemProcessor는 반복문을 통해 ItemReader에서 전달받은 Chunk에 대한 작업을 하고 Chunk에 담아 ItemWriter로 전달하고 ItemWriter는 받은 이 Chunk(List)를 일괄 처리하게 됨. 즉, ItemReader와 ItemProcessor는 item 단위로 개별 처리하고, ItemWriter는 Chunk 단위로 일괄 처리함
Spring Batch 가 제공하는 Reader

1) Cursor 기반 ItemReader
- Cursor는 JDBC ResultSet의 기본 기능으로 ResultSet이 open 될 때마다 Database의 데이터가 return됨
- Database와 커넥션을 맺은 후 데이터를 Streaming해서 보내고 Cursor를 한칸씩 옮기면서 데이터를 가져옴
- 구현체: JdbcCursorItemReader, HibernateCursorItemReader, StoredProcedureItemReader
2) Paing 기반 ItemReader
- 페이지 단위(pageSize=chunkSize)로 한번에 데이터를 조회해오는 방식
- 각 페이지의 쿼리를 실행할 때마다 동일한 레코드 정렬 순서를 보장하려면 정렬 조건이 필요함
- 구현체: JdbcPagingItemReader, HibernatePagingItemReader, JpaPagingItemReader
@Configuration
@RequiredArgsConstructor
public class ExpirePassesJobConfig { // 만료된 이용권 처리
private final int CHUNK_SIZE = 5; //트랜잭션 마다 5개씩 처리
private final EntityManagerFactory entityManagerFactory;
private final PlatformTransactionManager transactionManager;
private final JobRepository jobRepository; // 커밋 직전에 StepExecution과 ExecutionContext 를 주기적으로 저장
@Bean
public Job expirePassesJob(){
return new JobBuilder("expirePassesJob",jobRepository)
.start(expirePassesStep())
.build();
}
@Bean
public Step expirePassesStep(){
return new StepBuilder("expirePassesStep",jobRepository)
.<PassEntity,PassEntity>chunk(CHUNK_SIZE,transactionManager)
.reader(expirePassesItemReader())
.processor(expirePassesItemProcessor())
.writer(expirePassesItemWriter())
.build();
}
@Bean
@StepScope
public JpaCursorItemReader<PassEntity> expirePassesItemReader(){//만료된 PassEntity를 읽어옴
return new JpaCursorItemReaderBuilder<PassEntity>()
.name("expirePassesItemReader")
.entityManagerFactory(entityManagerFactory)
.queryString("select p from PassEntity p where p.status = :status and (p.endedAt <= :endedAt or p.remainingCount = 0)")
.parameterValues(Map.of("status", PassStatus.IN_PROGRESS,"endedAt", LocalDateTime.now()))
.build();
}
@Bean
public ItemProcessor<PassEntity,PassEntity> expirePassesItemProcessor(){//PassEntity 의 상태와 만료 시간을 변경
return passEntity -> {
passEntity.updateExpiredStatus();
passEntity.updateExpiredTime();
return passEntity;
};
}
@Bean
public JpaItemWriter<PassEntity> expirePassesItemWriter(){//변경된 PassEntity를 저장
return new JpaItemWriterBuilder<PassEntity>()
.entityManagerFactory(entityManagerFactory)
.build();
}
}- paging 아닌 cursor 방식의 ItemReader 를 사용하는 이유
데이터 변경에 무관한 무결성 조회가 가능하기 때문에 status 가 'IN-PROGRESS'인 pass 를 읽어 와서 'EXPIRED'로 변경하는데 페이징해서 가져오면 과정 중에 pass가 누락이 될 수 있음
EX) 데이터가 50개 있고 status='true'를 모두 'false'로 변경하려고 할 때 10개씩 paging 방식으로 읽어와서 처리한다면 'SELECT * FROM Pass
WHERE status = true offset 0 limit 10' 가 실행되고 1-10번까지의 데이터는 status가 'false'로 변경됨. 그 다음 10개를 처리할 때 'SELECT * FROM Pass
WHERE status = false offset 11 limit 10'가 실행되고 11-20 번째 데이터가 처리되어야 하지만 남은 40개의 데이터 중 11 limit 10 이기 때문에 실제로는 21-30 번까지의 데이터가 처리되어 11-20 번 데이터는 누락됨 만료된 이용권 처리 테스트
@Configuration
@EnableJpaAuditing
@EnableAutoConfiguration
@EntityScan("com.example.ptproject.domain")
@EnableJpaRepositories("com.example.ptproject.repository")
@EnableTransactionManagement
public class TestBatchConfig {
}@SpringBootTest
@SpringBatchTest
@ActiveProfiles("test") //application-test.yml
@Slf4j
@ContextConfiguration(classes = {ExpirePassesJobConfig.class, TestBatchConfig.class})
public class ExpirePassesJobConfigTest {
@Autowired
private JobLauncherTestUtils jobLauncherTestUtils;
@Autowired(required = true)
private PassRepository passRepository;
@Autowired(required = true)
private UserRepository userRepository;
@Autowired(required = true)
private PackageRepository packageRepository;
@Test
public void test_expirePassesStep() throws Exception {
addPassEntities(10);
JobExecution jobExecution = jobLauncherTestUtils.launchJob();
JobInstance jobInstance = jobExecution.getJobInstance();
Assertions.assertEquals(ExitStatus.COMPLETED,jobExecution.getExitStatus());
Assertions.assertEquals("expirePassesJob",jobInstance.getJobName());
}
private void addPassEntities(int size) { // pass 레코드 10개 insert
final LocalDateTime now = LocalDateTime.now();
final Random random = new Random();
List<PassEntity> passEntities = new ArrayList<>();
for(int i=0; i<size; ++i){
PackageEntity packageEntity = packageRepository.findById(1).orElse(null);
UserEntity userEntity = userRepository.findById("A"+1000000).orElse(null);
PassEntity passEntity = PassEntity.of(
packageEntity,
userEntity,
PassStatus.IN_PROGRESS,
random.nextInt(11),
now.minusDays(60),
now.minusDays(1)
);
passEntities.add(passEntity);
}
passRepository.saveAll(passEntities);
}
}@SpringBootTest→ 통합 테스트 시 사용JobLauncherTestUtils→ Batch Job을 테스트 환경에서 실행할 Utils 클래스, 테스트 코드에서 Job을 실행할 수 있도록 지원jobLauncherTestUtils.launchJob()→ Job을 실행
 이용 종료 기간이 지난 이용권 모두 'EXPIRED' 상태로 변경
이용 종료 기간이 지난 이용권 모두 'EXPIRED' 상태로 변경
