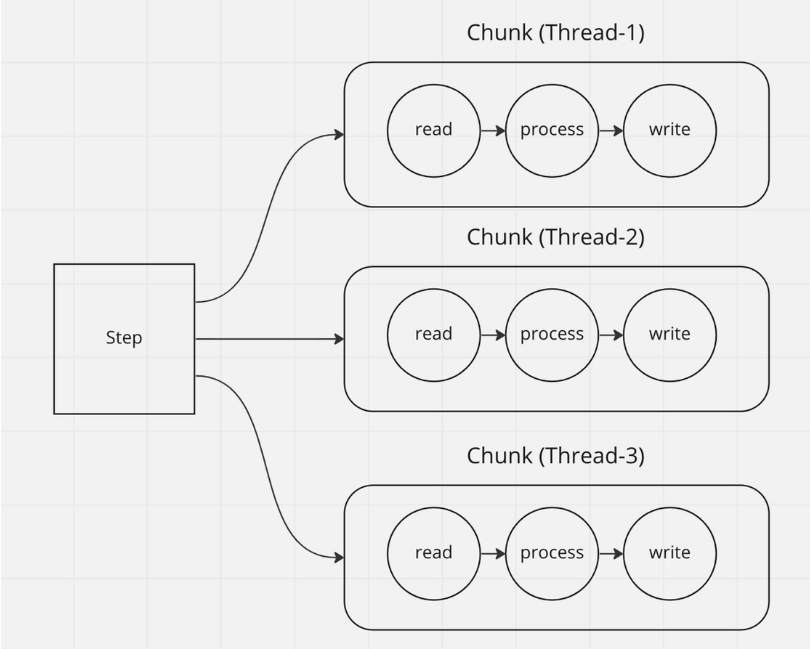
1. Multi-Threaded Step(다중 스레드 스텝)
하나의 Chunk를 하나의 스레드가 담당하는 방식으로 하나의 스레드에서 데이터를 읽고, 가공하고, 쓰는 과정을 처리함
@Bean
public TaskExecutor taskExecutor(){
return new SimpleAsyncTaskExecutor("taskexecutor");
}
@Bean
public Step sampleStep(TaskExecutor taskExecutor) {
return new StepBuiler("Step1",jobRepository)
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.throttleLimit(20)
.build();
}- Step을 구성할 때 TaskExecutor를 지정해주면 됨
- Multi-threaded Step은 Chunk 단위 처리 순서를 보장할 수 없음
- DB connection pool size에 대한 고려가 필요함(Spring Batch에서는 Chunk단위로 트랜잭션이 발생하는데 Multi-threaded Step은 스레드마다 chunk가 할당되어 처리되기 때문에 스레드 수와 비례하여 트랜잭션이 발생하므로 chunk 처리 속도, connection pool size, 실행 스레드 수의 균형을 적절히 맞춰야함)
- Thread Safe한 ItemReader와 ItemWriter를 사용해야함
2. AsyncItemProcessor
process 로직을 병렬로 처리하는 방식

@Bean
public AsyncItemProcessor processor() {
AsyncItemProcessor asyncItemProcessor = new AsyncItemProcessor();
asyncItemProcessor.setTaskExecutor(new SimpleAsyncTaskExecutor()); // 스레드풀 지정
asyncItemProcessor.setDelegate(itemProcessor());
return asyncItemProcessor;
}
@Bean
public AsyncItemWriter writer() {
AsyncItemWriter asyncItemWriter = new AsyncItemWriter();
asyncItemWriter.setDelegate(itemWriter());
return asyncItemWriter;
}- AsyncItemProcessor & AsyncItemWriter을 사용하기 위해서는 spring-batch-integration 의존성을 주입 해야함
- AsyncItemProcessor는 Chunk 내부 처리 로직 중 process에서 새로운 스레드를 만들어 처리함
- process의 처리 결과로 Future를 반환하고 Writer에서 Future의 결과를 종합하여 처리함
- 기존 Processor, Writer는 AsyncItemProcessor, AsyncItemWriter에 위임하여 코드 수정 없이 이러한 동작을 수행할 수 있음(AsyncItemWriter라고해서 writer로직이 병렬 처리되는 것은 아님)
- AsyncItemWriter는 단순히 Future를 취합하여 writer에 전달될 데이터를 모은 뒤 위임된 write메서드를 호출하는 역할을 함
- Chunk단위의 처리 순서 보장됨
- Process예외가 Writer에서 처리됨
AsyncItemProcessor
AsyncItemProcessor는 ItemProcessor를 래핑하는 데코레이터. 실질적인 Process 작업은 새로운 스레드가 ItemProcessor를 실행하고 AsyncItemProcessor 디스패처의 책임을 지니고 AsyncItemProcessor는 Future 타입을 반환함AsyncItemWriter
AsyncItemWriter도 ItemWriter의 데코레이터. AsyncItemProcessor에서 전달된 Future 결과 값을 ItemProcessor에게 위임함3. Parallel Steps(병렬 스텝)
여러 Step을 가질 수 있는 Flow를 병렬로 처리하는 방식
@Bean
public Job makeStatisticsJob(){
Flow addStatisticsFlow = new FlowBuilder<Flow>("addStatisticsFlow")
.start(addStatisticsStep())
.build();
Flow makeDailyStatisticsFlow = new FlowBuilder<Flow>("makeDailyStatisticsFlow")
.start(makeDailyStatisticsStep())
.build();
Flow makeWeeklyStatisticsFlow = new FlowBuilder<Flow>("makeWeeklyStatisticsFlow")
.start(makeWeeklyStatisticsStep())
.build();
Flow parallelStatisticsFlow = new FlowBuilder<Flow>("parallelStatisticsFlow")
.split(new SimpleAsyncTaskExecutor())
.add(makeDailyStatisticsFlow,makeWeeklyStatisticsFlow)
.build();
return new JobBuilder("makeStatisticsJob",jobRepository)
.start(addStatisticsFlow)
.next(parallelStatisticsFlow)
.build()
.build();
}- chunk 내부 로직은 동일한 스레드에서 처리되어 chunk 처리 과정 중 새로운 스레드가 파생되지 않으므로 트랜잭션 관리가 용이함
- 일부 Worker Step 실패 시 다른 Worker step에 영향을 주지 않음
- Chunk 단위 처리 순서를 보장할 수 없음
- Step은 각자의 StepExecution, StepExecutionContext를 가지기 때문에 Step의 처리 상태가 개별적으로 관리되고 업데이트됨
