[논문 리뷰] Toward Unifying Text Segmentation and Long Document Summarization
이 논문은 EMNLP2022에 게재된 논문으로, 모델에게 Text Segmenatation에 대한 정보를 학습하게 해 추출 요약의 성능을 높이는 방법을 제안하고 있습니다.
Abstract
- section segmentation이 문어 및 구어체 원문의 extractive summarization에서 하는 역할에 대해 연구
- 본 논문에서는 summarization과 segmentation을 동시에 수행하는 robust sentence representation에 학습할 뿐만 아니라 optimization-based regularizer을 요약 문장을 다양하게 선택하도록 함
- 과학 논문에서 강의 스크립트까지 다양한 데이터셋에 대해 모델의 성능을 평가
- 널리 사용되는 ROUGE등의 성능 지표에서 SOTA를 달성했을 뿐만 아니라 text segmentation을 같이 할 때 더 나은 cross-genre trasferabiity를 보임
Introduction
-
본 연구에서는 길이가 긴 문서(구어체, 문어체 모두)의 extractive summarization에 대해 초점을 두고 실험을 진행
-
또한, 요약 모델이 section boundaries를 예측하게 함으로써, 긴 문서 요약의 성능을 높이고자 함
-
현재 대다수의 요약은 section이 나눠져 있다는 가정 하에 written document에 집중하고 있지만, 이 방식이 spoken document에도 적용될 수 있는지는 의문
- 1.5시간 비디오 강의의 경우 10000단어 이상의 스트립트를 가짐
- 또한, 스크립트의 경우 section이 나눠져 있지 않음
- 대신, so next we need to.. 와 같은 talking points의 연속으로 lecture content가 구성되어 있음
-
본 연구에서는 이와 같은 단서를 leverage해 spoken과 wrtten documents 둘다 요약을 잘하려 함
-
또한, 본 모델의 경우 동시에 2가지 task(summurization & segmentation)을 하므로 robust sentence representation을 학습 + optimization-based framework를 통해 중요하고 다양한 문장을 선택하려 함
-
section의 boundary를 이미 아는 written document로 모델을 학습한 후에 이를 대본과 같은 spoken document에 적용(adapt)
-
요약에서 핵심은 다양한 내용의 중요한 토픽을 다 담는 것이 중요하므로, 이를 가능하게 하는 새로운 regularizer을 설계
-
데이터셋으로는 과학 기사부터 강의 대본까지 다양한 종류의 문서를 사용했으며, 각 데이터의 평균 길이는 3k-8k가량
-
실험 결과, 본 모델이 SOTA를 달성하였으며, segmentation을 같이 하는 것이 더 나은 transferability를 보임을 증명
contribution
-
written documenets에서 spoken transcript로 transferability할 수 있는 extractive long document summarization을 제안
-
segmentation과 summarization을 둘다 수행하므로 효과적인 문장 표현을 학습
-
공개적으로 이용하능한 summarization benchmark에서 SOTA를 달성
-
왜 segmentation이 장문의 extractive summarization에 도움이 되는지에 대한 일련의 실험을 진행
Our Approach
Sentence represenstation
-
우선 N개의 문장을 갖는 document를 로 표현
-
우리의 목표는 N개의 문장 중에서 가장 중요한 정보를 가진 K개의 문장을 선택해 문서를 요약하는 것!
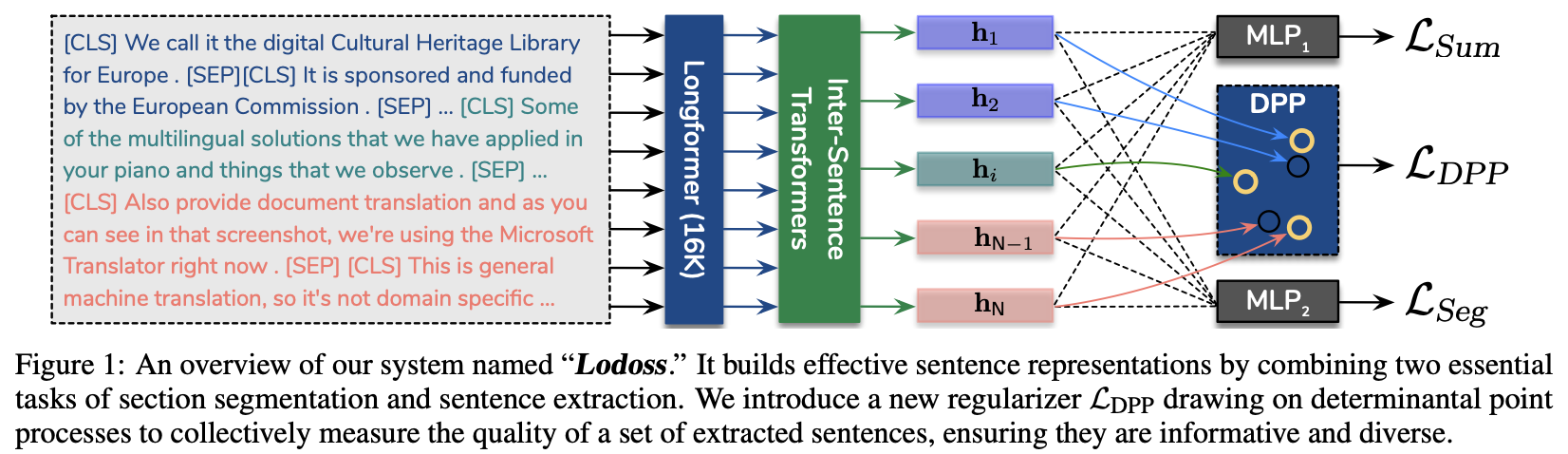
-
여기서 제안하는 모델을 Lodoss(Long document summarization with segmentation)이라고 표기
-
input document의 contextualized token embedding을 얻기 위해 dilated window attention버전의 Longformer을 사용
- 여기서 사용한 Longformer는 최대 16K tokens을 처리할 수 있는 large position embedding matrix를 활용
- 본 논문에서는 32(bottom)에서 512(top)까지 window size를 바꿔가며 dilation을 사용
-
Lodoss는 Longformer위에 2개의 레이어로 이루어진 inter-sentence Transformers를 쌓음
-
각 문장의 시작과 끝에 [CLS], [SEP] 토큰을 추가
-
이 상태로 longformer에 태워서 각 문장 에 대한 i번째 [CLS]토큰의 벡터를 representation으로 사용
-
document-level의 context를 얻기 위해, 이 벡터들에다가 sinusoidal position embedding을 더해 2개의 레이어를 가지는 inter-sentence Transformers에 태움
-
여기서 나온 output vector를 으로 표기
Summarization and Section Segmentation -
Notation
- 은 요약에 i번째 문장이 포함됨을 의미
- 은 i번째 문장이 section의 시작 혹은 끝임을 의미
- 보통 section의 시작 혹은 끝이 요약에서 중요한 문장이므로 이를 예측하는게 도움이 될거라 생각
(즉, 둘다 문장 표현에 MLP 1 layer를 거쳐서 나온 확률값을 로 씀)
-
본 논문에서의 기본 모델, "Lodoss-base"는 모델의 문장당 empirical cross-entropy를 최소화하도록 함
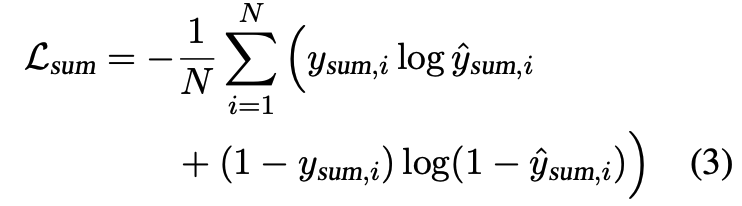
-
"Lodoss-joint"의 경우 기본 모델에 2가지 task를 동시에 수행하도록 각각의 Task에 대한 loss를 결합
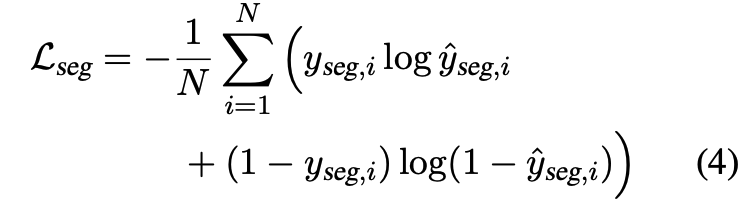
A DPP Regularizer -
DPP는 문장들의 subset의 점수를 매기기 위한 probailistic measure를 정의
-
은 개의 문장을 가지는 ground set
-
추출 요약에 해당하는 subset 의 확률은 아래와 같은 식으로 주어짐(det(.)은 행렬의 determinant를 의미)
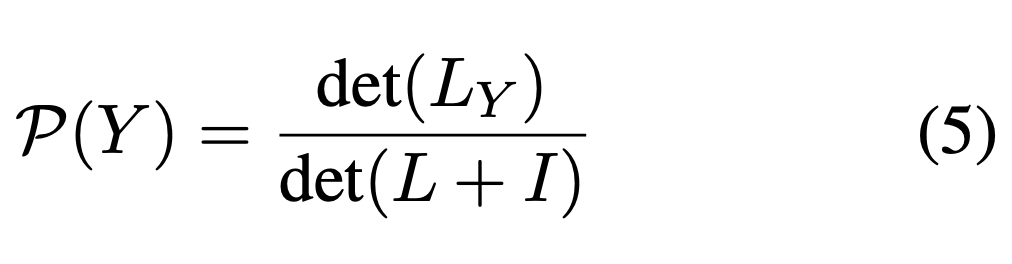
- is a positive semi-definite matrix
- 는 문장 i와 j사이의 similarity를 가리킴
- 는 요약 문장들간의 유사도 행렬
- 는 과 같은 차원을 가지는 identity matrix
-
L을 구축하기 위해 quality-diversity decomposition을 사용
- 은 문장의 퀄리티를 나타냄
- sentence quality score is given by
- 은 문장쌍의 유사도를 나타냄
- sentence similarity score is defined by :
- 결국 의 요소는 퀄리티문장간유사도퀄리티로 계산이 됨
- 은 문장의 퀄리티를 나타냄
-
DPP는 만약, 요약문이 중요하고 다양한 문장의 하위집합으로 이뤄져 있다면, 보상
- 만약 두 문장 i,j로 이뤄진 요약문에서 i,j가 높은 퀄리티면서 서로 유사하지 않다면 확률 점수 는 높은 값을 가지게 됨
- 반대로, 요약에 동일한 문장이 2개 있다면, 는 0이 됨
-
DPP regularizer는 ground-truth extractive summary 의 negative log-probability로 정의됨
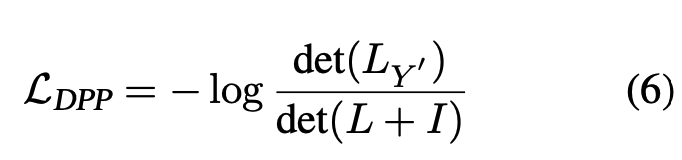
-
본 논문의 최종 모델 "Lodoss-full"은 아래와 같은 loss function을 사용
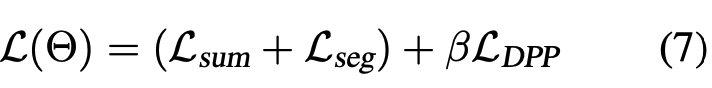
- 여기서 는 sentence-level cross-entropy loss와 summary-level의 DPP regularization의 균형을 맞추는 coefficient
Experiments
Datasets
- written documents
- scientific articles
- 사람이 쓴 요약문, top-level head로 나눠져 있는 section 존재
- arXiv
- papers in the fields of mathematics, physics, astronomy, ...
- PubMed
- research artices and their abstracts on life sciences and biomedical topics
- transcript documents
- VideoLectures.NET에 있는 강의들에 Speech-to-Text API를 사용해 데이터 구축
- 강의안과 스크립트를 시간 순서대로 맞춰서 정리하고, 대본에서 각 슬라이드 한장에 해당하는 부분이 section이 되고, 슬라이드에서 추출한 글을 정답 요약으로 사용
- Ground-Truth Labels
- 에 대해 문서의 각 문장이 ORACLE 요약에 속하면 1 아니면 0으로 라벨링
- ORACLE은 한 번에 한 문장씩 ROUGE-1과 2, F1의 평균을 향상시키는 문장을 더하면서 생성
- ORACLE summaries는 추출 요약 모델의 낼 수 있는 최고 성능
- Scientific paper의 경우 section이 나눠져 있으므로, section의 처음이나 마지막 문장에 해당하는 경우 로 아니면 0으로 라벨링
- lectures의 경우, 모든 스크립트가 강의안과 같이 정리되어 있으므로, 강의안으로 mini-section을 분리
- System predictions
- input document에서 K개의 고정된 수의 문장을 추출
- K는 정답 요약문의 평균 문장 개수와 가깝게 선정
- PubMed는 7, arXiv는 5
- lectures의 경우 3
Experimental Settings
- Adam optimizer
- inital learning rate :
- 8 NVIDIA Tesla P40 GPUs
- models were trained on each dataset for 20 epochs
- batch size of 8 with gradient accumulation every 4 steps
- = 0.1
- use FP 16 for all models, with the exception of the full model, it is used with FP3
- use 4K input for all ablations to save computation unless otherwise noted(best results are with 16K)
Summarization Results
Baseline Systems
-
extractive approach
- SumBasic : 빈도 높은 단어 가지면 중요한 문장으로 간주
- LexRank : eigenvector centrality을 기반으로 중요 문장 측정
- ExtSum-LG : 중요한 문장을 추출하기 위해 local과 global context사용
- +RdLoss : 긴 글 요약에서 중복 방지 하기 위해 redundancy loss term 추가
- Sent-PTR : 문장 추출을 위해 계층적 seq2seq sentence pointer model 사용
-
abstractive approach
- Discourse : 문장 구조를 모델링하기 위해 hierarchical encoder + 요약 생성을 위해 attentive decoder를 사용
- TLM-I+M : introductino section과 extracted sentence가 context로 주어지고, Transformer language model을 사용해서 논문 초록을 생성
- BigBird : sparse attention과 windowed attention를 사용해서 긴 input sequences를 처리
- HAT : 긴 문서를 요약하기 위해 encoder-decoder모델에 hierarchical attentino layers를 추가
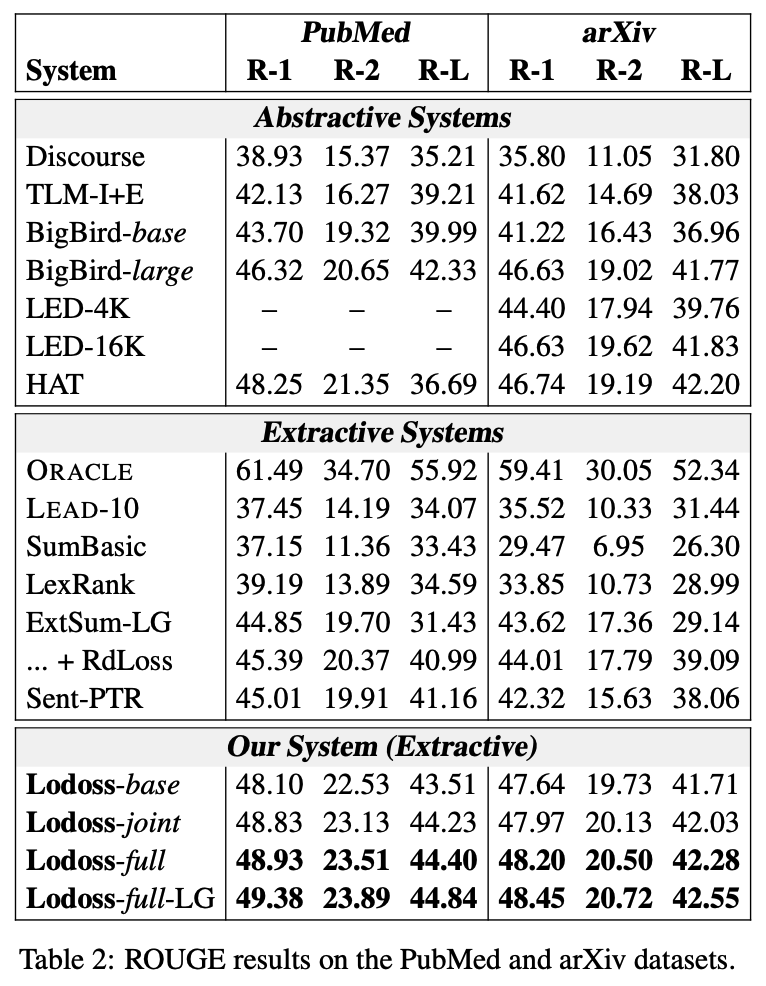
Results on Scientific Papers
-
평가 지표로 ROUGE-1,2,L사용
-
Lodoss-base, using
-
Lodoss-joint, using
-
Lodoss-full, using
-
위의 장표를 보면 Lodossr계열 모델들의 성능이 여타 다른 abstractive, extractive baselines보다 더 뛰어난 것을 알 수 있음
-
LEAD의 경우 긴 문서에서는 뉴스에서처럼 극적인 성능이 나오지 않음
-
또한, approximate randomization method로 유의수준을 검정해본 결과, 99%의 신뢰수준에서 Lodoss계열 모델이 BigBird-base와 LED-4K보다 유의미하게 나음
-
Lodoss계열 모델들도 버전마다 성능 차이가 나는데 이는 section segmentation과 요약 수준의 DPP regularizer가 도움이 된다는 걸 가리킴
-
large encoder('-LG')는 둘 데이터셋 모두에서 큰 성능 향상을 보임
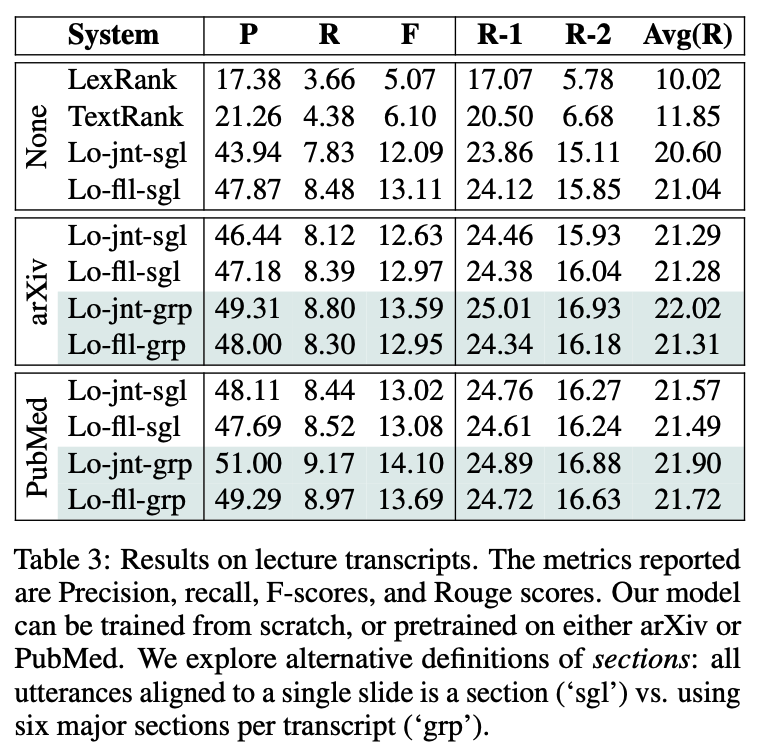
Results on Lecture Transcripts -
scratch부터 lecture transcripts를 사용해서 학습을 하거나 arXiv 또는 PubMed로 pretrain한 후에 fine-tune
-
jnt = Lodoss-joint, fll = Lodoss-full, sgl = single slide is a section, grp = six major sections per transcripts
-
written documents에 pretrain한 모델이 더 높은 성능을 보임
-
arXiv로 사전 학습한거보다 PubMed로 사전학습한 경우가 대다수의 모델에서 더 높은 성능을 보임
-
특히, 사전학습한 모델의 경우 Lo-joint-*모델이 높은 성능을 보임
- DPP가 효과가 없었던게 아니띾?
-
transcript section에서 각각의 슬라이드를 section으로 볼지, 한 transcript마다 6개의 section이 있다고 여길지에 대해서도 실험
- 전자는 한 document당 약 33개의 section이 존재
- 후자는 가장 거론되는 6개의 슬라이드를 찾고, 각 슬라이드의 시작 발화를 section의 시작으로 봄
- PubMed과 arXiv는 평균적으로 6.06, 5.68의 section을 가지고 있으므로, 이와 비슷하게 맞춰줌(사전학습하고 파인튜닝 할거니까)
-
결론적으로, 6개의 section으로 나누는게 더 높은 성능을 보임
Ablation and Analyses
Effect of Summary Length
-
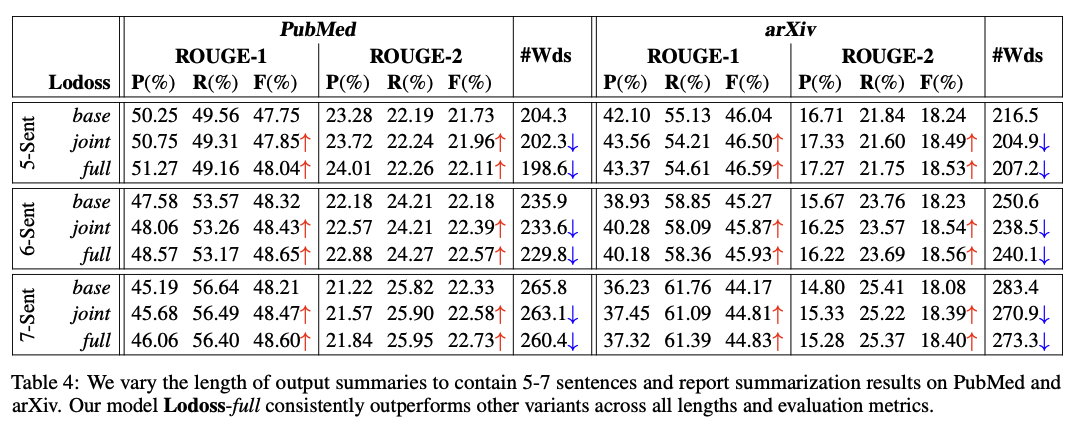
요약문의 길이(K)를 5,6,7로 설정해서 실험
-
위의 장표를 보면 Lodgoss-full모델이 꾸준히 다른 모델보다 높은 성능을 보임
-
PubMed에서는 7개의 문장으로 요약하는게 가장 높은 성능을 냈고, arXiv에서는 5개의 문장으로 요약하는 것이 가장 좋았음
Effect of Source Sequence Length
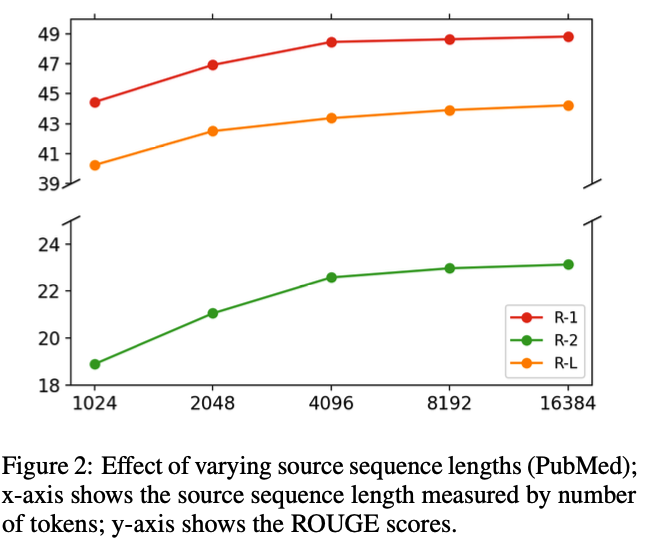
-
더 긴 source sequence를 사용할수록 더 높은 성능을 보임
- 중요한 정보가 잘리니까(예를 들어, 4K면 arXiv input의 반이 날라감)
Model's Performance on Section Segmentation
- 모델이 실제로 segmentation을 잘하는지 살펴보기 위해 WindowDiff지표를 사용
- WindowDiff : 2개의 sequence가 있을 때 한 구간 내의 같은 개수의 boundary가 있는지 확인. 다를 경우 count. 즉, WindowDiff가 높으면 각 구간에서 예측한 boundary개수가 많이 다르다는 것
- 실험 결과, full model과 large pretrained model이 section boundaries를 더 잘 예측함
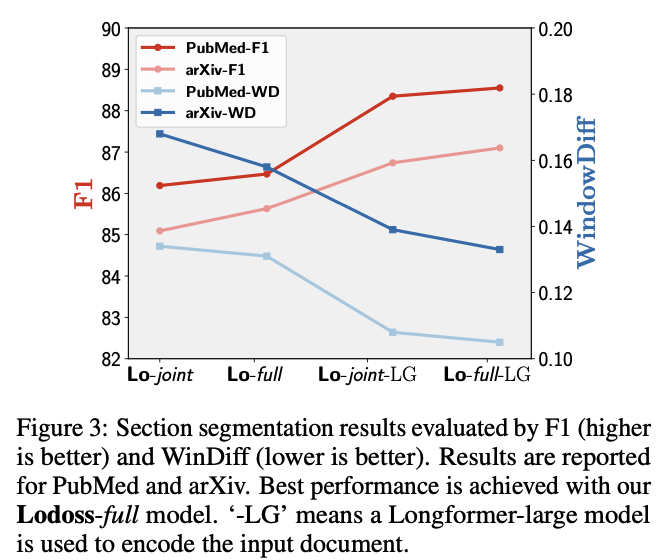
- 또한, Section의 마지막 문장보단 첫번째 문장을 더 잘 예측함
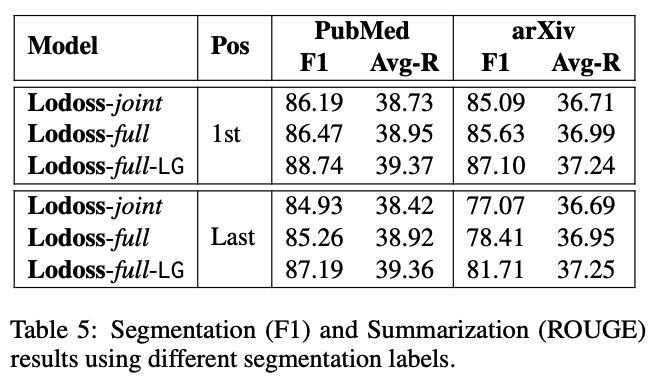
Effect of Our DPP Regularizer
- 위의 장표를 보면 요약당 평균 단어 수를 보여줌
- 이를 보면, Lodoss-full모델이 다른 모델보다 짧게 요약하면서도 높은 성능을 보임
- 그렇게 뚜렷하다고는 생각 안함
- 그렇게 뚜렷하다고는 생각 안함
Why section Segmentation is Necessary
- 요약 문장들이 얼마나 자주 section boundaries근처에 발견되는지 조사
- "1"은 요약 문장이 section의 첫번째 문장임을 가리킴
- "-1"은 요약 문장이 section의 마지막 문장임을 가리킴
- 아래 장표를 보면, arXiv보단 PubMed에서 section의 첫번째나 마지막 문장이 요약인 경우가 많음
- arXiv의 경우 PubMed의 2배 길이라 요약 문장이 꼭 section boundaries에 있진 않음
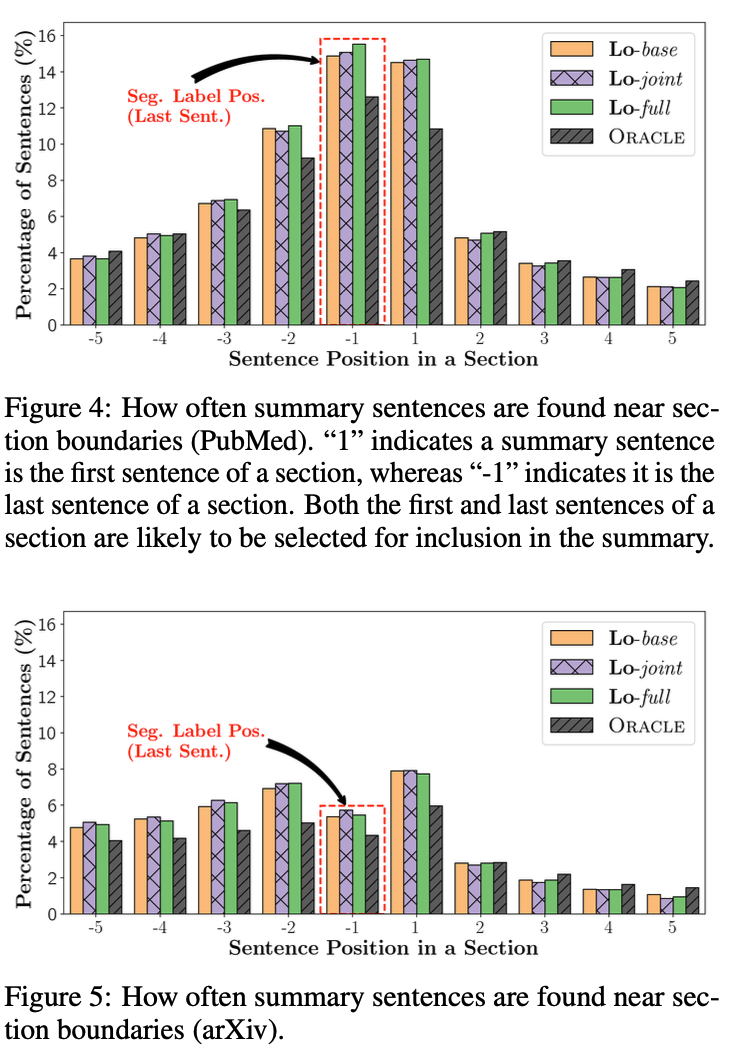
- arXiv의 경우 PubMed의 2배 길이라 요약 문장이 꼭 section boundaries에 있진 않음
Human Assessment of System Summaries
- informativeness와 diversity를 중점으로 평가
- Lodoss-joint와 Lodoss-full에 대해서만 평가
- informativeness
- 각각의 모델이 만드는 요약문들을 합쳐서 하나의 set으로 만듦
- 각 문장과 정답 요약문이 어느정도 관계가 있는지 1(worst)부터 5(best)점 사이의 점수를 매김
- 요약 문장들의 informativeness점수의 평균이 요약문의 점수가 됨
- diversity
- 두 모델이 만든 요약문의 합집합에서 교집합을 뺌
- 사람에게 교집합과 위에서 만든 집합의 문장이 얼마나 다른지를 평가하게 함
(좋은 요약은 각각의 문장이 서로 유사하지 않은 내용을 가지고 있어야 한다고 가정)
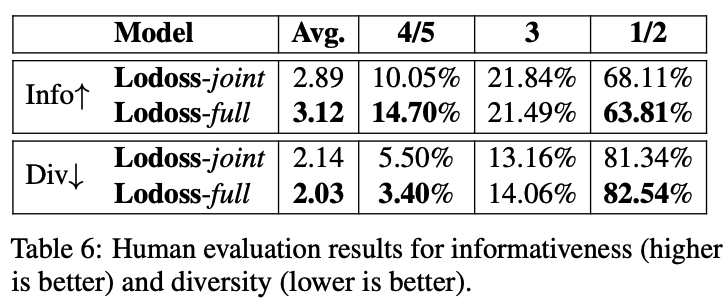
- 평가 결과, Lodoss-full이 더 나은 relevancy와 diversity를 보임
Concolusion
- long document extractive summarization을 section segmentation과 sentence extraction을 합침으로써 해결하려 함
- 기존의 longformer + section segmentation + sentence extraction로 긴 글을 받아서 추출 요약함
- 여기에 DPP regularizer을 사용해서 보다 요약일 확률이 높으면서 다양한 문장을 선택하도록 함
- 실험 결과, 높은 성능을 보이고 spoken document에도 적용될 수 있음을 보임
Limitations
- section boundaries를 사용할 수 없을 때, 모델이 의도한 대로 되지 않음
- 학습 모델은 pretrain할 때 쓴 데이터에 따라 inductive biases가 생길 수 있음
