운영체제는 왜 계급을 나누는가?
운영체제의 가장 본질적인 역할은 자원 관리와 보호.
만약 모든 프로그램이 CPU의 모든 명령어를 실행하고 RAM의 모든 영역에 접근할 수 있다면, 하나의 프로그램에 발생한 문제가 운영체제의 핵심 데이터를 파괴하거나 다른 프로그램의 정보를 침해할 수 있음.
이를 방지하기 위해 현대 컴퓨터 아키텍처는 하드웨어적으로 실행 권한을 분리하는 방식.
이것이 이중 동작 모드.
하드웨어 수준의 구현 Mode Bit와 CPL
이중 모드의 핵심은 CPU가 지금 실행하는 이 코드가 믿을만한가?를 실시간으로 판별하는 것.
이를 위해 CPU는 레지스터에 권한 상태를 관리.
- Mode Bit (제어 레지스터): CPU 내부에 현재 어떤 권한으로 코드가 실행 중인지를 나타내는 비트가 존재
- 0 (kernel Mode): 특권 모드. 모든 하드웨어 자원을 제어할 수 있는 권한
- 1 (User Mode): 비특권 모드. 실행 가능한 명령어와 접근 가능한 메모리 범위가 제한
- CPL (Current Privilege Level): x86 아키텍처에서는 CPU의
CS (Code Segment)레지스터 하위 2비트가 이 역할을 수행00: 가장 높은 권한 (Kernel)11: 가장 낮은 권한 (User)
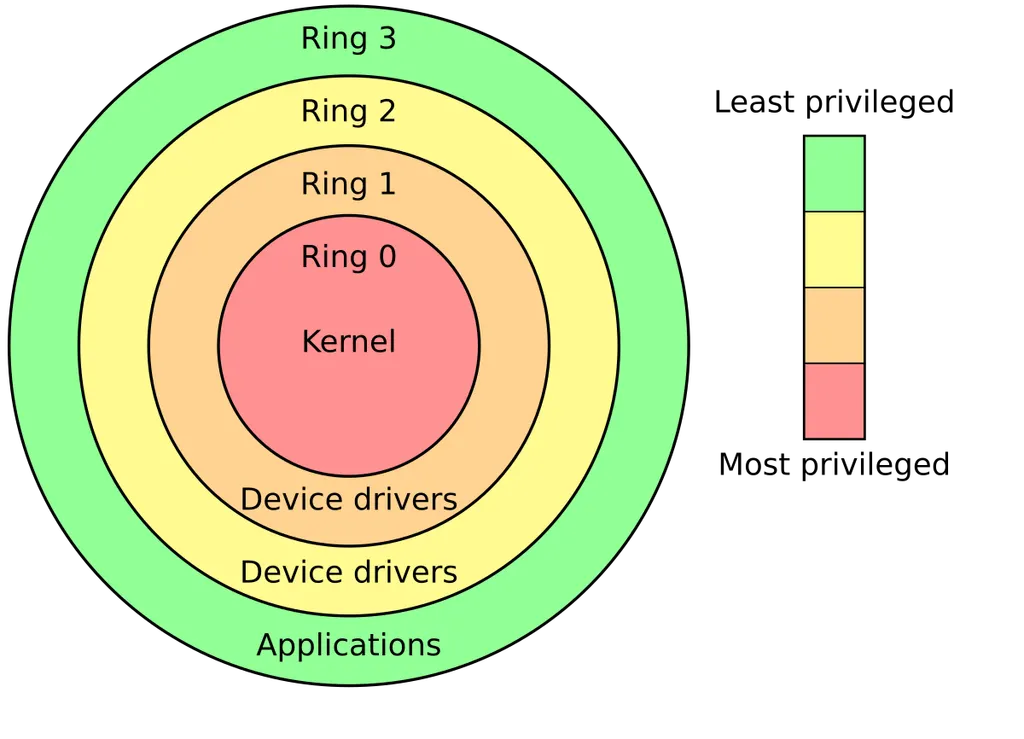
계급의 구조: Protection Rings (보호 링)
x86 설계자들은 권한을 총 4단계(Ring 0 ~ Ring 3)로 설계.
숫자가 낮을수록 안쪽에 위치하며 권한이 높음.
- Ring 0 (Kernel Mode): 운영체제의 심장부(Scheduler, Memory Manager, File System 등)가 위치
- CPU의 전역 설정을 변경하거나 인터럽트 벡터 테이블(IDT)을 수정할 수 있는 유일한 계급
- Ring 1 & 2: 원래는 디바이스 드라이버나 프로토콜 스택을 위해 설계됨
- 하지만 모드 전환 시 발생하는 오버헤드와 설계의 복잡성 때문에 현대의 Window와 Linux는 성능 최적화를 위해 이 단계를 건너뛰고 0과 3만 사용 (Monolithic Kernel 구조)
- Ring 3 (User Mode): 우리가 사용하는 모든 일반 애플리케이션이 여기서 실행
- 직접적인 하드웨어 조작이 차단되어 있어, 시스템을 파괴하려 해도 CPU가 허용하지 않음
특권 명령어 (Privileged Instructions)
시스템의 핵심 자원(CPU 상태, 메모리 맵, I/O 장치 등)을 직접적으로 조작하는 기계어 명령.
커널 모드에서만 실행 가능하며, 유저 모드에서 실행하려고 시도할 경우 CPU가 General Protection Fault 예외를 발생시켜 프로세스를 즉시 종료 시킴.
- I/O 제어:
IN,OUT명령어. 하드웨어 포트에 직접 데이터를 쓰고 읽는 행위 - 인터럽트 제어:
CLI(Clear Interrupt Flag - 인터럽트 중단),STI(Set Interrupt Flag - 인터럽트 허용) - 시스템 제어:
HLT(Halt - CPU 정지),LIDT(Load IDT - 인터럽트 지도 변경) - 메모리 관리:
Move CR3, ...(페이지 테이블의 시작 주소를 변경하는 명령)
메모리 공간의 분리 (Kernel Space vs User Space)
OS는 가상 주소 공간을 두 개의 영역으로 분리.
- 유저 공간 (User Space): 가상 주소 공간의 낮은 주소 영역에 위치
- 프로세스의 코드, 데이터, 힙, 스택이 포함
- 오직 해당 프로세스 본인만 접근할 수 있으며, 다른 프로세스의 유저 공간을 볼 수 없음
- 커널 공간 (Kernel Space): 가상 주소 공간의 높은 주소 영역에 위치
- 운영체제의 핵심 코드, 인터럽트 핸들러, 장치 드라이버, PCB 등이 상주
- 핵심 특징:
- 모든 프로세스의 가상 주소 공간 상단에 동일한 커널 공간이 매핑되어 있음
- 즉, 어떤 프로세스가 실행되든 커널은 항상 같은
높은 주소에 대기하고 있음
가상 주소를 실제 물리 주소로 변환하는 장치인 MMU는 주소 번역만 하는 것이 아닌 통행 검사를 병행.
- PTE (Page Table Entry)의 구조: 페이지 테이블의 각 항목(PTE)에는 주소 정보 외에 여러 상태 비트가 있는데, 그중 U/S 비트가 핵심
- U/S = 0 (Supervisor): 오직 Ring 0에서만 접근 가능
- U/S = 1: Ring 3에서도 접근 가능
- 검사 로직: 유저 모드 프로그램이 커널 공간에 해당하는 주소를 읽거나 쓰려고 시도하면, MMU는 즉시 주소 번역을 중단하고 CPU에 Page Fault(또는 Access Violation) 예외를 던짐
보안이 중요하지만 커널을 아예 따로 분리해두지 않는 이유는 성능 때문.
- 빠른 시스템 콜 처리: 시스템 콜이 발생할 때마다 커널 메모리 지도를 새로 불러와야 한다면 (TLB Flush), 오버헤드가 너무 커짐
커널이 항상 같은 자리에 매핑되어 있으면 모드 비트만 바꾸고 바로 커널 코드를 실행할 수 있음 - 인터럽트 대응: 하드웨어 인터럽트는 언제 발생할지 모르기에 어떤 프로그램이 돌고 있든 커널이 주소 공간 안에 있어야 즉각적으로 핸들러를 실행할 수 있음
모드 전환의 트리거
유저 모드에서 커널 모드로의 전환은 프로그램이 임의로 주소를 점프해서 일어나는 것이 아님.
반드시 하드웨어 인터럽트 라인이나 특수 명령어를 통해서만 미리 약속된 지점으로 진입할 수 있음.
- 시스템 콜 (System Call / Trap): 의도적인 요청
유저 모드 프로그램은 하드웨어 자원에 직접 접근할 권한이 없음.
만약 프로그램이 직접 디스크에 데이터를 쓰거나 네트워크 패킷을 보낼 수 있다면, 다른 프로그램의 데이터를 변조하거나 삭제하는 보안 사고를 막을 방법이 없음.
System Call은 운영체제가 제공하는 서비스에 접근하기 위해 프로그램이 호출하는 프로그래밍 인터페이스.
모든 자원 요청은 반드시 System Call을 통해 이루어져야 함.
- 성격: 소프트웨어 인터럽트
- 상황: 프로그램이 파일 읽기, 프로세스 생성, 네트워크 통신 등 커널의 서비스가 필요할 때 스스로 발생
- 명령어: 현대 x86-64에서는
SYSCALL - 특징: 프로그램 실행 흐름상 예측 가능한 지점에서 발생
- 하드웨어 인터럽트: 외부 사건
- 성격: 비동기적 이벤트
- 상황: 외부 하드웨어 장치가 CPU에 신호를 보낼 때 발생
- 키보드 타이핑, 마우스 클릭, 패킷 도착, 디스크 읽기 완료 등
- 타이머 인터럽트: 스케줄링을 위해 발생하는 가장 중요한 인터럽트
- 특징: 프로그램의 실행 위치와 상관 없이 언제든 발생할 수 있으며, CPU는 현재 명령어를 마치는 즉시 모드를 전환
- 예외: 실행 중 오류
- 성격: 동기적 이벤트
- 상황: CPU가 명령어를 실행하다가 정상적으로 처리할 수 없는 상황을 맞닥뜨렸을 때 발생
- Divide by Zero
- Segmentation Fault / Page Fault
- 권한이 없는 특권 명령어 실행 시도
- 특징: 문제가 생긴 그 시점에 즉시 발생하며, 커널은 이 예외를 보고 프로그램을 종료할지, 아니면 문제를 해결하고 다시 실행할지 결정
CPU가 데이터가 도착했는지 계속 확인하는 방식을 풀링(Pooling)이라고 하며, CPU 자원을 엄청 낭비함.
인터럽트는 비동기적으로 발생하는 이벤트를 효율적으로 처리하기 위한 핵심 메커니즘.
아래는 인터럽트를 통해 모드 전환이 일어날 때 CPU 내부에서 발생하는 물리적인 단계.
이 과정은 매우 빠르게 일어나며 하드웨어가 자동으로 수행하는 부분이 많음.
- Context Saving (상태 저장)
- CPU는 현재 실행 중이던 유저 프로그램의 상태를 저장
- 커널 스택으로 자동 전환되며, 여기에 현재의 플래그 레지스터(EFLAGS), 코드 세그먼트(CS), 명령어 포인터(EIP/RIP) 등을 Push
- 이는 나중에 커널 업무가 끝난 후 유저 프로그램의 중단된 지점으로 돌아오기 위함
- Mode Bit 변경 (CPL Update)
- CPU는 CS 레지스터의 하위 2비트(CPL)를
11에서00으로 변경 - 이후 CPU는 모든 특권 명령어를 실행할 수 있는 상태가 됨
- Entry Point 찾기 (IDT 참조)
- CPU는 무작정 커널로 가는 것이 아니라, IDT(Interrupt Descriptor Table)을 확인
- 발생한 인터럽트나 시스템 콜 번호에 해당하는 ISR(Interrupt Service Routine)의 주소를 찾아 그곳으로 PC(Program Counter)를 옮김
- Kernel Handler 실행
- 운영체제의 코드가 실행
프로세스 스케줄링
현대 운영체제는 수백 개의 프로세스가 동시에 실행되는 것처럼 보이는 멀티태스킹 환경을 제공.
프로세스는 생성부터 종료까지 커널의 통제 아래 여러 상태를 오감.
- New (생성): 프로그램이 메모리에 적재되어 PCB가 생성된 단계
- Ready (준비): CPU를 제외한 모든 자원(메모리 등)을 할당받아, 선택만 되면 즉시 실행 가능한 상태. Ready Queue에서 대기
- Running (실행): 실제로 CPU를 점유하여 명령어를 실행 중인 상태
- Waiting/Blocked (대기): I/O 작업이나 특정 이벤트(세마포어 등)를 기다리며 휴면 중인 상태.
- Terminated (종료): 실행을 마치고 자원을 반납하는 단계
현대 OS는 시스템의 부하를 조절하기 위해 세 단계의 스케줄러를 운영.
- 장기 스케줄러 (Long-term Scheduler / Job Scheduler): 어떤 프로세스를 Ready Queue에 넣을지(메모리에 올릴지) 결정
- 다중 프로그래밍의 정도를 제어하며, 현대 시분할 시스템에서는 메모리가 충분하여 보통 생략되거나 중기 스케줄러가 역할을 대신 함
- 단기 스케줄러 (Short-term Scheduler / CPU Scheduler): 메모리에 있는 Ready 상태의 프로세스 중 누구에게 CPU를 줄지 결정
- 매우 빈번하게 호출되므로 속도가 극도로 빨라야 함
- 중기 스케줄러 (Medium-term Scheduler / Swapper): 메모리 부족 시 프로세스를 통째로 데스크로 쫓아내거나, 다시 불러오는 역할을 함
CPU의 작업이 바뀔 때, 이전 프로세스의 상태를 저장하고 새 프로세스의 상태를 로드하는 과정을 Context Switch라고 함.
- 작동 원리:
타이머 인터럽트가 발생하면 커널은 현재 프로세스 A의 레지스터, PC, 스택 포인터 등을 PCB A에 저장.
이후 스케줄러가 선택한 프로세스 B의 정보를 PCB B에서 꺼내 CPU 레지스터에 덮어씌움. - 오버헤드:
문맥 교환이 일어나는 동안 CPU는 유저의 실제 코드를 실행하지 못함.
프로세스가 바뀌면 CPU 캐시나 TLB에 들어있던 데이터들이 쓸모없게 되어 성능이 일시적으로 하락함.
스케줄링 알고리즘
- 비선점형 (Non-preemptive) 알고리즘
프로세스가 스스로 CPU를 반납할 때까지 뺏지 않는 방식
- FCFS (First-Come, First-Served): 단순히 먼저 온 순서대로 처리
- Convoy Effect: 긴 프로세스가 앞을 막으면 짧은 프로세스들이 끝없이 대기하는 현상
- SJF (Shortest Job First): 실행 시간이 짧은 작업부터 처리
- 평균 대기 시간을 줄이는 데 최적이지만, 실행 시간을 미리 알기 어렵고 긴 프로세스가 굶는 Starvation(기아) 문제가 발생
- 선점형 (Preemptive) 알고리즘 (현대 OS 표준)
OS가 강제로 CPU를 회수할 수 있는 방식
- Round Robin (RR): 각 프로세스에게 동일한 Time Quantum(시간 할당량)을 부여
- 시간 할당량이 너무 크면 FCFS가 되고, 너무 작으면 문맥 교환 비용이 커짐 (보통 10~100ms)
- Priority Scheduling (우선순위 스케줄링): 중요도가 높은 프로세스 먼저 처리
- Aging 기법: 오래 기다린 프로세스의 우선순위를 높여주어 기아 현상을 해결
- 다단계 피드백 큐 (MLFQ, Multilevel Feedback Queue)
현대 Linux와 Window가 사용하는 가장 정교한 방식
- 여러 개의 큐를 두고, CPU를 많이 쓰는 프로세스는 우선순위가 낮은 큐로 내리고, I/O를 많이 쓰는 프로세스는 높은 우선순위 큐에 배치
- 목표: I/O 위주 프로세스(대화형 앱)에게는 빠른 응답성을, CPU 위주 프로세스(연산 앱)에게는 높은 처리량을 자동으로 보장
