1. 데이터 모델
1. 데이터 모델(Data Model)개념
- 현실 세계의 정보를 인간과 컴퓨터가 이해할 수 있도록 추상화하여 표현한 모델이다.
- 데이터 모델 절차는 개념적 데이터 모델, 논리적 데이터 모델, 물리적 데이터 모델 순이다.
2. 데이터 모델 절차
개념적 데이터 모델
- 현실 세계에 대한 인식을 추상적, 개념적으로 표현하여 개념적 구조를 도출하는 프로세스이다.
- 개념적 데이터 모델은 DB 종류에 관계가 없다
- 주요 산출물로는 개체관계도가 있다.
cf : 개체관계도(ERD; Entity-Relationship Diagram) : 각 업무 분석에서 도출된 엔터티간의 관계를 이해하기 쉽게 도식화된 다이어그램이다.
논리적 데이터 모델
- 업무의 모습을 모델링 표기법으로 형상화하여 사람이 이해하기 쉽게 표현하는 프로세스이다.
- 논리적 데이터 모델을 통해"관계 데이터 모델", "계층 데이터 모델", "네트워크 데이터 모델", "객체지향 데이터 모델", "객체-관계 데이터 모델" 중 하나의 모델에 맞게 설계한다.
- 트랜잭션 인터페이스를 설계한다.
- 논리적 데이터 모델링에서 정규화를 수행하낟.
cf : 정규화(Normalization) : 관계형 데이터 모델에서 데이터의 중복 성을 제거하여, 이상 현상을 방지하고 데이터의 일관성과 정확성을 유지하기 위해 무슨 실 분해하는 과정이다.
물리적 데이터 모델
- 논리 데이터 모델을 특정 DBMS의 특성 및 성능을 고려하여 물리적인 스키마를 만드는 일련의 프로세스이다.
- 논리 데이터 모델을 사용하고자 하는 각 DBMS의 특성을 고려하여 데이터베이스 저장 구조(물리 데이터 모델)로 변환하낟.
- 테이블(Tabal), 인덱스(Index), 뷰(View), 파티션(Partition) 등 객체를 생성한다.
- 응답시간, 저장 공간의 효율화, 트랜잭션 처리를 고려하여 설계 한다.
- 성능 측면에서 반정규화를 수행하낟.
cf : 반정규화(De-Normalization) : 정규화된 엔터티, 속성, 관계에 대해 성능 향상과 개발 운영의 단순화를 위해 중복, 통합, 분리등을 수행하는 데이터 모델링의 기법
2. 개체-관계(E-R)모델
1. 개체-관계(E-R) 모델 개념
- 현실 세계에 존재하는 데이터와 그들 간의 관계를 사람이 이해할 수 있는 형태로 명확하게 표현하기 위해서 가장 널리 사용되고 있는 모델
2. 개체-관계(E-R) 모델 구성요소
1. 개체(Entity) : 사물, 사물 등 유무형의 정보를 가지고 있는 요소 : 물리 단계에서 테이블로 변환
2. 속성(Attribute) : 개체가 갖는 속성을 의미 : 물리 단계에서 컬럼으로 변환
3. 관계(Relationship) : 두 개 이상의 개체 사이에 존재하는 연관성 : 1:1, 1:N, n:m관계 존재
3. 개체-관계(E-R) 다이어 그램 기호
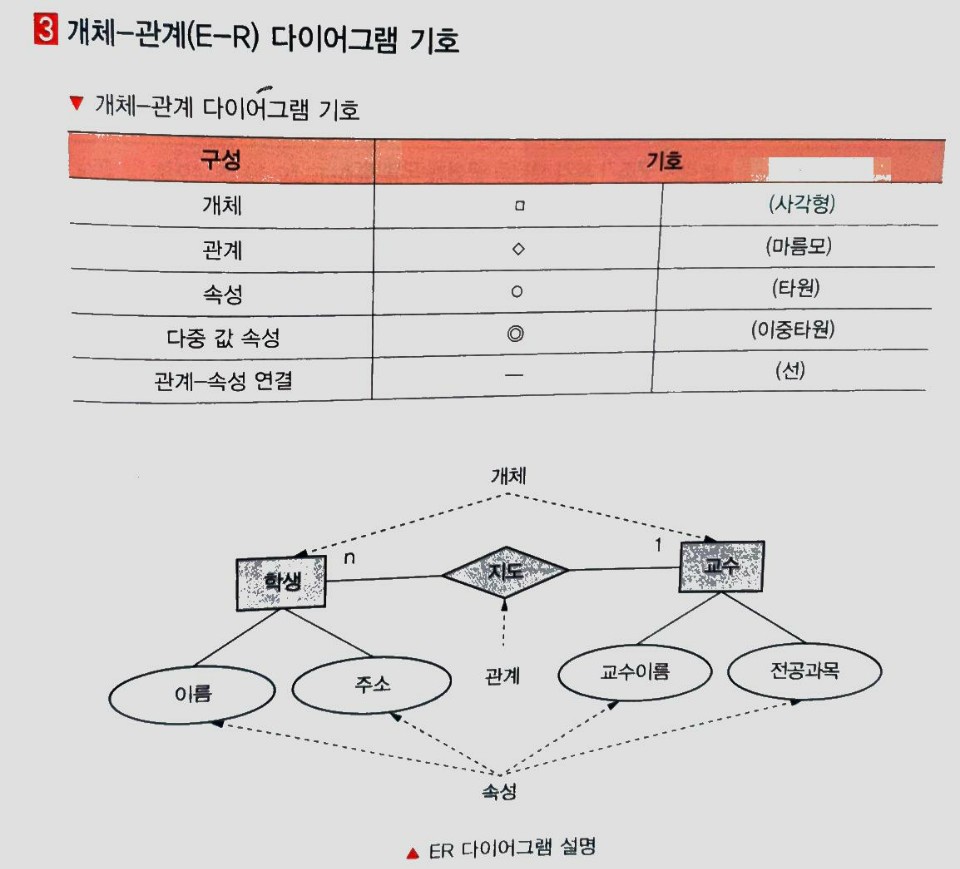
3. 논리적 데이터 모델링
1. 논리적 데이터 모델링 개념
- 업무의 모습을 모델링 표기법으로 형상화하여 사람이 이해하기 쉽게 표현하는 프로세스이다.
관계 데이터 모델
- 논리적 구조가 2차원 테이블 형태로 구성된 모델
- 기본 키(PK)와 이름을 참조하는 외래 키(FK)로 관계 표현
- 1:1, 1:N, N:M 관계를 자유롭게 표현
계층 데이터 모델
- 논리적 구조가 트리 형태로 구성된 모델
- 상하관계 존재한다(부모 개체-자식 개체)
- 1:N관계만 허용
네트워크 데이터 모델
- 논리적 구조가 그래프 형태로 구성된 모델이다.
- CODASYL DBTG 모델이라고 불린다.
- 1:N 관계만 허용
네트워크 데이터 모델
- 논리적 구조가 그래프 형태로 구성된 모델이다
- CODASYL DBTG 모델이라고 불린다.
- 상위와 하위 레코드 사이에 다대다(N:M)관계를 만족하는 구조이다
4. 데이터베이스 정규화
1. 데이터베이스 정규화(DB Normalization)의 개념
- 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스이다.
2. 데이터베이스 정규화 목적
- 중복 데이터의 최소화하여 테이블 불일치 위험을 최소화 한다.
- 수정, 삭제 시 이상 현상을 최소화함으로써 데이터 구조의 안정성을 최대화 한다.
- 어떠한 릴레이션이라도 데이터베이스 내에서 표현 가능하게 만든다.
- 데이터 삽입 시 릴레이션의 재구성에 대한 필요성을 줄인다.
- 효과적인 검색 알고리즘을 생성할 수 있다.
3. 이상 현상
- 정규화되지 않을 경우 발생하는 현상이다.
- 데이터의 중복성으로 인해 릴레이션을 조작할 때 발생하는 비합리적 현상이다.ㅏ
- 삽입, 삭제, 갱신 이상이 있다.
4. 데이터베이스 정규화 단계
1정규형(1NF) : 원자 값으로 구성
2정규형(2NF) : 부분 함수 종속 제거(완전 함수적 종속 관계)
3정규형(3NF) : 이행 함수 종속 제거
보이스-코드 정규형(BCNF) : 결정자 함수 종속
4정규형(4NF) : 다치(다중 값) 종속성 제거
5정규형(5NF) : 조인 종속성 제거
5. 논리 데이터 모델 품질 검증
1. 논리 데이터 모델 품질 검증 개념
- 데이터 모델이 업무 환경에서 요구하는 사항을 얼마나 잘 시스템적으로 구현할 수 있는가를 객관적으로 평가하기 어렵다.
- 대체적으로 좋은 데이터 모델이라고 말할 수 있는 몇가지의 요건이 존재한다.
2. 데이터 모델 요건
1. 완전성
- 업무에서 필요로 하는 모든 데이터가 데이터 모델에 정의되어 있어야 함
2. 중복 배제
- 하나의 데이터베이스 내에 동일한 사실은 반드시 한번만 기록하여야 함
3. 비즈니스 룰
- 업무 규칙을 데이터 모델에 표현하고 이를 모든 사용자가 공유할 수 있게 제공해야 함
4. 데이터 재사용
- 데이터의 재사용성을 향상시키기 위해서는 데이터의 통합성과 독립성에 대해서 충분히 고려해야 함
5. 안정성 및 확장성
- 정보 시스템을 구축하는 과정에서 데이터 구조의 안정성, 확장성, 유연성을 고려해야 함
6. 간결성
- 아무리 효율적으로 데이터를 잘 관리할 수 있더라도 사용, 관리 측면에서 복잡하다면 잘 만들어진 데이터 모델이라고 할 수 없음
7. 의사소통
- 많은 업무 규칙은 데이터 모델에 개체, 서브타입, 속성, 관계 등의 형태로 최대한 자세하게 표현되어야 함
8. 통합성
- 동일한 데이터는 조직의 전체에서 한 번만 정의되고 이를 여러 다른 영역에서 참조, 활용되어야 함
3. 데이터 모델 품질 검증 기준
- 논리적 데이터베이스 구축 후에 데이터 품질의 좋고 나쁨을 검증하기 위한 기준이다.
1. 정확성
- 데이터 모델이 표기법에 따라 정확하게 표현되었고, 업무 영역 또는 요구사항이 정확하게 반영해야 함
2. 완전성
- 데이터 모델의 구성요소를 정의하는 데 있어서 누락을 최소화하고, 요구사항 및 업무 영역 반영에 있어서 누락이 없어야 함
3. 준거성
- 제반 준수 요건들이 누락 없이 정확하게 준수해야 함
4. 최신성
- 데이터 모델이 현행 시스템의 최신 상태를 반영하고 있고, 이슈사항들이 지체없이 반영해야 함
5. 일관성
- 여러 영역에서 공통 사용되는 데이터 요소가 전사 수준에서 한 번만 정의되고 이를 여러 다른 영역에서 참조,활용되면서, 모델 표현상의 일관성을 유지해야 함
6. 활용성
- 작성된 모델과 그 설명 내용이 이해관계자에게 의미를 충분하게 전달할 수 있으면서, 업무 변화 시에 설계 변경이 최소화되도록 유연하게 설계해야 함

꾸준함