1. Job: 일회성 작업 실행
Job(잡) 은 하나 이상의 파드를 생성하여, 지정된 수의 파드가 성공적으로 완료될 때까지 실행을 보장하는 리소스이다.
Deployment와 가장 큰 차이점은, Job에게 파드의 '종료'는 실패가 아닌 '성공적인 완료'를 의미한다는 것이다. 이러한 특성 때문에 Job은 배치 처리나 일회성 태스크에 매우 적합하다.
1) Job 생성하기
다음은 원주율(π)을 2000자리까지 계산하고 종료되는 간단한 Job의 예시이다.
sample-job.yaml 파일 작성:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0 # 애플리케이션
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never # 컨테이너 실패 시 재시작하지 않고, 새 파드를 생성
backoffLimit: 4 # 실패 시 재시도 횟수Job 실행 및 상태 확인
# Job 생성
kubectl apply -f sample-job.yaml
# Job 상태 확인 (COMPLETIONS이 0/1에서 1/1로 바뀜)
kubectl get jobs
# NAME COMPLETIONS DURATION AGE
# pi 1/1 6s 26s
# Pod 상태 변화 확인 (watch 옵션 사용)
kubectl get pods --watch
# NAME READY STATUS RESTARTS AGE
# pi-g2n9w 0/1 Completed 0 12s
# 완료된 파드의 로그(결과) 확인
kubectl logs pi-g2n9w
# 3.1415926535...
2) restartPolicy 상세 분석
Job의 restartPolicy 는 파드 내 컨테이너에 장애가 발생했을 때의 동작을 결정하며, Job의 특성상 Always (기본값)는 사용할 수 없다.
옵션
1. restartPolicy: Never
컨테이너 실패 시 새로운 파드를 생성하여 작업을 재시도한다. 기존 파드는 Error 상태로 남는다.
sample-job-never-restart.yaml (잘못된 명령어 포함)
# ...
command: ["ls", "unvalid path"]
restartPolicy: Neverkubectl get pods결과: 실패한 파드(Error상태)와 새로 생성된 파드(ContainerCreating상태)가 함께 보인다.

2. restartPolicy: OnFailure
컨테이너 실패 시 동일한 파드 내에서 컨테이너를 재시작한다. 파드의 RESTARTS 횟수가 증가하며, 계속 실패하면 CrashLoopBackOff 상태가 된다.
sample-job-onfailure-restart.yaml (잘못된 명령어 포함)
# ...
command: ["ls", "unvalid path"]
restartPolicy: OnFailurekubectl get pods결과: 하나의 파드가CrashLoopBackOff상태가 되고RESTARTS카운트가 올라간다.
NAME READY STATUS RESTARTS AGE
errorjob-unvalidcommand1-tr776 0/1 CrashLoopBackOff 2 (20s ago) 43s3) 태스크와 작업 큐 병렬 실행
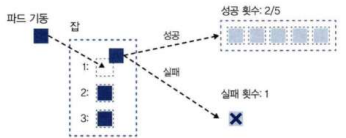
Job은 completions 와 parallelism 옵션을 통해 다양한 병렬 실행 패턴을 구현할 수 있다.
-
completions: Job이 성공으로 간주되기 위해 완료되어야 하는 파드의 총개수. -
parallelism: 동시에 실행할 수 있는 파드의 최대 개수. -
backoffLimit: 실패를 허용하는 횟수.워크로드 completionsparallelismbackoffLimit1회만 실행하는 태스크 1 1 O N개 병렬로 실행하는 태스크 M N P 한 개씩 실행하는 작업 큐 미지정 1 P N개 병렬로 실행하는 작업 큐 미지정 N P
📌 참고: completions는 생성 후 변경할 수 없지만, parallelism과 backoffLimit는 실행 중에도 변경 가능하다.
4) 일정 시간 후 Job 자동 삭제
완료된 Job과 파드는 클러스터에 계속 남아 리소스를 차지한다. spec.ttlSecondsAfterFinished 필드를 사용하면 Job이 완료된 후 지정된 시간(초)이 지나면 자동으로 삭제되도록 설정할 수 있다.
sample-job-ttl.yaml 작성:
# ...
spec:
ttlSecondsAfterFinished: 30
# ...확인:
kubectl get job pi --watch --output-watch-events 명령어로 지켜보면, 완료 후 30초가 지나면 DELETED 이벤트가 발생하는 것을 볼 수 있다.
2. CronJob: 주기적인 작업 실행
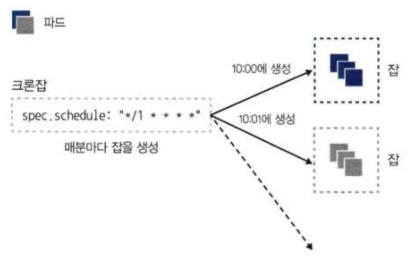
CronJob(크론잡)은 리눅스의 crontab과 같이, 지정된 스케줄에 따라 주기적으로 Job을 생성하는 리소스이다.
1) CronJob 생성하기
CronJob 매니페스트는 schedule 과 Job을 생성하기 위한 jobTemplate 이 추가된 구조를 가진다.
cronjob.yaml 파일 작성:
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure📌 스케줄(schedule) 형식: 분(0-59) 시간(0-23) 일(1-31) 월(1-12) 요일(0-6) 순서로 지정한다. */1 * * * * 은 '매 1분마다'를 의미한다.
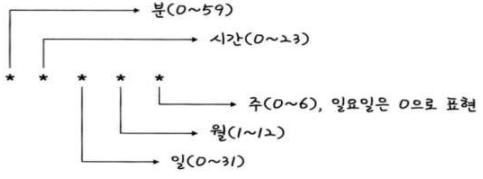
-
분은
0~59시는0-23일은1-31월은1-12요일은0-6이다 -
요일은
0=일요일,1=월요일 -
각 항목은 공백 문자로 구분
-
항목의 값이
*이면 해당 항목의 모든 값 -
-연산자를 이용하면 값의 범위를 지정할 수 있다. 요일에1-5를 사용하면 월요일부터 금요일까지 -
,연산자를 사용하면 값 목록을 정의하는 것이 가능, 시간에1,3,5를 지정하면 1시 3시 5시 -
/를 이용하면 단계값이 지정이 가능, 분에*/1은 1분마다가 되고1-10/2가 있으면 1,3,5,7,9가 된다
2) CronJob의 주요 관리 기능
CronJob은 주기적인 작업을 안정적으로 운영하기 위한 여러 제어 기능을 제공한다.
-
동시 실행 정책 (
concurrencyPolicy): 이전 작업이 끝나지 않았을 때 다음 작업을 어떻게 처리할지 결정한다.정책 개요 Allow(기본값) 이전 작업과 상관없이 새 작업을 실행 (동시 실행 허용). Forbid이전 작업이 실행 중이면 새 작업을 건너뜀. Replace이전 작업을 중단시키고 새 작업을 실행. -
실행 시작 기한 (
startingDeadlineSeconds): 컨트롤러 장애 등으로 지정된 스케줄 시간을 놓쳤을 경우, 이 시간(초)을 초과하면 작업을 실행하지 않고 건너뛰게 한다. -
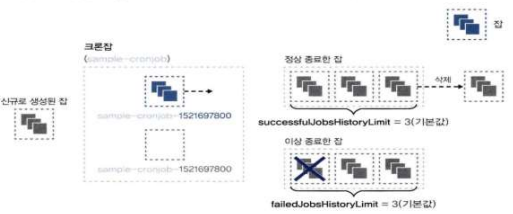
이력 관리 (
successfulJobsHistoryLimit,failedJobsHistoryLimit): 성공하거나 실패한 Job의 기록을 몇 개까지 보관할지 지정한다. 기본값은 각각 3개, 1개이다. 이 기록을 통해 과거 작업의 로그나 상태를 확인할 수 있다.-
spec.successfulJobsHistoryLimit: 성공한 잡을 저장하는 개수 -
spec.failedOobsHistoryLimit: 실패한 잡을 저장하는 개수
-
-
수동 실행 및 일시 정지:
-
수동 실행:
kubectl create job [새로운-잡-이름] --from=cronjob/[크론잡-이름] -
일시 정지:
kubectl patch cronjob [크론잡-이름] -p '{"spec":{"suspend":true}}'
-
3) 운영 환경에서의 로그 관리
CronJob의 이력 관리 기능은 유용하지만, 실제 운영 환경에서는 컨테이너 로그를 Fluentd 등 외부 로그 시스템으로 수집하여 가용성 높은 환경에 별도로 저장하고 관리하는 것을 권장한다.