
📁 grep 명령어와 정규표현식
🔖 grep 명령어
💡 리눅스를 사용하다 보면 특정 문자나 패턴을 검색하는 경우가 발생한다. 그럴 때
grep 명령어를 활용할 수 있다.
grep은 global, regular expression, print에서 각각의 머릿글자를 따 온 것이다.
$ grep [옵션] [패턴] [파일명]➡️ grep 옵션
| 옵션 | 동작설명 |
|---|---|
| -b | 검색 결과의 각 행 앞에 검색된 위치의 블록 번호(디스크 위치) 확인 |
| -c | 일치하는 행의 수 출력 |
| -h | 파일 이름 출력 안함 |
| -i | 대소문자 구분하지 않음 |
| -I (대문자 i) | 대소문자 구분함 |
| -l (소문자 L) | 패턴이 포함된 파일의 이름만 출력 |
| -n | 패턴이 포함된 행 번호 함께 출력 |
| -s | 에러 메시지 외에는 출력하지 않음 |
| -v | 패턴과 일치하지 않는 행만 출력 |
| -w | 단어와 일치하는 행만 출력 |
| -x | 라인과 일치하는 행만 출력 |
| -r | 하위 디렉토리 포함한 모든 파일에서 검색 |
| -m 숫자 | 최대로 표시될 수 있는 결과를 제한함 |
| -E | 찾을 패턴을 정규 표현식으로 찾음 |
| -F | 찾을 패턴을 문자열로 찾음 |
연습용 text(regexTest.txt)
```
y
z
1
2
3
a.c
ac
abc
abc
abbc
abbbc
abbbc
aa
aa
aaa
aaaa
Abc
a
aBc
aa
ABC
abc
b123c
b32a
(def) abc
abc
def
abcdef
defabc
```➡️ 문자열 abc를 포함하는 행 출력
$ grep abc test.txt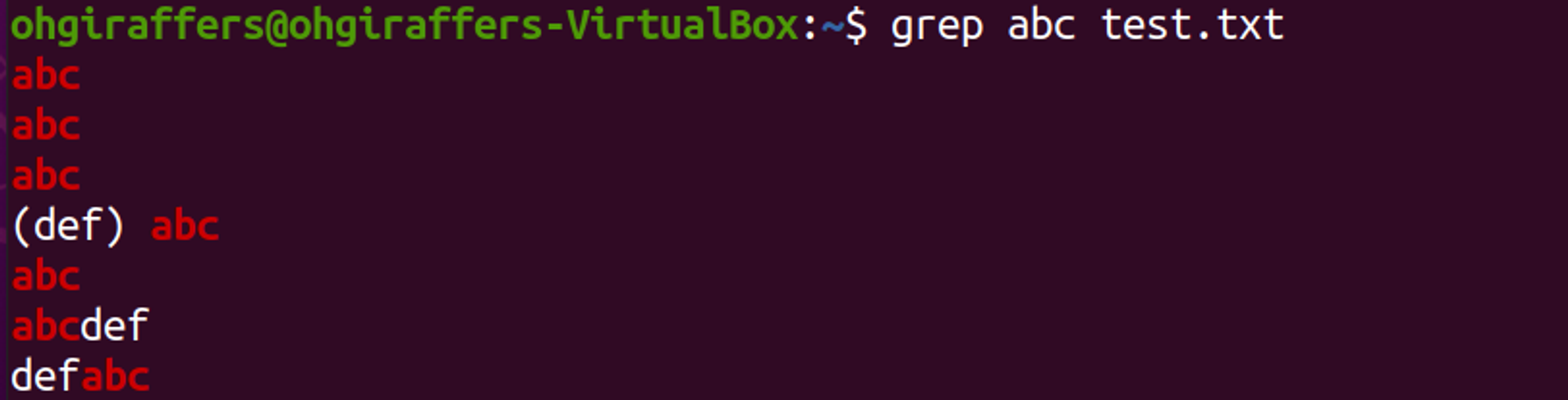
➡️ 검색 결과를 행 번호와 같이 출력
$ grep -n abc test.txt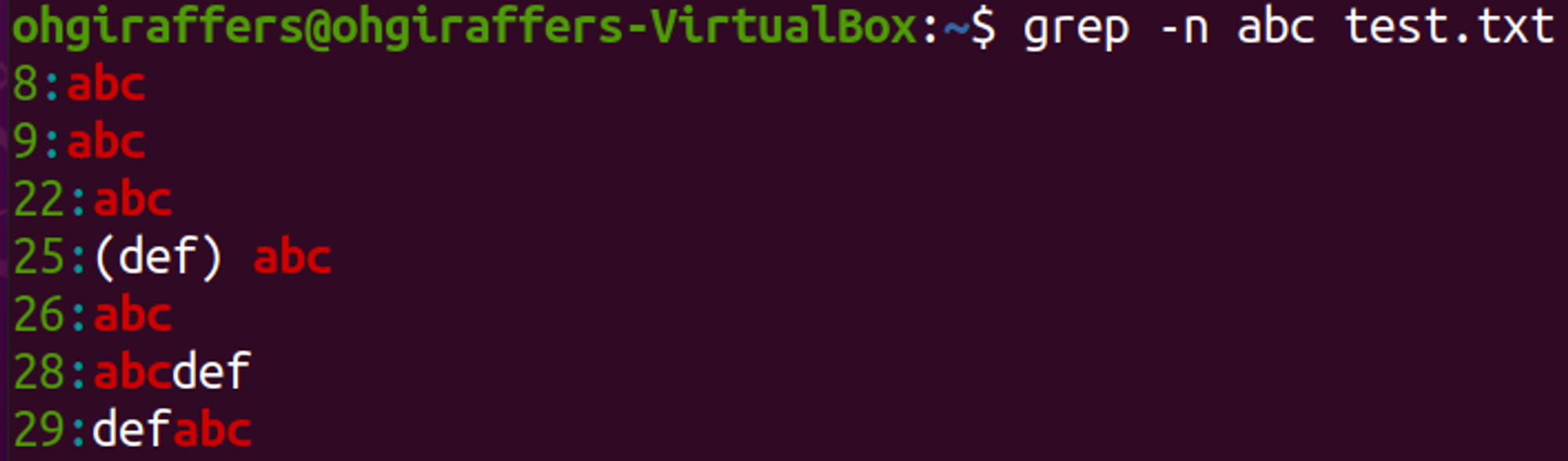
➡️ 대소문자를 구분하지 않고 검색
$ grep -ni abc test.txt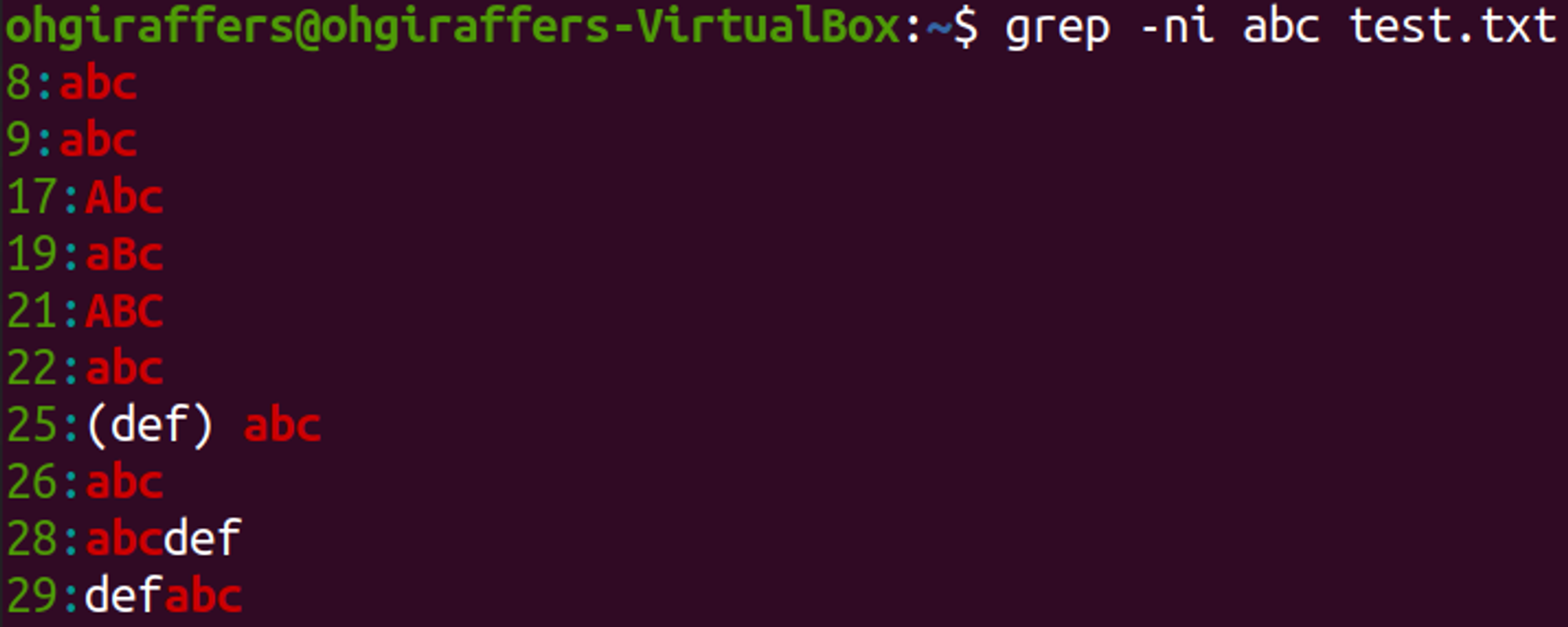
🔖 리눅스 정규표현식
💡 문자열 검색에 정규표현식을 사용하게 되면 조건에 일치하는 문자열 집합을 표현하고 완전히
동일하지 않은 값도 검색해서 표현할 수 있다.
확장 정규 표현식은 ‘-E’ 옵션을 추가해 주어야 한다.
🔖 리눅스의 메타 문자
메타 문자: 문자 패턴을 표기하기 위한 규칙 문법에 해당하는 문자
✅ 임의의 문자에 대한 메타 문자
| 메타 문자 | 의미 |
|---|---|
| . | 임의의 문자 하나 |
| [] | [] 안에 포함된 임의의 문자 하나 |
| [^] | [] 안에 포함되지 않는 문자 |
| \ | \ 다음의 문자를 메타 문자로 인식함 |
✅ 위치 지정 메타 문자
| 메타문자 | 의미 |
|---|---|
| ^ | 문자열의 시작을 나타냄 |
| $ | 문자열의 끝을 나타냄 |
✅ 반복 횟수를 지정하는 메타 문자
| 기본 정규 표현식 | 확장 정규 표현식 | 의미 |
|---|---|---|
| * | * | 앞의 문자 0회 이상 반복 |
| 없음 | + | 앞의 문자 1회 이상 반복 |
| 없음 | ? | 앞의 문자 0회 또는 1회 반복 |
| {m,n} | {m,n} | 앞의 문자 m회 이상 n회 이하 반복 |
| {m} | {m} | 앞의 문자 m회 반복 |
| {m,} | {m,} | 앞의 문자 m회 이상 반복 |
✅ 기타 메타 문자
| 기본 정규 표현식 | 확장 정규 표현식 | 의미 |
|---|---|---|
| () | () | 그룹화할 때 사용 |
| 없음 |
🔀 연습 💫
1. ‘abc’가 정확히 일치하는 라인 및 라인 번호
$ grep -n '^abc$' test.txt2. 어떤 하나의 문자 뒤에 ‘bc’가 오는 라인 및 라인 번호
$ grep -n '.bc' test.txt3. ‘a’로 시작하고 ‘c’로 끝나는 라인 및 라인 번호
$ grep -n '^a.*c$' test.txt4. ‘a’ 뒤에 ‘b’가 없거나 여러 개 있고 그 뒤에 ‘c’가 오는 라인 및 라인 번호
$ grep -n 'ab*c' test.txt5. ‘a’ 뒤에 ‘b’가 하나 이상 있고 그 뒤에 ‘c’가 오는 라인 및 라인 번호
$ grep -nE 'ab+c' test.txt6. ‘a’ 로 시작하고 이후로는 ‘b’가 나오지 않는 라인 및 라인 번호
$ grep -nE '^a[^b]*$' test.txt7. ‘b’로 시작하고 다음에 숫자가 존재하는 라인 및 라인 번호
$ grep -nE '^b[0-9]+' test.txt8. ‘a’ 뒤에 ‘b’가 정확히 두 번 나오고 ‘c’로 끝나는 라인 및 라인 번호
$ grep -nE 'ab{2}c$' test.txt => abbc 
"로컬에선 문제없었는데…?"