🎈 프로세스 동기화란?
동시다발적으로 실행되는 프로세스들은 서로 데이터를 주고받고 영향을 주면서 협력하게 된다.
이 프로세스들은 아무렇게나 실행되면 문제가 생길 수 있으므로, 프로세스끼리 실행 시기를 조율해야한다.
이 과정을 동기화 라고 하는데, 주로 조율하는 것은 실행 순서와, 상호 배제다.
실행 순서 제어 : 프로세스를 올바른 순서대로 실행
상호 배제 : 동시에 접근해서는 안되는 자원에 동시에 접근하는 것을 제한
🔰 실행 순서 제어를 위한 동기화
메모장 프로그램에 읽기 프로세스와 쓰기 프로세스가 동시에 실행된다.
메모장에 글을 쓴다면 쓰기 프로세스가 먼저 실행된 후, 읽기 프로세스가 쓴 값을 읽어야 한다.
반대로, 읽기 후 쓰기를 실행하면 쓴 값을 읽을 수 없다.
🔰 상호 배제를 위한 동기화
계좌에 2만원을 더하는 프로세스A, 5만원을 더하는 프로세스B가 있다.
두 프로세스는기존 잔액 읽기 -> 금액 더하기 -> 더한 값 저장순서로 실행된다.
프로세스A와 B가 동시에 실행될 때, 똑같은 기존 잔액을 A, B가 동시에 읽어오게 된다면 오류가 발생한다.
A가 값을 저장할 때까지 B는 잔액을 읽지 않고 기다려야 한다.
🎈 생산자와 소비자 문제
상호 배제를 위한 동기화를 하지 않았을 때 발생하는 문제다.
생산자 프로세스는 버퍼에 값을 넣고, 총합 값을 1 증가시킨다.
소비자 프로세스는 버퍼에 값을 꺼내고, 총합 값을 1 감소시킨다.
버퍼에 값을 넣는 과정을 생략하고 총합 값을 증가/감소 시키는 코드를 구현해보면, 실행할 때마다 값이 달라진다.
from multiprocessing import Process, Value
import time
import random
def producer(count):
for _ in range(100):
current = count.value
time.sleep(random.random())
count.value = current + 1
print(f"produce {count.value}")
def consumer(count):
for _ in range(100):
current = count.value
time.sleep(random.random())
count.value = current - 1
print(f"consume {count.value}")
if __name__ == '__main__':
share_count = Value("i", 0)
produce = Process(target=producer, args=(share_count,))
consume = Process(target=consumer, args=(share_count,))
produce.start()
consume.start()
produce.join()
consume.join()
print(f"end {share_count.value}")
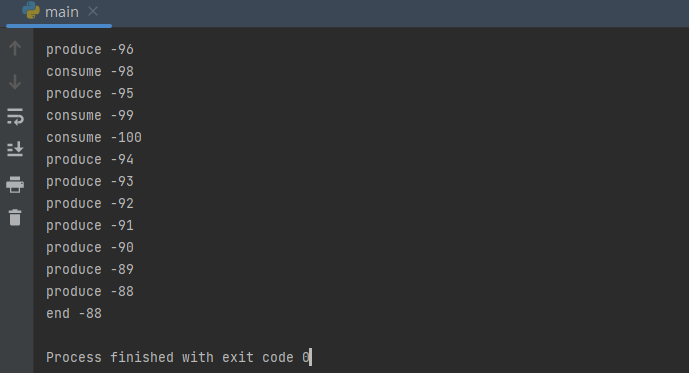
여러 프로세스에서 접근하는 공동의 자원을 공유자원이라고 한다. 전역변수, 파일, 입출력장치, 보조기억장치 등이 있다.
위 코드에서 생산자가 실행되는 도중에 소비자가 값을 읽은 것처럼, 공유 자원에 동시에 접근했을 때 문제가 발생하는 코드를 임계구역 이라고 한다.
이렇게 임계구역의 코드를 실행해서 문제가 발생한 경우를 레이스 컨디션 이라고 한다
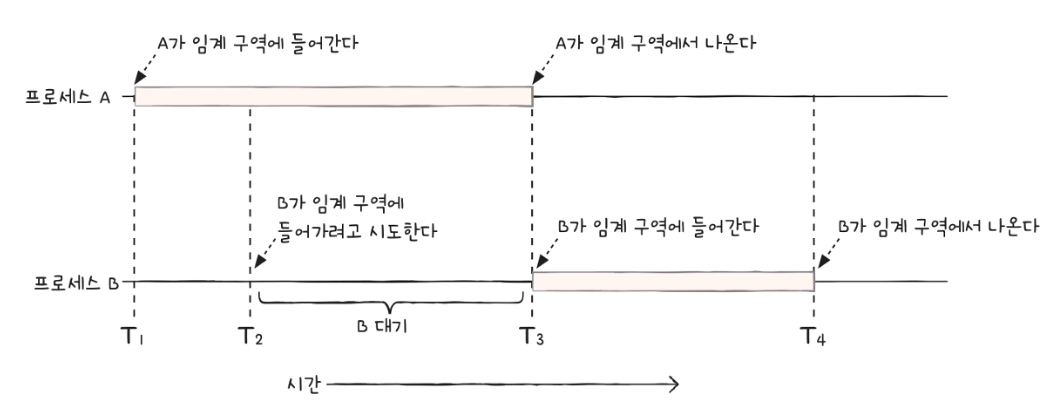
🎈 상호 배제를 위한 동기화를 위한 원칙
운영체제는 세 가지 원칙 하에 임계 구역 문제를 해결한다.
- 상호 배제 : 한 프로세스가 임계 구역에 들어가면 다른 프로세스는 임계 구역에 들어갈 수 없다.
- 진행 : 임계 구역에 아무 프로세스도 없으면 프로세스가 들어갈 수 있다.
- 유한 대기 : 임계 구역에 들어가고 싶은 프로세스는 언젠가는 들어갈 수 있어야 한다. (무한정 대기해서는 안된다)
