[제 1장] 데이터 모델링의 이해
📖 데이터모델링
📑 개념
- 정보시스템을 구축하기 위한 데이터 관점의 업무 분석 기법
- 현실 세계의 데이터(what)에 대해 약속된 표기법에 의해 표현하는 과정
- 데이터베이스를 구축하기 위한 분석, 설계의 과정
📑 모델링 유의점
유일중
- 비유연성 (Inflexibility)
- 비일관성 (Inconsistency)
- 중복 (Duplication)
※ 연계성↑ = 유연성↓
📑 모델링 특징
추단명
- 추상화, 단순화, 명확화
📑 모델링 분류
-
개념적 데이터 모델링
: 추상화 수준이 높고 업무 중심적, 포괄적인 수준의 모델링 진행
: 전사적 데이터 모델링, EA 수립 시 많이 이용 -
논리적 데이터 모델링
: 시스템으로 구축하고자 하는 업무에 대해 key, 속성, 관계 등을 정확하게 표현
: 재사용성 높음 -
물리적 데이터 모델링
: 실제로 DB에 이식할 수 있도록 성능, 저장 등 물리적인 성격을 고려하여 설계
📑 ERD 작성 순서
1) 엔터티 그리기 (도출)
2) 엔터티 배치
3) 엔터티간 관계 설정
4) 관계명 기술
5) 관계의 참여도 기술
6) 관계의 필수여부 기술
※ 관계 명칭 중요 (ERD에 반드시 표기할 필요는 없음)
※ 왼쪽 상단 → 오른쪽 하단
※ UML = 객체지향
📑 ANSI-SPARC 3단계 구조
※ ANSI-SPARC : DB 구축을 위한 추상적인 설계 표준
-
외부 스키마 (External Schema)
: 개별 사용자 관점 -
개념 스키마 (Conceptual Schema)
: 모든 사용자 관점을 통합한 조직 전체 관점의 통합적 표현
: 전체 데이터베이스의 논리적 구조 기술
: DB에 저장되는 데이터와 그들간의 관계를 표현하는 스키마 -
내부 스키마 (Internal Schema)
: DB에 어떤 데이터가 어떻게 저장되어 있는가를 기술
📖 엔터티 (Entity)
📑 개념
- 실체, 객체
- 사람, 장소, 물건, 사건, 개념 등과 같은 명사에 해당
- 업무상 관리가 필요한 것에 해당
- 저장되기 위한 어떤 것(Thing)에 해당
📑 엔터티 특징
-
반드시 해당 업무에서 필요하고 관리하고자 하는 정보
(업무 프로세스에 의해 이용되어야 함) -
유일한 식별자에 의해 식별이 가능해야 함
-
지속적으로 존재하는 2개 이상의 인스턴스의 집합
-
반드시 속성이 있어야 함
-
다른 엔터티와 최소 한 개 이상의 관계가 있어야 함
(통계성, 코드성 엔터티는 생략 가능)⩗ 엔터티=table / 속성=colums / 인스턴스=row 생각하기
📑 엔터티 명명 기준
- 업무 용어를 사용
- 약어 사용 자제
- 단수 명사 사용
- 유일한 이름 부여
- 생성하는 의미대로 이름 부여
📑 분류
<종류>
-
독립 엔터티 (Kernel Entity, Master Entity)
: 사람, 물건, 장소 등과 같이 현실 세계에 존재하는 엔터티 -
업무중심 엔터티 (Transaction Entity)
: Transaction이 실행되면서 발생하는 엔터티 -
종속 엔터티 (Dependent Entity)
: 주로 1차 정규화로 인해 관련 중심엔터티로부터 분리된 엔터티 -
교차 엔터티 (Intersaction Entity)
: 다대다(M:M)의 관계를 해소하려는 목적으로 만들어진 엔터티 (M:M⇒1:M)
<발생시점에 따라>
기중행
-
기본/키 엔터티 (Fundamental/Key Entity)
: 독립적으로 생성 가능
: 주식별자를 상속받지 않고 자신의 식별자를 가짐
: 다른 엔터티의 부모 역할 -
중심 엔터티 (Main Entity)
: 기본 엔터티로부터 발생
: 해당 업무에서 중심 역할 (ex. 계약, 대출, 주문 등) -
행위 엔터티 (Active Entity)
: 2개 이상의 부모 엔터티로부터 발생
: 자주 내용이 바뀌거나 데이터 양이 증가 (ex. 변경 이력, 주문 목록 등)
<유무에 따라>
개유사
-
개념 엔터티 (Conceptual Entity)
: 물리적인 형태는 없고 관리해야 할 개념적 정보 (회사, 조직 등) -
유형 엔터티 (Tangible Entity)
: 물리적인 형태가 있고 안정적이며 지속적으로 활용 (사원, 상품 등) -
사건 엔터티 (Event Entity)
: 업무 수행에 따라 비교적 많이 발생 (주문, 배송 등)
📑 엔터티, 인스턴스, 속성, 속성값의 관계
-
1개의 엔터티는 2개 이상의 인스턴스의 집합이여야 한다
-
1개의 엔터티는 2개 이상의 속성을 갖는다
-
1개의 속성은 1개의 속성값을 갖는다
📑 엔터티 사이에서 관계 도출할 때 체크사항
1) 두 개의 엔터티 사이에 관심있는 연관규칙이 존재하는가?
2) 두 개의 엔티티 사이에 정보의 조합이 발생되는가?
3) 업무기술서, 장표에 관계연결에 대한 규칙이 서술되어 있는가?
4) 업무기술서, 장표에 관계연결을 가능하게 하는 동사(Verb)가 있는가?
📖 속성
📑 개념
-
업무에서 필요로 하는 인스턴스에서 관리하고자 하는 의미상 더 이상 분리되지 않는 최소의 데이터 단위
-
도메인(Domain) : 각 속성을 가질 수 있는 값의 범위. 엔터티 내에서 속성에 대한 데이터 타입과 크기, 제약사항을 지정하는 것
📑 분류
<엔터티 구성방식에 따라>
- PK, FK, 일반
*<속성의 특성에 따라>+
기설파
-
기본 속성 (BASIC)
: 업무상 필요한 데이터에 대해 정의 (ex. 이자율)
: 코드성 데이터, 일련번호, 계산에 의해 생성된 속성 등은 제외 -
설계 속성 (DESIGNED)
: 업무를 규칙화하기 위해 새로 만들거나 변형한 속성
: 코드성 데이터, 일련번호 등 -
파생 속성 (DERIVED)
: 다른 속성의 영향을 받아 발생
: 주로 계산된 값들이 이에 해당 (ex. 이자)
: 가급적 적게 정의하는 것이 좋음
📑 속성 명칭 부여
- 업무에서 사용하는 용어 사용
- 약어 사용 자제
- 서술식 이름 사용 불가
- 유일한 이름 부여
📖 관계
📑 개념
- DB에서 두 개의 엔터티간의 관계
- 존재적 관계, 행위에 의한 관계로 분류 가능
- ERD에서는 관계 구분 하지 않음
- 클래스 다이어그램에서는 구분함 (연관 관계와 의존 관계로 표현)
📑 관계의 표기법
명차사
1) 관계명 = 관계의 이름 (관계 시작점, 끝점)
2) 관계차수 = 두 개의 엔터티 관계에서 참여자의 수를 표현 (1:1, 1:M, M:N)
3) 관계선택사양 : 필수 관계, 선택 관계
📑 관계 읽기
- 기준(Source) 엔터티를 한 개(One) 또는 각(Each)으로 읽는다
- 대상(Target) 엔터티의 관계참여도 즉 개수(하나, 하나 이상)를 읽는다
- 관계선택사양과 관계명을 읽는다
📖 식별자
- 하나의 엔터티에 구성되어 있는 여러 속성들에 대해 각 속성을 구분하기 위한 구분자
📑 식별자 분류
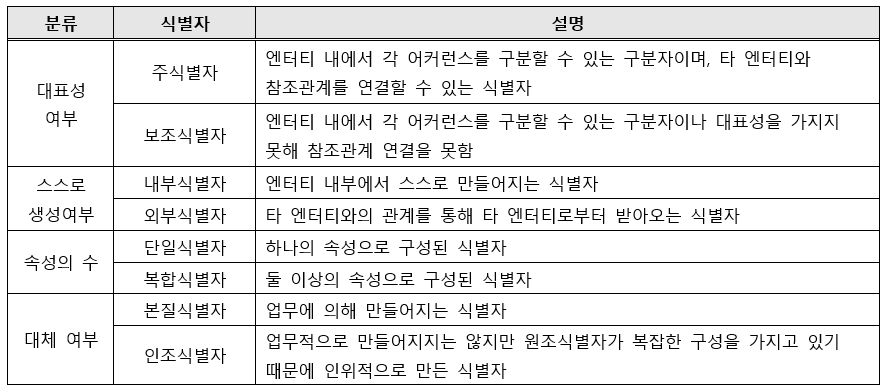
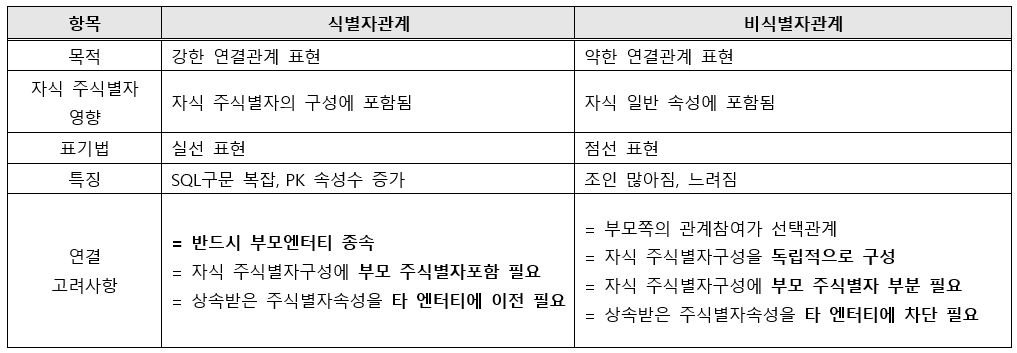
📑 식별자 / 비식별자
📑 주식별자 특징
유소불존
1) 유일성 : 주식별자에 의해 엔터티 내에 모든 인스턴스를 유일하게 구분함
2) 최소성 : 주식별자를 구성하는 속성의 수는 유일성을 만족하는 최소의 수가 되어야 함
3) 불변성 : 주식별자가 한 번 특정 엔터티에 지정되면 그 식별자의 값은 변하지 않아야 함
4) 존재성 : 주식별자가 지정되면 반드시 데이터 값이 존재함 (NULL 불가)
[제 2장] 데이터 모델과 성능
📖 성능 데이터 모델링
📑 개념
- 분석 및 설계 단계에서부터 성능과 관련한 데이터 모델링을 수행하는 것
- 데이터의 증가가 빠를수록 성능 저하에 따른 성능 개선 비용은 증가
- 데이터 모델은 성능을 튜닝하면서 변경이 될 수 있는 특징 있음
- 분석/설계 단계에서 수행하면 성능 저하에 따른 Rework비용을 최소화 할 수 있는 기회를 가짐
📑 성능 데이터 모델링 순서
1) 정규화
2) 용량 산정
3) 트랜잭션 유형 파악
4) 반정규화
5) 이력모델, PK/FK, 슈퍼/서브 타입 조정
6) 검증
📖 정규화
📑 개념
-
정의 : 이상 현상이 있는 릴레이션(표)를 분해하여 이상 현상을 없애는 과정
(데이터가 꼬이는 것을 막기 위해 테이블을 잘게 나누는 것) -
장점
: 이상 현상 제거 (삽입 이상, 갱신 이상, 삭제 이상)
: 데이터 추가(확장) 용이 (insert, update 쉬워짐)
: 응용 프로그램 생명 연장 -
단점 : 릴레이션 JOIN 증가, SELECT 기능 저하 가능성
📑 정규화 단계
도부이결다조
-
제1정규형(INF)
: 중복 속성에 대한 분리
: 원자값 아닌 도메인 분해
(원자성 = 모든 속성은 반드시 하나의 값만 가져야 한다)
: 1차 정규형 위배 = 다중값을 가질 때, 반복 그룹을 가질 때 -
제2정규형
: 모든 속성은 반드시 모든 기본키에 종속되어야 한다
(기본키 일부에만 종속되어서는 안된다)
: 2차 정규형 위배 = 부분 종속 -
제3정규형
: 기본키가 아닌 모든 속성간에는 서로 종속될 수 없다
: 3차 정규형 위배 = 이행 종속
- 보이스-코드 (BCNF ; Boyce-Codd Normal Form)
: 결정자가 후보키가 아닌 것 제거 - 제4정규형 : 다치종속 제거
- 제5정규형 : 조인종속 제거
📖 반정규화
📑 개념
-
정의 : 데이터를 중복하여 성능을 향상시키기 위한 기법
-
넓은 의미 : 성능을 향상시키기 위해 정규화된 데이터 모델에서 중복, 통합, 분리 등을 수행하는 모든 과정
즉, 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발/운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링 기법
-
데이터 무결성이 깨질 위험성 존재함
📑 사용 이유
- 데이터를 조회할 때 디스크 I/O량이 많아서 성능이 저하될 것이 예상되는 경우
- 경로가 너무 멀어 조인으로 인한 성능 저하가 예상될 경우
- 칼럼을 계산하여 읽을 때 성능이 저하될 것이 예상되는 경우
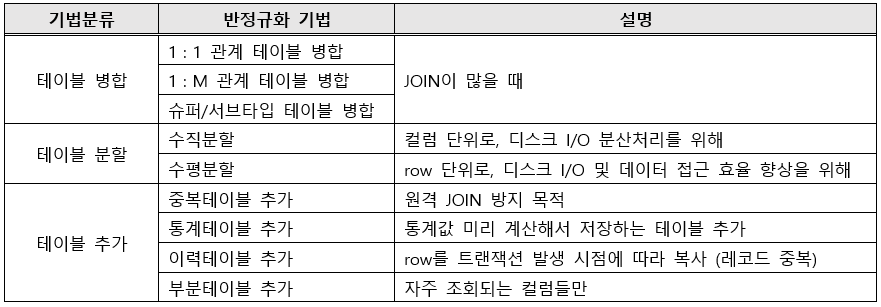
📑 반정규화 분류
<칼럼의 반정규화>
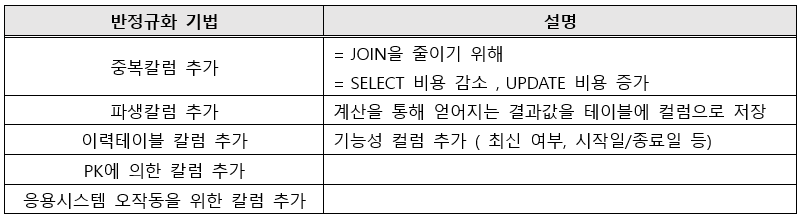
<테이블의 반정규화>
📑 반정규화 절차
-
대상 조사
: 범위 처리 빈도수 조사
: 대량의 범위 처리 조사
: 통계성 프로세스 조사
: 테이블 조인 개수 -
다른 방법 유도 검토
: 뷰(VIEW) 테이블
: 클러스터링 적용
: 인덱스의 조정
: 응용애플리케이션 -
반정규화 적용
: 테이블 반정규화
: 속성의 반정규화
: 관계의 반정규화
📑 반정규화의 대상에 대해 다른 방법으로 처리
- 지나치게 많은 조인(JOIN)이 걸려 데이터를 조회하는 작업이 기술적으로 어려울 경우 뷰(VIEW) 사용
- 대량의 데이터처리나 부분처리에 의해 성능이 저하되는 경우 클러스터링을 적용하거나 인덱스를 조정
- 대량의 데이터는 Primary Key의 성격에 따라 부분적인 테이블로 분리 (파티셔닝 기법)
- 응용 애플리케이션에서 로직을 구사하는 방법 변경
※ Chaing : 데이터가 커서 여러 블록에 나누어 저장하는 현상
⇒ 해결책 : DB_BLOCK SIZE를 크게하여 최소화 가능
📖 PK/FK, 슈퍼/서브 타입
📑 PK순서 결정 기준
인덱스 정렬구조를 이해한 상태에서 인덱스를 효율적으로 이용할 수 있도록 지정해야 한다.
즉, 인덱스의 특징은 여러 개의 속성이 하나의 인덱스로 구성되어 있을 때 앞쪽에 위치한 속성의 값이 비교자로 있어야 효율이 좋다.
앞쪽에 위차한 속성 값이 가급적 ‘=’ 아니면 최소한 범위 ‘BETWEEN’ ‘<>’가 들어와야 인덱스를 이용할 수 있다.
(EQUAL = 조건이 먼저, 그 다음 범위 조건)
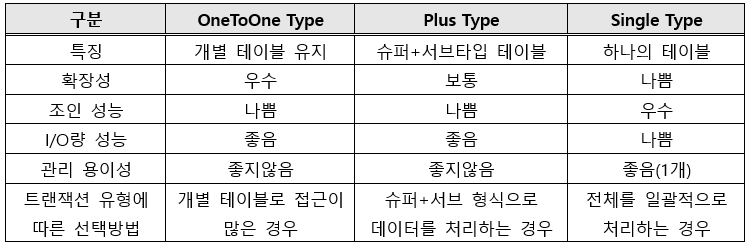
📑 슈퍼/서브 타입 데이터 모델의 변환기술
1) 개별로 발생되는 트랜잭션에 대해서는 개별 테이블로 구성 (Rolldown)
2) 슈퍼+서브타입에 대해 발생되는 트랜잭션에 대해서는 슈퍼+서브타입 테이블로 구성 (Identity)
3) 전체를 하나로 묶어 트랜잭션이 발생할 때는 하나의 테이블로 구성 (Rollup)
※ 트랜잭션은 항상 전체를 통합하여 분석 처리하는데 슈퍼-서브타입이 하나의 테이블로 통합되어 있으면 하나의 테이블에 집적된 데이터만 읽어 처리할 수 있기 때문에 다른 형식에 비해 성능이 더 우수 (조인감소)
📑 인덱스
- DB 테이블에 대한 검색 성능의 속도를 높여주는 자료 구조
- 언제 사용되는 지 : 부정형, Like 함수, 묵시적 형변환
- 인덱스 사용 시 성능 감소 (insert, update, delete)
CREATE index [인덱스이름] on [테이블명] (칼럼명);
📖 분산 데이터베이스
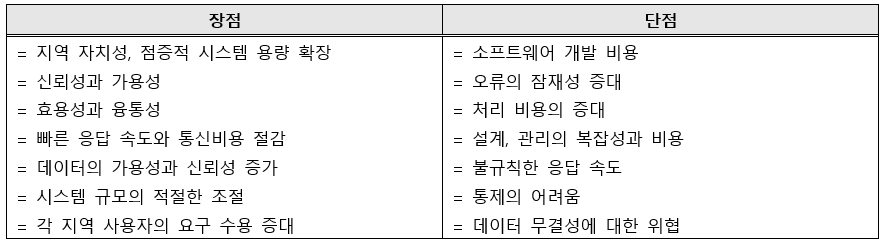
장단점
📑 분산 데이터베이스의 효율성이 높은 경우
1) 실시간 동기화가 요구되지 않을 때
2) 실시간의 업무적 특성을 가지고 있을 때
3) 특정 서버에 부하가 집중돼 이를 분산할 때
4) 백업 사이트를 구성할 때
※ Global Single Instance(GSI)는 통합된 한 개의 인스턴스 즉, 통합 데이터베이스 구조를 의미 (대치되는 개념)
