[알고리즘] 크루스칼(Kruskal) , 프림(Prim) , 백준 1647
오늘은 크루스칼과 프림 알고리즘에 대해 알아보겠습니다.
크루스칼과 프림 알고리즘은 모두 그래프 이론에서 사용되는 알고리즘으로 , 최소 비용 신장 트리(Minimum Spanning Tree , MST)를 찾는 데 사용됩니다.
두 알고리즘 모두 매 순간마다 최적의 해를 찾는 것으로 , greedy 방식을 이용해 최소 비용 신장 트리를 찾습니다.
⭐️ 최소 신장 트리 (MST)란 ?
어떤 그래프의 신장 트리란 그 그래프의 모든 정점을 포함하면서 사이클을 형성하지 않는 부분 그래프입니다. 즉 , 한 그래프 내에서 여러 개의 신장 트리가 존재할 수 있다는 뜻입니다. 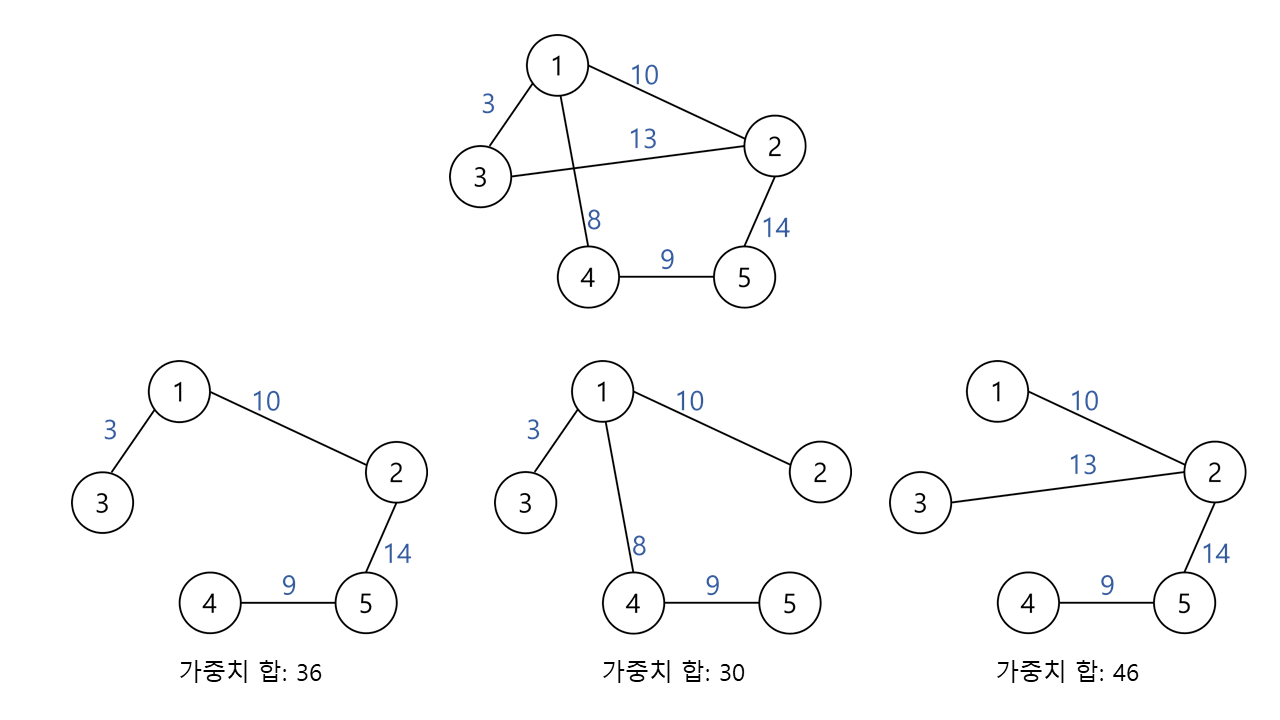 이미지 출처
이미지 출처
최소 신장 트리란 주어진 그래프의 신장 트리들 중에서 간선의 가중치 합이 최소인 트리를 뜻합니다. 위의 이미지를 예시로 들면 가중치 합이 30인 신장 트리가 MST입니다.
⭐️ 크루스칼 (Kruskal) 알고리즘
크루스칼 알고리즘이 MST를 찾는 과정은 이렇습니다.
1. 정점들을 간선으로 연결시켜 두지 않는다.
2. 간선들을 오름차순으로 정렬한다.
3. 오름차순으로 정렬된 간선들을 순차적으로 정점과 연결시킨다.(사이클이 존재하는지 판단한다.)
이러한 과정을 통해 MST를 찾는데 , 사이클이 존재하는지는 서로소 집합 알고리즘을 통해 확인합니다.
크루스칼 알고리즘의 시간 복잡도에는 두 가지 알고리즘의 영향을 받습니다.
-
간선의 정렬
간선을 어떤 방식으로 정렬하느냐에 따라 시간 복잡도가 정해집니다.
JS 에서의 sort 메소드는 Timsort를 이용하기 때문에 sort()를 이용할 경우 O(ElogE)의 시간 복잡도를 가지게 됩니다. -
Union Find 연산
Union Find 연산은 O(log V)의 시간 복잡도를 갖습니다. (트리의 검색)
따라서 , 크루스칼 알고리즘은 정렬 시간 복잡도가 Union-Find 연산의 시간 복잡도보다 크므로 (ElogE > logV) , O(ElogE)의 시간 복잡도를 가집니다.
⭐️ 서로소 집합 (Disjoint-set)
서로소 집합이란 , 집합 내의 원소들끼리 어떤 공통된 요소도 가지고 있지 않은 집합을 말합니다. [1,2,3] , [4,5]와 같은 예시를 들 수 있겠죠.
서로소 집합을 구현할 때는 트리 구조를 이용하여 집합을 표현합니다.
-
집합 생성 (Make Set)
먼저 자기 자신을 가리키는 원소들의 집합을 생성합니다. 각 집합의 부모는 자기 자신으로 설정됩니다. -
집합 합치기 (Union)
두 원소가 속한 집합을 찾아서 두 집합을 합칩니다. 이 과정에서 root node를 찾아 같은 원소에 속해있는지를 판단하는 데 , root가 같다면 같은 집합임으로 합치는 과정이 종료되고 , 다르다면 한 집합의 root를 다른 집합의 root로 설정합니다. (하나의 트리를 다른 트리의 하위 트리로)
// root 노드를 합치는 함수
function unionParent(arr, a, b) {
a = getParent(arr, a);
b = getParent(arr, b);
// path compression 수행
a < b ? (arr[b] = a) : (arr[a] = b);
}
// 부모를 가져오는 함수
function getParent(arr, el) {
// 해당 노드가 root 노드인지 판단
if (arr[el] === el) return el;
// root 노드가 아니라면 상위 노드가 root 노드인지 판단
return getParent(arr, arr[el]);
}
// 부모가 같은지 알려주는 함수
function findParent(arr, a, b) {
a = getParent(arr, a);
b = getParent(arr, b);
return a === b;
}이런 알고리즘을 Union-Find 라고도 부르는데 , Union-Find의 성능은 트리의 높이에 의존합니다. 트리를 순차적으로 순회하기 때문에 , 트리의 높이가 낮을 수록 연산 횟수가 줄어들겠죠. 트리의 높이를 최소화 하기 위해서 2가지의 방법을 사용합니다.
-
경로 압축 (Path Compression)
find 연산 혹은 , union 연산을 진행할 때 해당 노드의 부모를 상위 노드가 아닌 root 노드로 바로 지정해주는 것입니다. 위 코드에서는 union 과정에서 root 노드를 바로 합쳐주는 것을 볼 수 있습니다. path compression을 수행하면 O(1)만에 find를 수행할 수 있습니다. -
유니온 바이 랭크 (Union By Rank)
트리의 사이즈 (노드의 수 or 트리의 높이)가 낮은 트리를 더 높은 트리에 붙여주는 방법입니다. 시간 복잡도는 대략적으로 O(log n)입니다.
⭐️ 백준 1647 : 도시 분할 계획
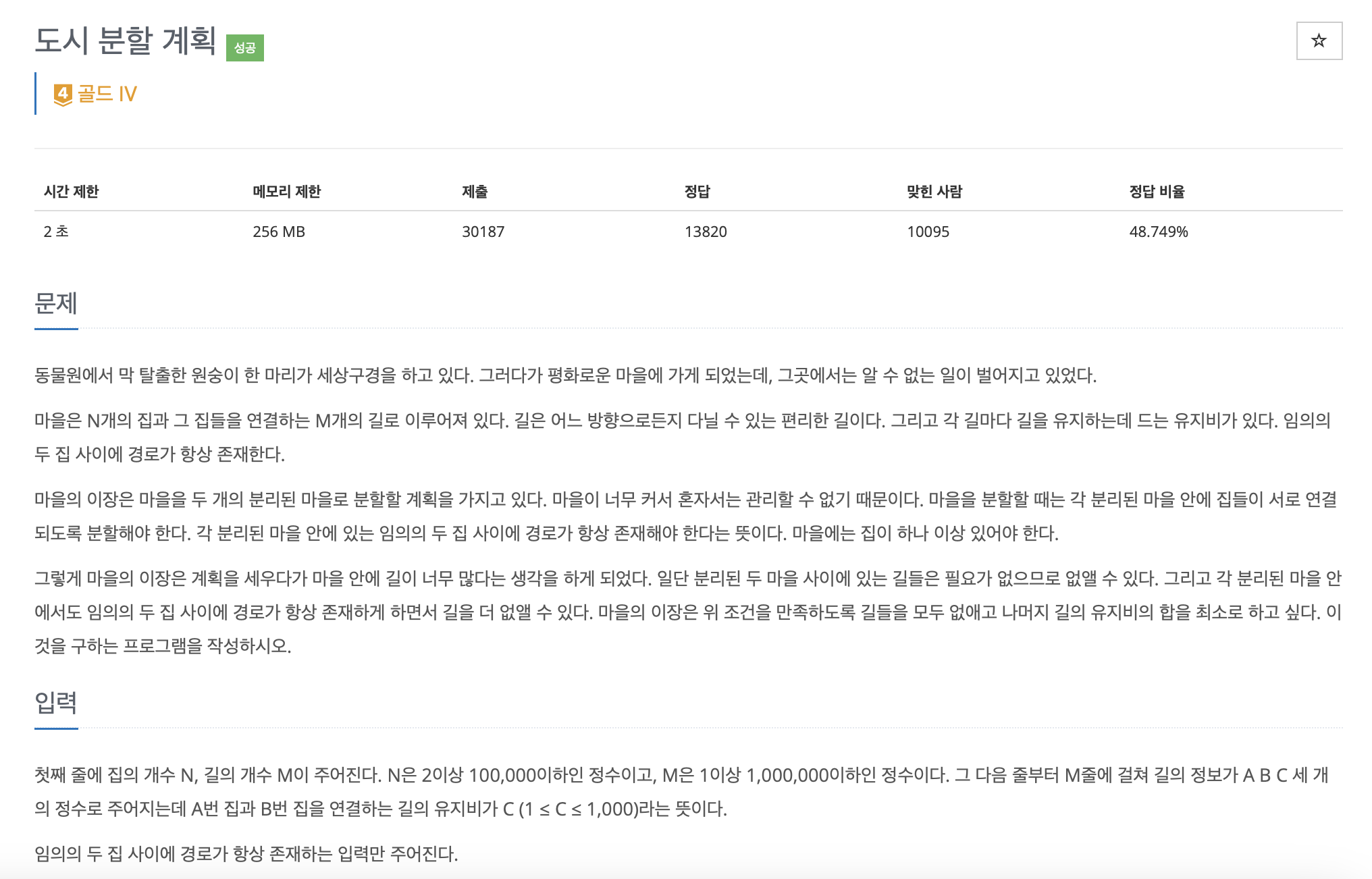
⭐️ 코드
function solution(input) {
const [V, E] = input[0];
// 길의 가중치를 오름차순으로 정렬
const streets = input.slice(1).sort((a, b) => a[2] - b[2]);
// 각 노드의 root node 설정 (현재는 자신이 부모)
const parentArr = Array(V + 1)
.fill(0)
.map((_, idx) => idx);
let cnt = 0;
let i = 0;
const answer = [];
// 간선의 갯수는 V-1개이므로 , V-1개의 간선이 이어졌으면 실행 종료
// 간선 설정이 안되는 경우도 있을 수 있으므로 , 인덱스 설정
while (cnt < V - 1 && i < E) {
const [a, b, w] = streets[i];
// 같은 트리(서로소 집합인지 아닌지)에 속해 있는지 판단
if (!findParent(parentArr, a, b)) {
// 같은 root 노드를 공유하고 있지 않다면 ,
unionParent(parentArr, a, b);
answer.push(w);
cnt++;
}
i++;
}
console.log(answer.reduce((acc, val) => acc + val) - Math.max(...answer));
}
function unionParent(arr, a, b) {
a = getParent(arr, a);
b = getParent(arr, b);
// path compression 수행
a < b ? (arr[b] = a) : (arr[a] = b);
}
function getParent(arr, el) {
// 해당 노드가 root 노드인지 판단
if (arr[el] === el) return el;
// root 노드가 아니라면 상위 노드가 root 노드인지 판단
return getParent(arr, arr[el]);
}
function findParent(arr, a, b) {
a = getParent(arr, a);
b = getParent(arr, b);
return a === b;
}
const rl = require("readline").createInterface({
input: process.stdin,
output: process.stdout,
});
const input = [];
rl.on("line", (line) => {
input.push(line.split(" ").map(Number));
}).on("close", () => {
solution(input);
process.exit();
});
⭐️ 프림 알고리즘
마찬가지로 MST를 찾는 프림 알고리즘의 동작 과정을 알아보겠습니다.
- 임의의 정점을 선택하여 트리의 시작점으로 선택합니다.
- 선택된 정점과 연결된 간선 중에서 가장 가중치가 작은 간선을 선택하여 트리에 추가합니다.
- 위 과정을 트리가 모든 정점을 포함할 때까지 반복합니다.
프림 알고리즘을 구현할 때는 보통 우선 순위 큐를 구현하여 사용합니다.
class MinHeap {
constructor() {
this.heap = [];
}
logTree() {
console.log(this.heap);
}
getLength() {
return this.heap.length;
}
getLeftChildIdx(index) {
return 2 * index + 1;
}
getRightChildIdx(index) {
return 2 * index + 2;
}
getParentIdx(index) {
return Math.floor((index - 1) / 2);
}
insert(info) {
const node = { weight: info[0], vertex: info[1] };
this.heap.push(node);
this.heapifyUp();
}
heapifyUp() {
let index = this.heap.length - 1;
const lastInsertedNode = this.heap[index];
while (index > 0) {
const parentIdx = this.getParentIdx(index);
if (this.heap[parentIdx].weight > lastInsertedNode.weight) {
this.heap[index] = this.heap[parentIdx];
index = parentIdx;
} else break;
}
this.heap[index] = lastInsertedNode;
}
// return and remove
remove() {
if (this.heap.length === 0) return null;
const rootNode = this.heap[0];
if (this.heap.length === 1) this.heap = [];
else {
this.heap[0] = this.heap.pop();
this.heapifyDown();
}
return rootNode;
}
heapifyDown() {
let index = 0;
const count = this.heap.length;
const rootNode = this.heap[0];
while (this.getLeftChildIdx(index) < count) {
const leftChildIdx = this.getLeftChildIdx(index);
const rightChildIdx = this.getRightChildIdx(index);
const smallerIdx =
rightChildIdx < count &&
this.heap[rightChildIdx].weight < this.heap[leftChildIdx].weight
? rightChildIdx
: leftChildIdx;
if (this.heap[smallerIdx].weight <= rootNode.weight) {
this.heap[index] = this.heap[smallerIdx];
index = smallerIdx;
} else break;
}
this.heap[index] = rootNode;
}
}
function solution(input) {
const [V, E] = input[0];
const streets = input.slice(1);
const visited = Array(V + 1).fill(0);
const graph = Array.from({ length: V + 1 }, () => []);
for (let i = 0; i < E; i++) {
const [a, b, w] = streets[i];
graph[a].push([w, b]);
graph[b].push([w, a]);
}
const ans = [];
let cnt = 0;
const minHeap = new MinHeap();
minHeap.insert([0, 1]);
while (minHeap.getLength()) {
const { weight: curWeight, vertex: curNode } = minHeap.remove();
if (!visited[curNode]) {
visited[curNode] = 1;
ans.push(curWeight);
cnt++;
if (cnt === V) break;
for (let node of graph[curNode]) {
minHeap.insert(node);
}
}
}
console.log(ans.reduce((acc, val) => acc + val) - Math.max(...ans));
}
const rl = require("readline").createInterface({
input: process.stdin,
output: process.stdout,
});
const input = [];
rl.on("line", (line) => {
input.push(line.split(" ").map(Number));
}).on("close", () => {
solution(input);
process.exit();
});
위 문제를 크루스칼 대신 프림 알고리즘으로 풀이해보았습니다. (백준에서는 메모리 초과로 오류가 나더군요. 정점의 갯수가 최대 10만까지 있어서 그런 것 같습니다.)
크루스칼은 간선 기반 알고리즘이고 , 프림은 정점 기반 알고리즘입니다. 간선이 많을 때는 크루스칼을 이용하는 것이 효율적이고 , 프림 알고리즘은 정점이 많을 때 사용하는 것이 유리합니다.
