🤳 오라클 NVL, NVL2 함수 사용법
-
해당 칼럼의 값이 NULL 값인 경우 특정값으로 출력하고 싶으면 NVL 함수를 사용하고, NULL 값이 아닐 경우 특정값으로 출력하고 싶으면 NVL2 함수를 사용하면 된다.
-
NVL 함수
:NVL 함수는 값이 NULL인 경우 지정값을 출력하고, NULL이 아니면 원래 값을 그대로 출력한다. -
모든 데이터 타입에 적용 가능합니다.
-
전환되는 값의 데이터 타입을 일치시켜야 합니다.
(nvl함수 내 속성의 데이터 타입은 동일해야함 'no comm'이 문자열이므로 comm도 문자열로 변환 필 (to_char(comm)) )- 함수 : NVL("값", "지정값")
🔽

- 함수 : NVL("값", "지정값")
-
NVL2 함수
:NVL2 함수는 NULL이 아닌 경우 지정값1을 출력하고, NULL인 경우 지정값2를 출력한다.- 함수 : NVL2("값", "지정값1", "지정값2") // NVL2("값", "NOT NULL", "NULL")
🔽

- 함수 : NVL2("값", "지정값1", "지정값2") // NVL2("값", "NOT NULL", "NULL")
-
NVL2 함수를 사용할 때 NULL이 아닌경우 자신의 값을 그대로 출력할 수도 있다.
- 예) NVL2(comm, comm, '보너스없음')
-
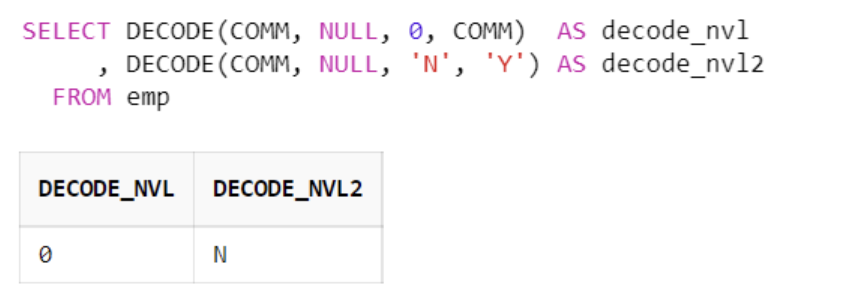
위의 NVL, NVL2 함수를 사용하지 않고 DECODE 함수를 사용하여 같은 결과를 출력할 수 있지만, 용도에 맞는 명시적인 함수를 사용하는 것이 좋다.
🤳 오라클 decode 함수 사용 예제
-
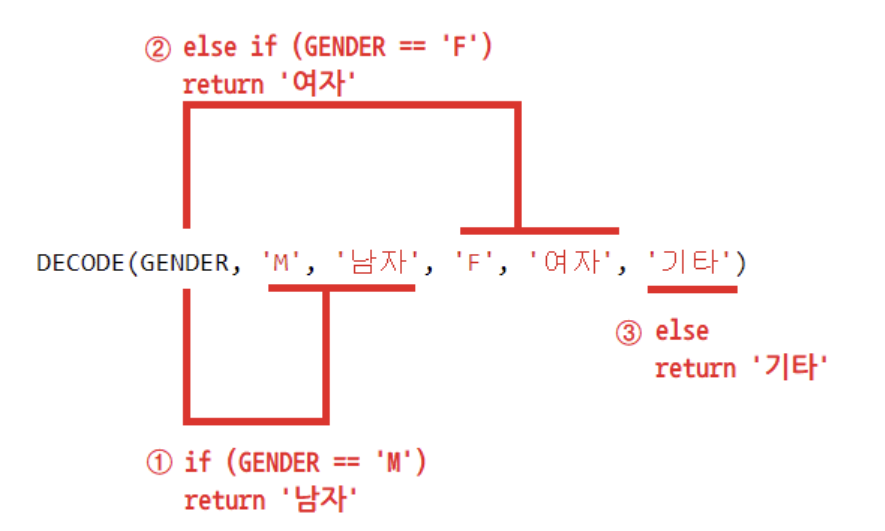
DECODE 함수 사용 예제
: DECODE 함수는 프로그래밍에서의 if else 와 비슷한 기능을 수행한다.- 예) DECODE(컬럼, 조건1, 결과1, 조건2, 결과2, 조건3, 결과3..........)
-
ELSE 부분은 생략이 가능하다. 해당 조건이 없으면 NULL
🔽
🔽
-
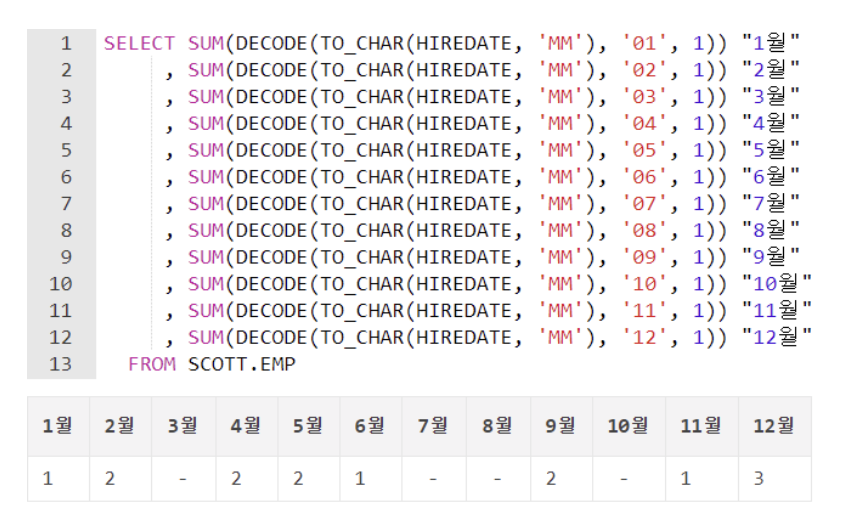
월별, 일별 통계를 산출하거나, 행을 열로 바꿀때 유용하다
🔽
🤳 오라클 case when 표현식
- 오라클에서 DECODE 함수를 대체할 수 있는 기능이 CASE 표현식이며 가독성이 좋고 더 많은 기능을 제공한다.
🔽 오라클 CASE 표현식

🤳 [Oracle] 숫자 천단위 콤마 찍는 방법
-
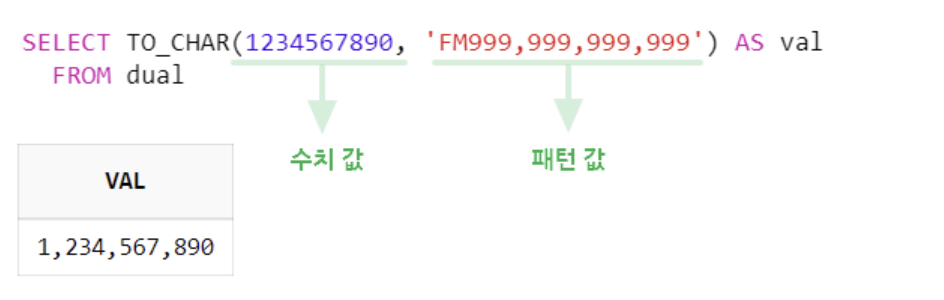
- TO_CHAR 함수를 사용하는 방법
: 수치 값에 천 단위 콤마를 추가하기 위해서는 TO_CHAR 함수를 많이 사용한다.
TO_CHAR 함수를 사용할 때는 두 번째 인자에 수치 값의 길이에 맞게 패턴 값을 부여해야 한다.
패턴 값의 길이가 작을 경우 값을 반환하지 못한다.
패턴 값은 되도록이면 미래에 올 수 있는 최대 길이만큼 미리 선언을 해 놓아야 한다.
🔽
- TO_CHAR 함수를 사용하는 방법
-
※ TO_CHAR 함수 사용 시 주의사항
- 대입할 수치 값의 최대 크기만큼 패턴 값을 선언해 놓아야 한다. (미래에 아주 큰 값이 생길 수 있을 경우 대비)
- 수치 값 보다 패턴 값이 작으면 값을 반환하지 못하고 ######으로 표시된다.
- FM 키워드를 사용하지 않으면 반환된 값의 앞부분에 공백이 추가된다.
🔽

🤳 오라클 TRUNC 함수 사용법 (시간, 소수점 절사)
-
소수점을 절사(버림)하거나 날짜의 시간을 절사 하기 위해서는 TRUNC 함수를 사용한다.
- 사용법 : TRUNC("값", "옵션")
-
TRUNC 함수는 주로 소수점 절사 및 날짜의 시간을 없앨 때 사용한다.
🔽

-
시간 절사 방법
🔽

-
TRUNC(DT, 'DD')와 TRUNC(DT)는 동일한 결과를 출력한다.
-
일자/요일 절사 방법
🔽

-
TRUNC(DT, 'DAY') 해당 주의 일요일의 일자로 초기화한다.
TRUNC(DT, 'YEAR') = TRUNC(DT, 'YYYY') 동일한 결과
TRUNC(DT, 'MONTH') = TRUNC(DT, 'MM') 동일한 결과 -
숫자/소수점 절사 방법
🔽

-
TRUNC(NMB, 1)는 소수점을 반올림하지 않고 절사 한다.
TRUNC(NMB,-1)는 주로 금액 계산 시 1원 단위를 절사 할 때 사용 한다.
🤳 오라클 일부 문자열 추출 substr
-
3번째 자리부터 쭉-
SELECT substr('ABC권경안Z9', 3) FROM DUAL;
C권경안Z9 -
4번째 자리부터 2글자
SELECT substr('ABC권경안Z9', 4, 2) FROM DUAL;
권경 -
우측부터 추출하고 싶다면 마이너스(-) 기호를 사용하면 된다. 우측 2글자
SELECT substr('ABC권경안Z9', -2) FROM DUAL;
Z9
🤳 오답 노트
-
연산자가 있다고 무조건 group by 하는 것이 아니라,
특정 컬럼과 같이 추출할 시, select 에 기재된 컬럼들을
group by에 반드시'모두'기재해야 error가 발생하지 않음. -
nvl 함수내 기재하는 인자들의 데이터 타입은 동일해야함.
ex. nvl(to_char(commission_pct), 'no comm')) -
sum(decode()) as " "-> 가로로 출력, 컬럼의 총계 sum(decode(,1), 컬럼의 특정 속성의 총계 sum(decode(comm,sal)) -
natural join은 ansi 문법, equi 조인에 해당, 여러개의 공통 컬럼을 전부 찾아 조인
from t1
natural join t2 -
using join은 ansi 문법, equi 조인에 해당, 특정 공통 컬럼으로 조인
from t1
join t2
using column
🤳 8장 연습문제 풀이, 오답
연습문제 8장 풀이
8-1)
select employee_id, last_name, salary
from employees
where salary >= avg(salary)
order by salary;
오답)
where salary >= avg(salary)
->
where salary >= (select avg(salary) from employees)
8-2)
select employee_id, last_name
from employees
where employee_id = (select employee_id
from employees
where last_name like '%u%');
오답)
where department_id in (select department_id from employees where employee_id like '%u%')
8-3)
select e.last_name, e.department_name, e.job_id
from employees e, departments d, locations l
where e.department_id = d.department_id
and d.location_id = l.location_id
and l.location_id = 1700
select e.last_name, e.department_name, e.job_id
from employees
where department_id =( select department_id from dr wher lo=1700);
오답)
조인, 서브쿼리 차이
https://inpa.tistory.com/entry/MYSQL-%F0%9F%93%9A-JOIN%EA%B3%BC-%EC%84%9C%EB%B8%8C%EC%BF%BC%EB%A6%AC-%EC%B0%A8%EC%9D%B4-%EB%B0%8F-%EB%B3%80%ED%99%98-%F0%9F%92%AF-%EC%A0%95%EB%A6%AC#%EC%A1%B0%EC%9D%B8join_vs_%EC%84%9C%EB%B8%8C%EC%BF%BC%EB%A6%ACsub_query
8-4) self join
select last_name, salary
from employees
where last_name in select last
오답) 보고한다-> 매니저가 있다
select last_name, salary
from employees
where manager_id in select employee_id from employees where last_name like '%king%' ;
8-5)
select department_id, last_name, job_id
from employees
where department_id in select department_id from departments where department_name = 'Executive';
8-6)
select employee_id, last_name, salary
from employees
where salary >= select avg(salary) from employees
and department_id in (select department_id from departments where last_name like '%u%');
오답) 연산자 우선 순위로 where 조건 다음으로 and가 수행되고, 그 다음에
or 이 수행된다.
8-7)
select last_name, department_id, salary
from employees
where department_id =
(select department_id from departments
where commission_pct is not null)
and salary =
select last_name, department_id, salary
from employees
where (salary, department_id) in
(select department_id from employees
where commission_pct is not null);
8-8)
select last_name
from employees
where employee_id not in select manager_id from employees;
오답) where manager_id is not null
8-9)
select department_id, department_name
from departments
where department_id in (select department_id from employees
where employee_id is null)
오답) 내부 쿼리를 돌려 보니까 null이 들어가면 조건문이 false가 된다.
IN, NOT IN 문 안에 서브쿼리 사용시에는 주의 하셔야 될 경우가 있습니다.
NOT IN문 서브쿼리의 결과 중에 NULL이 포함되는 경우 데이터가 출력되지 않기 때문에
조회 컬럼에 IS NOT NULL 조건을 주셔야 합니다.
NULL은 논리적으로 비교할 수 없는 연산이기 때문에
값이 없게 되는 것이죠.
오라클에서 NULL 비교를 위해 IS NULL, IS NOT NULL을 제공하는 이유가 그 것 입니다.
그래서! 서브쿼리 내에 조회컬럼이 IS NOT NULL인 조건을 주어 NULL 인 데이터를 빼고
조회를 하셔야 원하는 데이터를 추출 할 수 있습니다.
8-10) self join
8-11)
select employee_id, last_name
from employees e
where exists (select i.employee_id from employees i
where e.manager_id = i.employee_id);
오답)
<EXISTS의 특징>
(1) EXISTS는 오직 서브쿼리만 쓸 수 있다.
(2)서브쿼리에서 조인을 사용한다.
(3)EXISTS는 서브쿼리의 결과가 있느냐 없느냐만 체크한다.
(IN 이 WHERE 조건절에 해당하는 레코드의 컬럼값을 출력하는 것과는 대비하여-)
*EXISTS는 존재하느냐 존재하지 않느냐의 여부만 체크하기 때문에 서브쿼리의 SELECT 리스트에는 등장하는 값과는 상관없이 서브쿼리의 결과로 반환되는 로우가 있느냐 없느냐만 중요한 것이다.
<NOT IN과 NOT EXISTS>
IN과 EXISTS는 동일한 결과값을 출력한다.
반면 NOT IN과 NOT EXISTS는 결과값이 다를 수 있다. 바로 NOT IN 은 NULL 값을 포함하지 않기 때문이다.
8-12)
select e.employee_id, e.last_name, d.department_name department
from employees e, departements d
where
order by department_name
오답)
스칼라 서브쿼리
SELECT 절에 사용하는 서브 쿼리로써 단순한 JOIN을 대체할 목적으로 사용되는 경우가 많다.
서브쿼리에 조건에 따라 반드시 하나의 값을 출력하게 되며(단 한 개의 행을 출력한다는 의미가 아님), 만약에 서브 쿼리에 결과 데이터가 없을 경우 NULL 값을 리턴하다. 어떤 면에서는 OUTERJOIN과 다소 비슷한 역할을 하기도 한다.
8-13)
with summary as
select d.department_name, sum(e.salary) dept_total
from employees e, departments d
where e.department_id = d.department_id
group by d.department_name)
select department_name, sum(e.salary)
from summary
where sum(e.salary) > select sum(dept_total)*1/8 from summary
오답)
서브쿼리를 WITH 절로 만들어서 테이블을 사용하듯 사용할 수 있다.
특히 여러 번 반복되는 서브쿼리를 WITH 절로 만들어서 사용하면 쿼리의 성능을 높일 수 있다.