Hash
데이터를 key-value 형태로 저장하고 관리하는 데 사용되는 자료형
Hash Function을 사용해 데이터를 저장하고 검색하며 높은 효율성을 제공
HashMap,HashSet,HashTable등이 있음
Java는 직접적으로 Set, Map 자료형만을 제공하지는 않음. 다만 이러한 인터페이스를 구현한 다양한 자료형 제공
Set 구현체
HashSet: 해시 테이블 기반, 순서 보장 없음LinkedHashSet: 해시 테이블과 이중 연결 리스트를 사용하여 삽입 순서 보장TreeSet: 이진 트리 기반, 요소를 정렬된 상태로 유지
Map 구현체
HashMap: 해시 테이블 기반, 순서 보장 없음LinkedHashMap: 삽입 순서를 보장하는 해시 테이블TreeMap: 키를 정렬된 상태로 유지하는 이진 트리 기반 MapHashtable: 동기화 지원, 순서 보장 없음
HashMap
특징
- key-value 형태로 데이터를 저장하는 자료구조
- 중복 키 비허용, 값은 상관없음
- 순서가 유지되지 않음: 내부적으로 해시 테이블을 사용하기 때문에 저장된 순서를 보장하지 않음
- null 허용: key로 하나의 null 허용, 값은 여러 null 허용
- 스레드에 안전하지 않음: 멀티스레드 환경에서는 외부에서 동기화 처리하거나
ConcurrentHashMap사용
주요 메서드
| 메서드 | 설명 |
|---|---|
put(K key, V value) | 키와 값을 저장. 동일 키가 있으면 기존 값을 대체 |
get(Object key) | 키에 해당하는 값을 반환 |
remove(Object key) | 키에 해당하는 키-값 쌍을 제거 |
containsKey(Object key) | 특정 키가 존재하는지 확인 |
containsValue(Object value) | 특정 값이 존재하는지 확인 |
size() | 저장된 키-값 쌍의 개수를 반환 |
isEmpty() | HashMap이 비어 있는지 확인 |
clear() | 모든 키-값 쌍을 제거 |
keySet() | 모든 키를 반환(Set 형태) |
values() | 모든 값을 반환(Collection 형태) |
entrySet() | 키-값 쌍의 집합을 반환(Set 형태) |
사용
- 데이터를 key-value 형태로 저장하고, 빠르게 검색할 때
- 캐싱, 설정값 저장, 빈도 계산 등
HashSet
특징
- 중복되지 않는 값만 저장하는 자료구조
- 내부적으로
HashMap을 기반으로 동작. 값은 해시 테이블의 키로 저장함 - 순서 유지 X
- 하나의 null 값만 허용
주요 메서드
| 메서드 | 설명 |
|---|---|
add(E e) | 값을 추가. 중복된 값은 추가되지 않음 |
remove(Object o) | 특정 값을 제거 |
contains(Object o) | 특정 값이 존재하는지 확인 |
size() | 저장된 값의 개수를 반환 |
isEmpty() | HashSet이 비어 있는지 확인 |
clear() | 모든 값을 제거 |
iterator() | 저장된 값을 순회할 수 있는 Iterator를 반환 |
addAll(Collection<? extends E> c) | 다른 컬렉션의 모든 요소를 추가 |
retainAll(Collection<?> c) | 특정 컬렉션과의 교집합만 유지 |
removeAll(Collection<?> c) | 특정 컬렉션에 포함된 요소를 모두 제거 |
사용
- 중복을 허용하지 않는 고유한 값 저장 시 사용
- 유일한 ID 저장, 중복 제거
HashTable
특징
- key-value 쌍으로 데이터를 저장
- Thread-safe: 동기화된 메서드를 제공하여 멀티스레드 환경에서 안전하게 사용 가능
- null 비허용: key, value 모두
- 성능은
HashMap에 비해 느림
주요 메서드
대부분 HashMap과 같음
사용
- 동기화가 필요한 환경에서 key-value 쌍을 관리 시 사용
- 멀티스레드 환경의 공유 데이터
Hash 자료형 비교
| 특징 | HashMap | HashSet | Hashtable |
|---|---|---|---|
| 데이터 구조 | 키-값 (key-value) | 값 (value) | 키-값 (key-value) |
| 중복 허용 여부 | 키 중복 불가, 값 중복 가능 | 중복 불가 | 키 중복 불가, 값 중복 가능 |
| null 허용 여부 | 키와 값에서 null 허용 | 값에서 null 허용 | 키와 값에서 null 허용 안 함 |
| 스레드 안전성 | 비동기 | 비동기 | 동기화 지원 |
| 성능 | 빠름 | 빠름 | 느림 |
| 순서 보장 여부 | 순서 없음 | 순서 없음 | 순서 없음 |
class Solution {
public int solution(int n, int[] lost, int[] reserve) {
Set<Integer> lostSet = new HashSet<>();
Set<Integer> reserveSet = new HashSet<>();
for(int num : lost) lostSet.add(num);
for(int num : reserve) {
if(lostSet.contains(num)) {
lostSet.remove(num);
} else {
reserveSet.add(num);
}
}
for(int l: new HashSet<>(lostSet)) {
if(reserveSet.contains(l - 1)) {
reserveSet.remove(l - 1);
lostSet.remove(l);
} else if (reserveSet.contains(l + 1)) {
reserveSet.remove(l + 1);
lostSet.remove(l);
}
}
return n - lostSet.size();
}
}- lostSet을 순회하면서 삽입, 삭제를 진행하면
ConcurrentModificationException예외가 발생할 수 있어 복제 후 순회함
팔 생각이 없는 자판인 것 같다
class Solution {
public int[] solution(String[] keymap, String[] targets) {
Map<Character, Integer> keymapcnt = new HashMap<>();
// keymapcnt: 각 문자와 그 문자를 누르기 위한 최소 입력 횟수 저장. 키=문자, 값=최소 입력 횟수
for(int i = 0; i < keymap.length; i++) {
// keymap에 포함된 각 키 순회
String key = keymap[i];
for(int j = 0; j < key.length(); j++) {
// j: 키에서 문자의 위치(0부터~)
char c = key.charAt(j);
// keymapcnt에 입력횟수(위치+1)을 삽입.
// 최소 입력 횟수를 유지하기 위해 Math.min 사용, 현재 입력횟수와 비교 삽입
keymapcnt.put(c, Math.min(keymapcnt.getOrDefault(c, Integer.MAX_VALUE), j + 1));
}
}
int[] result = new int[targets.length];
for(int i=0; i < targets.length; i++) {
String targer = targets[i];
int pressCnt = 0;
for(char c: targer.toCharArray()) {
if(!keymapcnt.containsKey(c)) {
pressCnt = -1;
break;
}
pressCnt += keymapcnt.get(c);
}
result[i] = pressCnt;
}
return result;
}
}레디스 실습 중 찾아본 것들
GenericToStringSerializer<>(Integer.class)
이전 레디스 실습 때에는 설정 파일에서 키, 값에 대한 직렬화, 역직렬화를 이렇게 설정했었다.
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, ItemDto> itemRedisTemplate(
RedisConnectionFactory connectionFactory
) {
RedisTemplate<String, ItemDto> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory); // yml에 설정한 내용을 바탕으로 redis와 연결
template.setKeySerializer(RedisSerializer.string()); // key는 어떻게 직렬화/역직렬화 할 것인가(String을 문자열 타입으로)
template.setValueSerializer(RedisSerializer.json()); // value는 json 타입으로 직렬화할 것
return template;
}
}
현재 목표는 article에 대한 조회수를 저장하고, 카운트를 늘리는 메서드를 작성하는 것이다.
이에 따른 RedisTemplate 설정은 다음과 같다.
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Integer> articleTemplate(
RedisConnectionFactory redisConnectionFactory
) {
RedisTemplate<String, Integer> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
template.setKeySerializer(RedisSerializer.string());
template.setValueSerializer(new GenericToStringSerializer<>(Integer.class));
return template;
}
}value의 설정에 있어서 RedisSerializer.string()과 GenericToStringSerializer<>(Integer.class)는 무슨 차이일까?
1. RedisSerializer.string()
목적
- Redis의 key를 직렬화/역직렬화 하기 위해 사용
- Redis는 키를 문자열(String)로 저장하므로, 대부분의 경우 기본적으로 키는 문자열로 직렬화됨
구현
- Spring Data Redis에서 제공하는
RedisSerializer.string()메서드는StringRedisSerializer를 반환 - String 데이터를 URF-8 인코딩된 바이트 배열로 반환하고, 역직렬화 시 다시 문자열로 반환
- 키는 항상 문자열로 저장되기 때문에 특별한 변환이 필요치 않음
2. GenericToStringSerializer<>(Integer.class)
목적
- Redis의 value를 직렬화/역직렬화 하기 위해 사용
- Redis는 값도 기본적으로 문자열로 저장되기 때문에 Intger 같은 숫자 데이터 타입은 문자열로 변환된 후 저장되어야 함
구현
GenericToStringSerializer<T>는 지정된 타입을 String으로 변환하고, 역직렬화 시 문자열을 다시 해당 타입으로 변환함GenericToStringSerializer<>(Integer.class)는 Integer 값을 문자열로 직렬화하여 Redis에 저장하고, Redis에서 읽을 때 다시 Integer로 직렬화함
Spring의 기본 직렬화기와의 차이
- Spring의 기본값으로
JdkSerializationRedisSerializer를 사용할 경우 객체 직렬화/역직렬화 과정에서 별도의 클래스 정보가 포함되어 Redis에 불필요한 데이터를 추가로 저장하게 됨 GenericToStringSerializer는 간단히 문자열로만 변환하기 때문에 비교적 효율적임
key를 Long이나 다른 타입으로 지정했을 때도 이 방법을 사용하면 될 것 같다.
Redis
Http Session과 Session Clustering
Http Session
웹 애플리케이션에서 사용자 상태와 데이터를 유지하기 위해 사용하는 매커니즘
기본적으로 stateless 프로토콜이기에 각 요청은 독립적으로 처리됨
이를 극복하기 위해 세션을 사용하여 사용자 정보를 서버에 저장하고, 이후 요청에서도 정보를 유지할 수 있음
특징
- 세션 생성
- 클라이언트가 웹 서버에 처음으로 요청하면, 서버는 고유한 세션 ID를 생성
- 세션 ID는 일반적으로 쿠키를 통해 클라이언트에 전달됨
- 데이터 저장
- 서버는 세션 ID와 연결된 데이터를 메모리, 파일 또는 데이터베이스에 저장
- 세션 유효 기간
- 세션은 일정 기간 동안 유지되며, 이 기간 동안 클라이언트는 요청 상태를 저장함
- 유효 기간이 지나면 세션이 만료됨
- 세션 관리
- 클라이언트가 요청 시 세션 ID를 전달하면 서버는 이를 통해 적절한 데이터를 식별함
Session Clustering
웹 애플리케이션이 다중 서버 환경에서 세션 상태를 공유하도록 구성하는 기술
다중 서버 환경에서는 특정 사용자의 요청이 여러 서버에 분산(로드밸런싱 사용 등)되기 때문에 세션 데이터를 공유하는 매커니즘이 필요하다
특징
- 목적
- 고가용성(High Availability): 서버 장애 시에도 세션 데이터를 다른 서버에서 사용할 수 있도록 함
- 확장성(Scalability): 서버를 추가하거나 제거해도 세션 상태를 유지할 수 있음
- 구현 방식
- In-Memory Relication
- 모든 서버가 세션 데이터를 메모리에 복제하여 동기화
- 장점: 빠르다! (데이터 접근이)
- 단점: 서버 수가 많아지면 복제 오버헤드 증가
- Centralized Storage
- 세션 데이터를 별도의 중앙 저장소(Redis, Memcached, DB etc)에 저장
- 장점: 서버 간 동기화 필요 없음
- 단점: 중앙 저장소의 성능이 병목이 될 가능성도 있음
- Sticky Session
- 로드 밸런서가 동일 사용자 요청은 항상 동일한 서버로 전달함
- 장점: 구현 간단, 복제 필요 없음
- 단점: 특정 서버에 과부하 생일 가능성 증가
- In-Memory Relication
- 구현
- Redis: 중앙 집중형 세션 저장소로 자주 사용됨
- Spring Session: Redis와 연동하여 세션 데이터를 관리하는 Spring 모듈
- Tomcat Clustering: Apache Tomcat에서 제공하는 세션 복제 기능
Session 정보 공유하기
- 같은 프로젝트를 8080, 8081 포트로 실행
- 8080(or 8081) 포트로 요청을 보내서 값을 설정하고, 조회 요청 시 반환 체크
@GetMapping("/set")
public String set(
@RequestParam("q") String q,
HttpSession session
) {
session.setAttribute("q", q);
return "Saved : " + q;
}
@GetMapping("/get")
public String get(
HttpSession session
) {
return session.getAttribute("q").toString();
}- 세션 클러스터링 이전엔 한쪽 포트에서 설정한 값이 다른 포트로 요청 시 반환되지 않음
- Spring Session과 Redis 사용
- 의존성 추가
implementation 'org.springframework.session:spring-session-data-redis'- 재실행 후 확인
- 한쪽 포트에서 설정한 q의 값이 다른 포트에서도 정상 조회 가능함
- Redis 확인 시
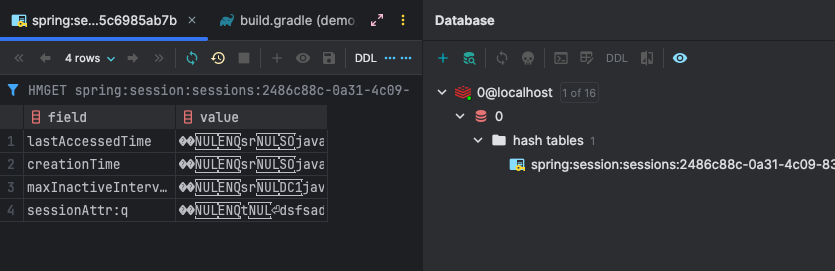
이렇게 세션 값이 추가되어 있음을 확인할 수 있었다
Sorted Set (ZSET)
- 고유한 값(Member)과 그에 매핑되는 점수(Score)를 저장하는 데이터 구조
- 점수에 따라 값들을 자동 정렬하며, 특정 범위의 데이터 조회나 순위 계산 등의 작업을 효율적으로 수행할 수 있음
특징
- 고유성
- 각 값(Member)은 고유함
- 중복된 멤버를 추가할 경우 기존 멤버의 점수만 업데이트 됨
- 점수(Score)
- 64비트 부동소수점(double) 값으로 저장됨
- 점수를 기준으로 멤버들이 자동 정렬 됨
- 자동 정렬
- 점수의 오름차순으로 멤버들이 정렬됨
- 내림차순 정렬은 명령어를 통해 처리할 수 있음
- 빠른 조회
- 멤버 추가, 점수 업데이터, 범위 조회 등이 O(log(N))의 시간 복잡도로 수행됨
- 범위 연산 지원
- 점수나 순위 범위를 기반으로 데이터를 조회하거나 조작할 수 있음
주요 명령어
ZADD key score member: 특정 멤버와 점수를 추가하거나 업데이트 함ZRANGE key start stop WITHSCORES: 순위 범위(start-stop) 내의 플레이어와 점수를 가져옴ZREVRANGE key start stop WITHSCORES: 순위 범위 내의 플레이어와 점수를 가져옴(내림차순)ZRANK key member: 특정 플레이어의 현재 순위를 가져옴(0부터 시작, 오름차순)ZREVRANK key member: 특정 플레이어의 현재 순위를 가져옴(0부터 시작, 내림차순)ZREM key member: 특정 플레이어를 리더보드에서 제거함
장점
- 빠른 성능
- 자동 정렬
- 유연한 범위 조회
ZSET으로 리더보드 구현하기
상품에 대한 주문(구매)이 이루어질 경우 스코어를 더해 주문이 많은 상품 순으로 보여주는 리더보드 구현
- 간단한 템플릿 설정
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, ItemDto> rankTemplate(
RedisConnectionFactory redisConnectionFactory
) {
RedisTemplate<String, ItemDto> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
template.setKeySerializer(RedisSerializer.string());
template.setValueSerializer(RedisSerializer.json());
return template;
}
}- 위와 같이 만들어진 설정을 다음과 같이 받아서 사용
private final ZSetOperations<String, ItemDto> rankOps;
public ItemService(
RedisTemplate<String, ItemDto> rankTemplate
) {
this.rankOps = rankTemplate.opsForZSet();
}+ rankTemplate와 rankOps 간의 관계
rankTemplate은 RedisTemplate<String, ItemDto> 객체를 반환 -> 이를 통해 Redis와 통신
rankOps는 rankTemplate.opsForZSet() 메서드를 통해 Sorted Set(ZSET) 관련 작업을 수행하는 도우미 객체(ZSetOperations<String, ItemDto>)를 얻음
RedisTemplate의 구조
RedisTemplate는 다양한 Redis 데이터 구조와 상호작용 할 수 있도록 여러 작업을 제공하는 메서드를 가지고 있음
opsForValue(): Redis의 String 값을 다룰 때 사용opsForHash(): Redis의 Hash 값을 다룰 때 사용opsForSet(): Redis의 Set 값을 다룰 때 사용opsForZSet(): Redis의 Sorted Set(ZSET) 값을 다룰 때 사용
RedisTemplate은 제네릭 타입으로 정의된 RedisSerializer를 활용하여 데이터 직렬화/역직렬화를 자동으로 처리
-> RedisTemplate<String, ItemDto>에서 opsForZSet()을 호출하면 ZSetOperations<String, ItemDto>가 반환됨
- 구매 시 해당 객체의 스코어를 올리는 로직 추가
// service-상품 구매 메서드
rankOps.incrementScore("soldRanks", ItemDto.fromEntity(item), 1);- 랭킹 조회
public List<ItemDto> getMostSold() {
// 0번째부터 9번째까지(10개) 출력
Set<ItemDto> ranks = rankOps.reverseRange("soldRanks", 0, 9);
if (ranks == null) return Collections.emptyList();
return ranks.stream().toList();
}Caching
반복적으로 사용하는 데이터나 연산 결과를 임시 저장소(Cache)에 저장하여, 이후 요청 시 더 빠르게 데이터를 제공하는 기술
속도가 빠른 메모리(RAM 등)를 사용해 데이터 접근 시간을 단축하고, 시스템의 성능과 효율성을 높임
기본 개념
목적
- 데이터 요청 처리 속도를 높이고
- 데이터베이스나 외부 API 호출 등 비용이 큰 작업의 부담을 줄이기 위함
동작 원리
- 데이터를 처음 요청할 때 원본 데이터 소스(데이터베이스, API 등)에서 가져와 캐시에 저장
- 이후 동일 요청 시 캐시에 저장된 데이터 반환
주요 구성 요소
-
캐시 저장소(Cache Store)
- 데이터를 저장하는 공간
- 메모리(RAM) 기반 시스템이 일반적
- 예: Redis, Memcached, Ehcache.
-
키(Key)와 값(Value)
- 캐시는 키-값(key-value) 구조로 데이터를 저장
- 키는 고유함, 값을 통해 데이터를 검색한다
-
TTL (Time-To-Live)
- 캐시 데이터의 유효 기간
- TTL이 지나면 캐시 데이터는 만료되어 삭제됨
- TTL 설정을 통해 오래된 데이터를 자동으로 갱신하거나 제거할 수 있음
-
정책(Cache Policy)
- Write-Through: 데이터를 캐시와 데이터베이스에 동시에 저장
- Write-Behind: 데이터를 캐시에 저장하고, 일정 시간이 지나면 데이터베이스에 저장
- Read-Through: 캐시가 데이터를 가지고 있지 않으면 원본 데이터 소스에서 가져와 저장 후 반환
장점
- 성능 향상: 데이터를 캐시에서 바로 제공하여 응답 속도를 높임
- 부하 감소: 데이터베이스, 외부 API 호출 등의 비용을 줄임
- 확장성 향상: 대량의 요청을 처리하는 시스템에서 병목 현상을 줄임
종류
- 클라이언트 캐싱
- 웹 브라우저나 모바일 앱에서 데이터를 캐싱
- 예: 브라우저의 HTTP 캐시
- 애플리케이션 캐싱
- 애플리케이션 내부에서 데이터를 캐싱
- 예: JVM 내에서 사용하는 Ehcache, Guava Cache
- 분산 캐싱
- 여러 서버가 공유하는 분산 캐시 시스템
- 예: Redis, Memcached
기본 용어
- Cache Hit: 캐시에 접근했을 때 찾고 있는 데이터가 있는 경우
- Cache Miss: 캐시에 접근했을 때 찾고 있는 데이터가 없을 경우
- Eviction Policy: 캐시에 공간이 부족할 때 어떻게 공간을 확보할 지
- Caching Strategy: 언제 캐시에 데이터를 저장하고, 언제 캐시를 확인하는 지
주요 전략
| 전략 이름 | 동작 방식 | 장점 | 단점 | 사용 사례 |
|---|---|---|---|---|
| Write-Through | 캐시와 데이터 소스(DB)에 동시에 데이터 저장 | - 데이터 일관성 보장 - 읽기 요청 시 캐시에서 바로 제공 | - 쓰기 성능 저하 - 쓰기 작업이 많을 경우 비효율적 | - 자주 업데이트되는 데이터 - 실시간 일관성이 중요한 경우 |
| Write-Behind | 캐시에만 먼저 저장하고, 비동기로 DB에 반영 | - 쓰기 성능 향상 - 캐시 중심 접근 가능 | - 캐시와 DB 간 데이터 불일치 가능 - 장애 시 데이터 손실 | - 로그 기록 - 비동기적 데이터 동기화 |
| Read-Through | 읽기 요청 시 캐시 먼저 조회, 없으면 DB에서 가져와 캐시에 저장 | - 캐시 적중률 증가 - 일관된 데이터 접근 방식 | - 초기 요청 시 지연 발생 | - 정적 데이터 조회 - 자주 조회되는 데이터 |
| Cache-Aside | 애플리케이션에서 직접 캐시를 관리, 캐시 미스 시 DB에서 가져와 저장 | - 구현이 간단 - 필요할 때만 캐시 갱신 | - 캐시와 DB의 데이터 일관성 보장 어려움 | - 사용자 프로필 조회 - 데이터 조회 빈도가 다양한 경우 |
| Refresh-Ahead | 데이터 만료 전에 미리 갱신 | - 캐시 미스 감소 - 최신 데이터 유지 | - 예측 실패 시 불필요한 갱신 - 리소스 낭비 가능 | - 대규모 리더보드 - 실시간 데이터 갱신이 필요한 시스템 |
| Time-To-Live | 일정 시간이 지나면 캐시 데이터 만료 | - 오래된 데이터 자동 제거 - 리소스 절약 | - 유효 시간 내 데이터 변경 시 문제 발생 | - 정적 콘텐츠 - 제한된 유효 기간의 데이터 |
| Least Recently Used (LRU) | 가장 최근에 사용되지 않은 데이터를 제거 | - 자주 사용되는 데이터 유지 | - 오래된 데이터 제거가 항상 최적은 아님 | - 메모리 제한이 있는 시스템 - 자주 조회되는 데이터 |
| Least Frequently Used (LFU) | 사용 빈도가 낮은 데이터를 제거 | - 자주 사용하는 데이터 우선 유지 | - 초기 데이터가 제거 우선순위에 포함될 수 있음 | - 대규모 데이터 캐싱 - 접근 패턴이 명확한 경우 |
| Explicit Invalidation | 특정 조건에서 캐시 데이터를 명시적으로 무효화 | - 애플리케이션이 캐시 갱신을 완전히 제어 | - 구현 복잡도 증가 - 조건 관리 어려움 | - 데이터 업데이트 이벤트 발생 시 - 사용자가 설정 변경 |
Springboot에서 캐싱 적용해보기
spring에서 제공하는 캐싱 이용
-
의존성
dependencies { implementation 'org.springframework.boot:spring-boot-starter-data-jpa' implementation 'org.springframework.boot:spring-boot-starter-data-redis' implementation 'org.springframework.boot:spring-boot-starter-web' compileOnly 'org.projectlombok:lombok' runtimeOnly 'com.h2database:h2' annotationProcessor 'org.projectlombok:lombok' testImplementation 'org.springframework.boot:spring-boot-starter-test' testRuntimeOnly 'org.junit.platform:junit-platform-launcher' } -
캐싱 설정
@Configuration @EnableCaching // 캐싱 활성화 public class CacheConfig { @Bean public RedisCacheManager chcheManager( RedisConnectionFactory connectionFactory // 레디스 연결정보 이용 ) { // 설정 구성 // RedisCacheConfiguration: Redis를 이용해서 spring cache를 사용할 때 Redis 관련 설정을 모아두는 클래스 RedisCacheConfiguration configuration = RedisCacheConfiguration .defaultCacheConfig() // 기본 설정 가져옴 .disableCachingNullValues() // null 캐싱 여부 .entryTtl(Duration.ofSeconds(10)) // 캐시 유지 시간 설정 .computePrefixWith(CacheKeyPrefix.simple()) // 캐시 구분 접두사 설정(simpe:기본설정) // 캐시에 저장할 값을 직렬화/역직렬화할 방법 .serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(RedisSerializer.json())); return RedisCacheManager.builder(connectionFactory) .cacheDefaults(configuration) .build(); } } -
캐싱 적용
// service // 해당 메서드의 결과를 캐싱함 // cacheNames: 해당 메서드로 만들어질 캐시의 이름 // key: 캐시 데이터를 구분하기 위해 활용하는 값-인자의 첫번째를 활용 @Cacheable(cacheNames = "itemCache", key="args[0]") public ItemDto readOne(Long id) { return itemRepository.findById(id) .map(ItemDto::fromEntity) .orElseThrow(() -> new ResponseStatusException(HttpStatus.NOT_FOUND)); } -
조회 테스트
위의 메서드를 호출하면 Redis에 이렇게 캐싱 데이터가 추가된다
25ms 소요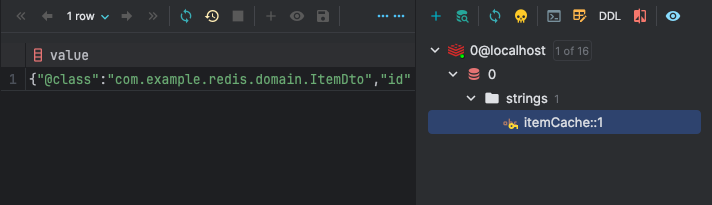
TTL을 10초로 지정했기 때문에 10초가 지나면 사라진다
10초가 지나기 전에 재호출하면 7ms가 소요되었다(좀 더 짧은 시간에 응답)
캐시가 만료되기 전에 조회하면 하이버네이트(데이터가 저장된 곳)의 조회 쿼리가 출력되지 않는다는 것에서 캐시히트가 이루어졌음을 알 수 있다 -
다른 메서드에도 적용해봄
@Cacheable(cacheNames = "itemAllCache", key="methodName")
public List<ItemDto> readAll() {
return itemRepository.findAll()
.stream()
.map(ItemDto::fromEntity)
.toList();
}아이템 전체 목록을 조회하는 메서드에도 적용했다
첫 조회는 정상적으로 이루어지나, 재조회시 에러가 발생했다
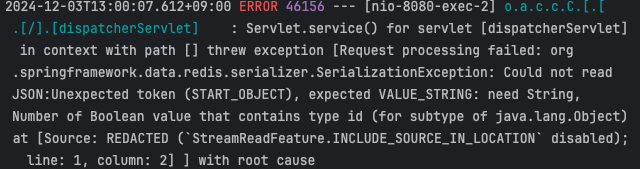
찾아보니
- redis에 저장된 데이터의 타입 정보가 없거나 잘못 저장되어서 역직렬화가 안 된 경우
- redis에 저장된 데이터 형식이 ItemDto가 아닌 다른 형식이거나 json 구조가 예상과 다르게 저장된 경우
- redis에 잘못된 데이터가 이미 저장되어 역직렬화 시 Jackson이 이를 처리하지 못한 경우
셋 중 하나인 것 같다
일단 마지막 경우는 flushall로 데이터를 날려 확인해보았지만 아닌 것으로 확인되었다
