구매자들에게 받은 상품문의를 자동으로 대답하기 위해서는 당연히 쿠팡에서 상품에 대한 정보를 받아와야 한다. 따라서 첫 스텝은 사용자가 상품판매 링크를 입력하면 페이지에서 상품에 대한 정보가 적혀있는 이미지와 택스처를 크롤링 해오는 코드를 짜보았다.
1. 크롤링 해올 정보 확인
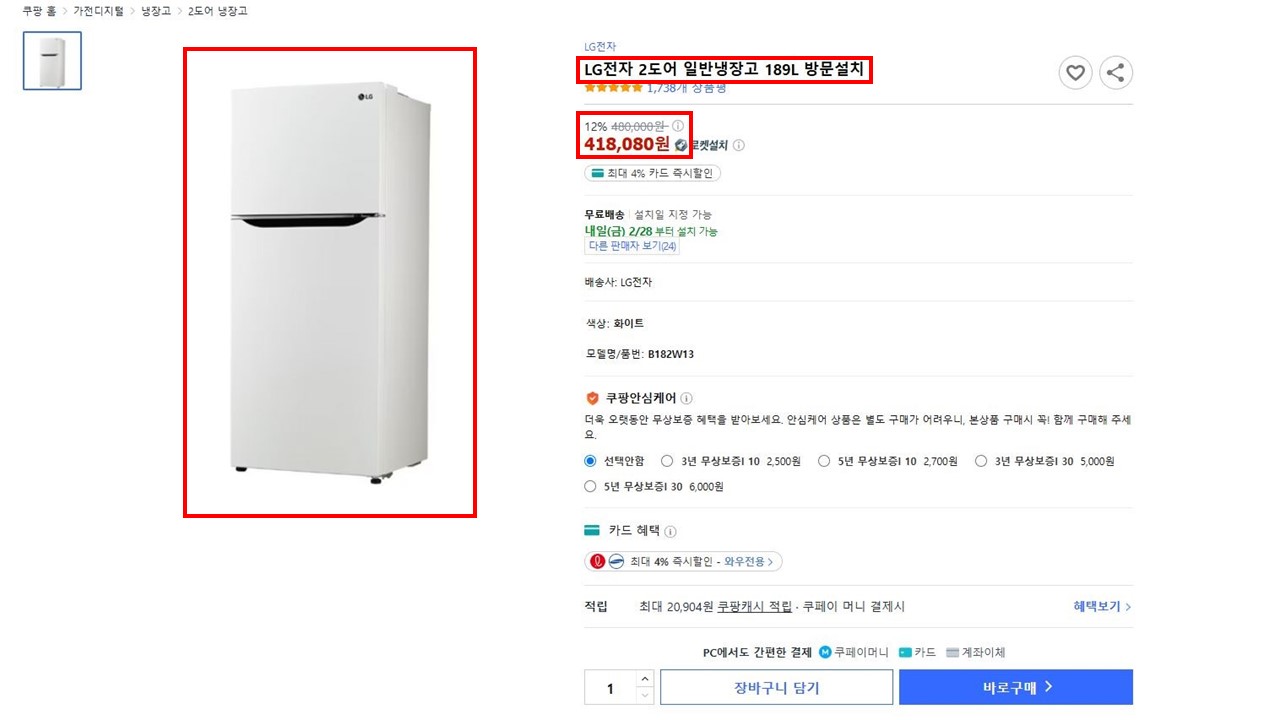
쿠팡의 기본적인 상품판매 페이지는 위 이미지처럼 되어있다.
이 페이지에서는 다음의 데이터를 크롤링 하려고 한다.
- 상품의 판매 이름
- 상품의 대표 이미지
- 상품의 가격 (원가와 할인가)
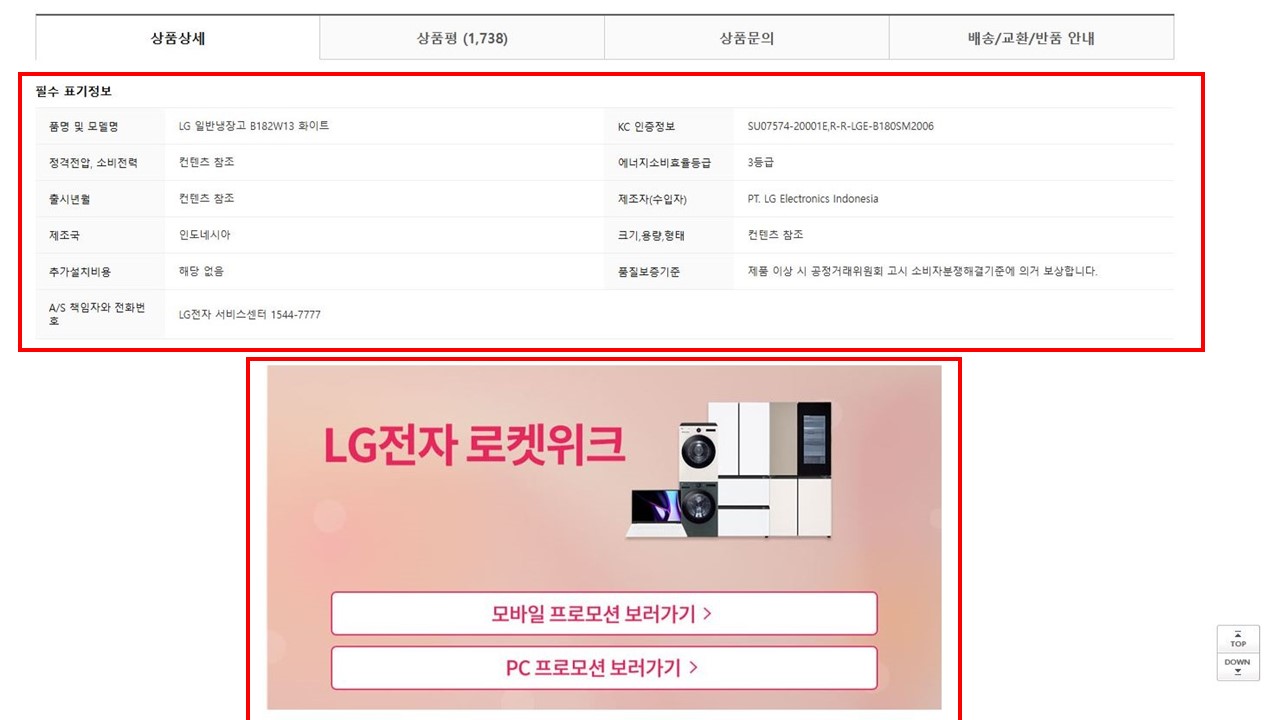
페이지를 내려보면 먼저 상품상세 페이지가 나온다. 상품에 대한 정보가 적힌 매우 중요한 데이터이다.
필수 표기정보가 적힌 표 데이터와 이미지 데이터를 크롤링 해올 것이다.
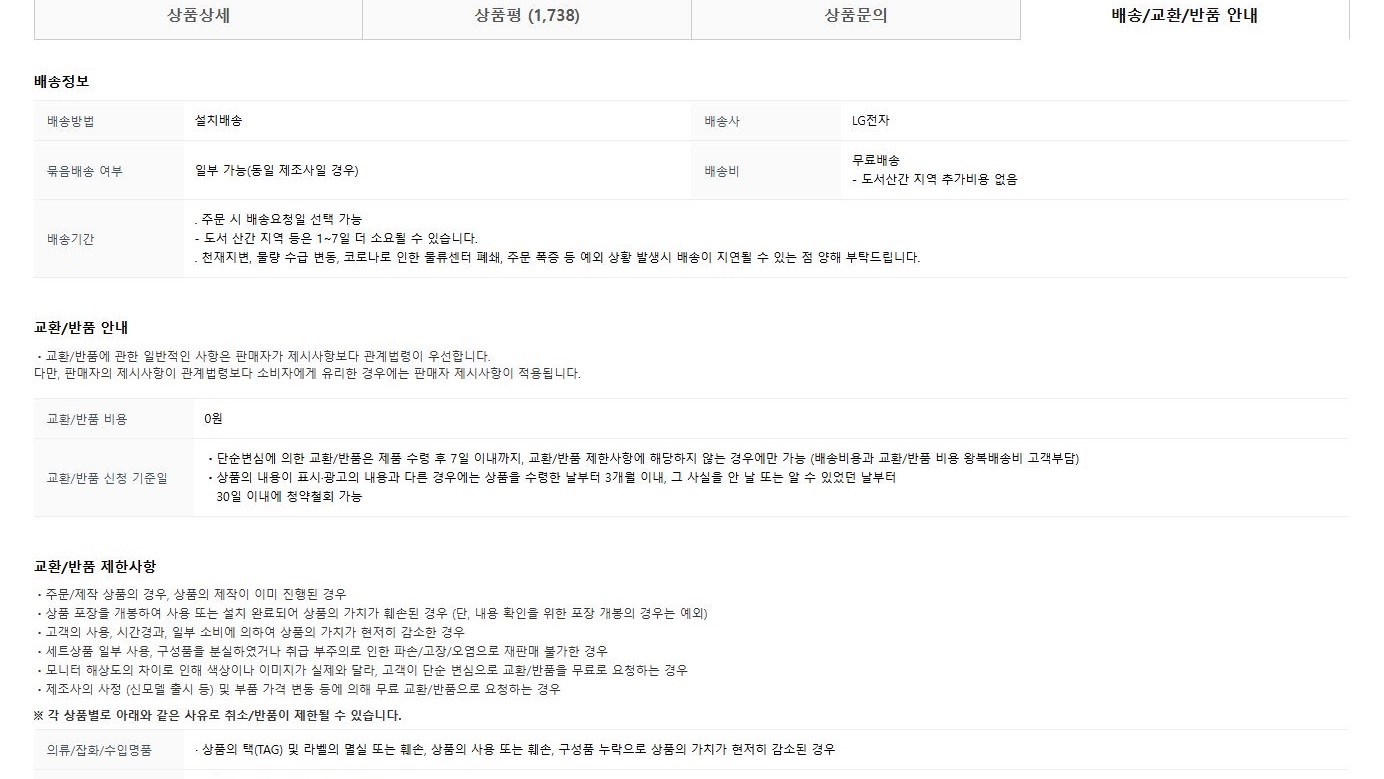
스크롤을 좀 더 내리면 상품평, 상품문의, 배송/교환/반품 안내가 나온다. 상품평은 이 프로젝트 말고 '쇼핑몰 상담 챗봇' 프로젝트때 사용할 예정이다. 상품문의 같은 경우는 이 프로젝트가 자동으로 하고자 하는 목표이기 때문에 가져오지 않았다. 배송/교환/반품 안내는 충분히 구매자가 질문을 할수 있는 부분이기 때문에 가져와야 한다.
2. 코드 구현
2-1. Playwright를 사용해 HTML 가져오기
Playwright는 마이크로소프트에서 개발한 웹 자동화 프레임워크로, 브라우저를 프로그래밍 방식으로 제어할 수 있는 도구이다. Selenium과 비슷하지만, 더 빠르고 강력한 기능을 제공하는 것이 특징이다.
쿠팡같은 대기업은 자동크롤링을 막기 위해 여러가지 방화벽을 쳐놓아 단순한 코드로 몇번 크롤링을 하면 바로 ip차단을 해버리는 것을 확인했다.
def get_html(url):
"""Playwright를 사용해 HTML을 가져오는 함수"""
with sync_playwright() as p:
browser = p.chromium.launch(headless=False, args=["--no-sandbox", "--disable-gpu"]) # 브라우저 보이게 실행 (디버깅 가능)
context = browser.new_context()
page = context.new_page()
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36"
}
page.set_extra_http_headers(headers)
# ✅ 랜덤한 대기 시간 추가 (1.5 ~ 5초)
# time.sleep(random.uniform(1.5, 5.0))
try:
# 페이지 이동 (HTML만 로드되면 가져오기)
page.goto(url, timeout=60000, wait_until="load")
if page.wait_for_selector("div.subType-IMAGE img, div.subType-TEXT img", timeout=20000):
# ✅ JavaScript 실행 후 동적으로 생성된 HTML 가져오기
html = page.evaluate("document.documentElement.outerHTML")
browser.close()
return html, True
else:
browser.close()
return None, False
except Exception as e:
print(f"❌ 오류 발생: {e}")
browser.close()
return None, False이 함수는 subType-IMAGE img, subType-TEXT img 클래스, 즉 상품상세설명 이미지 데이터를 찾을 때까지 대기하다가 찾게 된다면 HTML가 True를 반환하는 함수이다. 단순한 코드이므로 쿠팡으로부터 ip차단을 주의해야한다.
2-2. 이미지 가져오기 & 다운로드
def extract_filtered_images(html):
"""HTML에서 특정 클래스 내부의 이미지 URL만 추출"""
soup = BeautifulSoup(html, "html.parser")
# 'subType-IMAGE','subType-TEXT' 찾기
image_containers = soup.select("div.subType-IMAGE, div.subType-TEXT")
image_urls = []
# 🔹 가져올 이미지 확장자 목록 (대소문자 구분 없이 처리)
valid_extensions = {"jpg", "jpeg", "png", "gif", "bmp", "webp", "svg", "tiff"}
for container in image_containers:
# 해당 div 내의 모든 img 태그 찾기
img_tags = container.find_all("img")
for img in img_tags:
img_url = img.get("src") or img.get("data-src") # src가 없으면 data-src 체크
if img_url:
# 🔹 URL에서 확장자를 소문자로 변환하여 필터링
ext = img_url.split(".")[-1].split("?")[0].lower()
if ext in valid_extensions:
# 상대 URL이면 절대 URL로 변환
if img_url.startswith("//"):
img_url = "https:" + img_url
image_urls.append(img_url)
return image_urls
def download_images(image_urls):
"""여러 개의 이미지 다운로드 후 저장"""
for i, img_url in enumerate(image_urls, 1):
# 저장 경로 설정 (이미지 확장자 유지)
ext = img_url.split(".")[-1].split("?")[0] # 확장자 추출 (jpg, png 등, URL에 ? 붙어 있는 경우 제거)
if ext.lower() not in ["jpg", "jpeg", "png"]: # 확장자가 이상하면 기본 jpg 사용
ext = "jpg"
save_path = os.path.join(save_folder, f"image_{i}.{ext}")
try:
# 이미지 다운로드
response = requests.get(img_url, stream=True)
if response.status_code == 200:
image = Image.open(BytesIO(response.content))
# ✅ RGBA 또는 P 모드 이미지는 RGB로 변환 후 저장
if image.mode in ("RGBA", "P"):
image = image.convert("RGB")
image.save(save_path) # 변환된 이미지 저장
print(f"✅ {i}. 이미지 저장 완료: {save_path}")
else:
print(f"❌ {i}. 이미지 저장 실패: {img_url}")
except Exception as e:
print(f"❌ {i}. 오류 발생: {e}")2-3. 상품 판매 이름, 대표 이미지 가져오기
def product_image_and_name_download(html):
soup = BeautifulSoup(html, "html.parser")
img_tag = soup.find("img", class_="prod-image__detail")
if img_tag:
img_url = "https:" + img_tag["src"] # src 값이 //로 시작하므로 https:를 붙여야 함
img_response = requests.get(img_url)
if img_response.status_code == 200:
# 폴더가 존재하지 않으면 생성
if not os.path.exists(main_image_folder):
os.makedirs(main_image_folder)
image_path = os.path.join(main_image_folder, "main_image.jpg")
with open(image_path, "wb") as f:
f.write(img_response.content)
print("이미지 저장 완료: main_image.jpg")
else:
print("이미지 다운로드 실패")
else:
print("이미지를 찾을 수 없음")
name = soup.find("h1", class_="prod-buy-header__title").text.strip()
name_path = os.path.join(main_image_folder, "product_name.txt")
if name:
with open(name_path, "w", encoding="utf-8") as file:
file.write(name)
price_div = soup.find("div", class_="prod-price-onetime")
if price_div:
price_html = price_div.prettify() # HTML을 보기 좋게 정리
price_html = re.sub(r'\n\s*\n+', '\n', price_html) # 여러 개의 연속된 줄바꿈을 하나로 줄이기
price_html = re.sub(r'>\s+<', '><', price_html) # 태그 사이의 불필요한 공백 제거
price_path = os.path.join(html_folder, "price_info.html")
with open(price_path, "w", encoding="utf-8") as file:
file.write(price_html)2-4. 필수 표기정보, 배송/교환/반품 안내 가져오기
def basic_information(html):
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table", class_="prod-delivery-return-policy-table essential-info-table")
if table:
if not os.path.exists(html_folder):
os.makedirs(html_folder)
file_path = os.path.join(html_folder, "basic_data.html")
# 테이블 HTML 저장
with open(file_path, "w", encoding="utf-8") as f:
f.write(str(table))
print(f"테이블 HTML 저장 완료: {file_path}")
else:
print("테이블을 찾을 수 없음")
def delibery_data(html):
soup = BeautifulSoup(html, "html.parser")
li_element = soup.find_all("li", class_="product-etc tab-contents__content etc-new-style")
if li_element:
file_path = os.path.join(html_folder, "li_data.html")
# 모든 <li> 태그를 하나의 HTML 파일에 저장
with open(file_path, "w", encoding="utf-8") as f:
for li in li_element:
f.write(str(li) + "\n") # HTML 그대로 저장 + 줄바꿈 추가
print(f"<li> HTML 저장 완료: {file_path}")
else:
print("<li> 태그를 찾을 수 없음")3. 결과
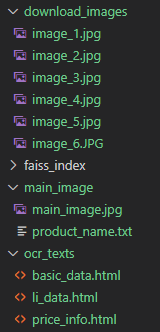 각각의 함수를 실행하는 코드를 작성하여 실행하면 결과는 사진처럼
각각의 함수를 실행하는 코드를 작성하여 실행하면 결과는 사진처럼 * download_images 폴더에는 상품상세정보 이미지가 저장되고,
* main_image 폴더에는 대표사진과 상품 판매 이름이 저장되고,
* ocr_texts 폴더에는 가격정보, 필수 표기정보, 배송/교환/반품 안내 정보가 html로 저장된다.
추후에 ocr_texts 폴더는 이미지를 ocr한 데이터가 추가로 저장될 예정이다.
