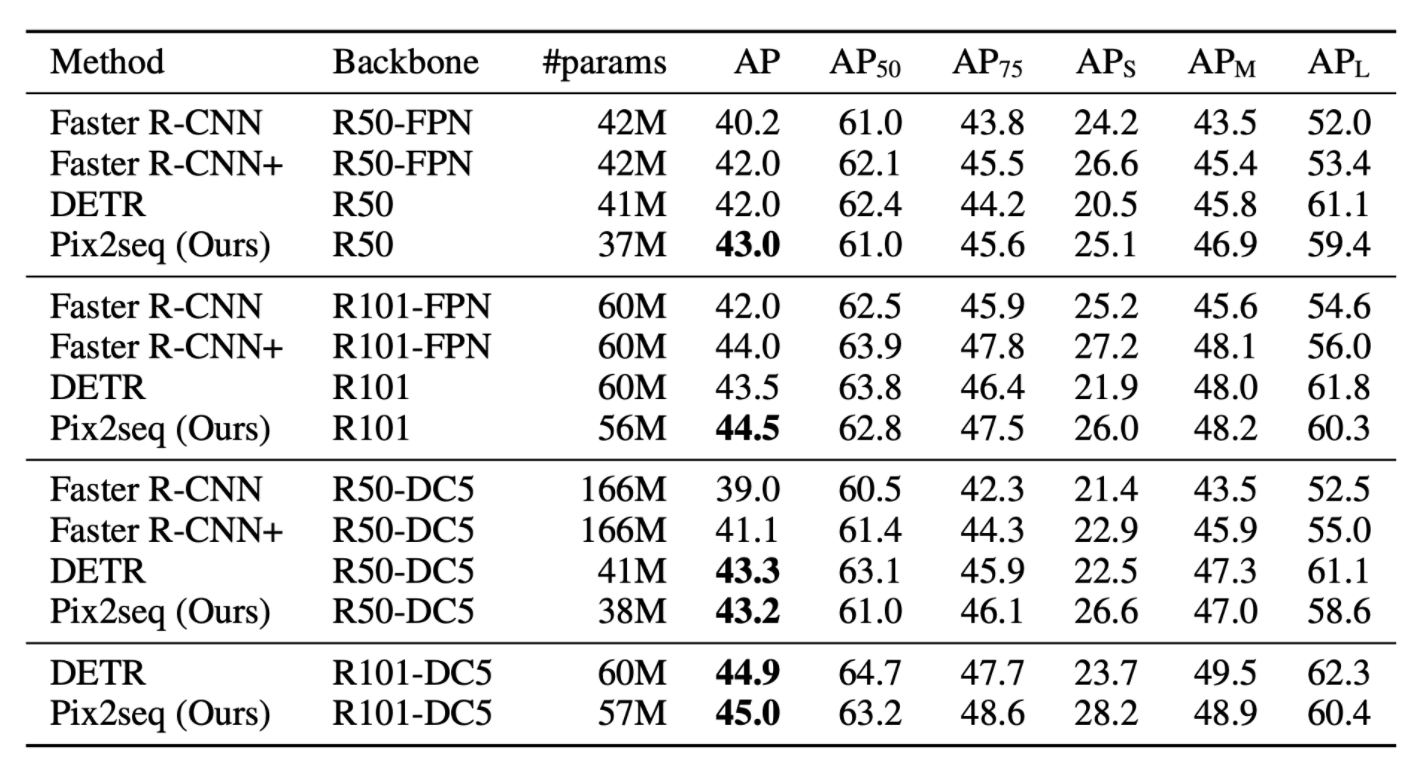
Pix2seq: A Language Modeling Framework for Object Detection, 2021
https://arxiv.org/pdf/2109.10852.pdf
한줄평
그 복잡한 object detection을 언어문제처럼 진짜 간단한 아키텍쳐로 풀다니 놀라움...recall을 높이려고(eos토큰이 늦게 나오도록) 시도한 sequence augmentation 방법이 되는게 신기함..
Abstract
object detection을 위한 간단하고 generic한 프레임워크인 Pix2Seq을 제안한다. 기존의 접근법들은 명시적으로 사전지식을 넣은 것과 다르게 우리는 object detection 문제를 pixel input이 주어졌을 때 language modeling 문제로 바꾸었다. Object에 대한 설명(e.g. 바운딩박스, 분류 레이블)은 토큰 시퀀스로 이루어져있고 모델을 이미지를 이해한 뒤 원하는 시퀀스를 뽑도록 학습시킬 것이다. 우리의 직관은 뉴럴네트워크가 어디에 무엇이 있는지 안다면 우리는 그걸 읽을 수 있게만 가르치면 된다는 것이었다. task-specific 데이터 어그멘테이션에서 우리의 접근은 태스크에 대한 최소한의 가정만 만들지만 COCO 데이터셋에서 최적화되고 잘 디자인된 object detection에 필적할만한 성능을 냈다.
Introduction
Object detection은 미리 정의된 이미지의 카테고리에서 이미지의 객체(object)를 찾아내고 위치를 찾는 태스크이다. 보통 탐지된 객체 bounding box와 클래스 레이블로 설명된다. 이 태스크가 어렵기 때문에, 기존방법론들은 많은 양의 사전지식과 loss function에 대한 설계를 하였다.
이 논문은 새로운 방법론인 Pix2Seq을 제안한다. 이 모델은 object를 설명하는 방법을 학습하면서, 픽셀에 따른 언어를 ground할 수 있는걸 배운다. 즉, 우리는 object detection 문제를 pixel input이 주어졌을 때 language modeling 문제로 바꾸었고, 모델 아키텍쳐와 로스가 generic하며 상대적으로 쉽다. 그러므로 우리는 쉽게 이 프레임워크를 다른 도메인이나 application으로 바꿀 수 있고, 이미지 태스크에 언어 인터페이스를 제공함으로서 general한 지식을 돕는 인지시스템으로 결합시킬 수 있다.
Pix2Seq을 하기 위해 바운딩박스와 클래스 레이블을 토큰 시퀀스로 바꾸는 quantization, serialization 방법을 제안할 것이다. 그리고 encoder-decoder 구조를 사용하여 픽셀 인풋을 받고 target sequence를 생성할 것이다. 목표함수는 간단히 픽셀 인풋과 이전 토큰들이 주어졌을 때 새로운 토큰에 대한 maxium likelihood이다. 아키텍쳐와 손실함수가 task에 대해 사전지식을 담고 있지 않지만, 우리는 여전히 태스크 specific한 사전지식을 인풋과 아웃풋 둘다 학습 동안 바뀌는 sequecne augmentation 기법을 통해 넣을 수 있었다.
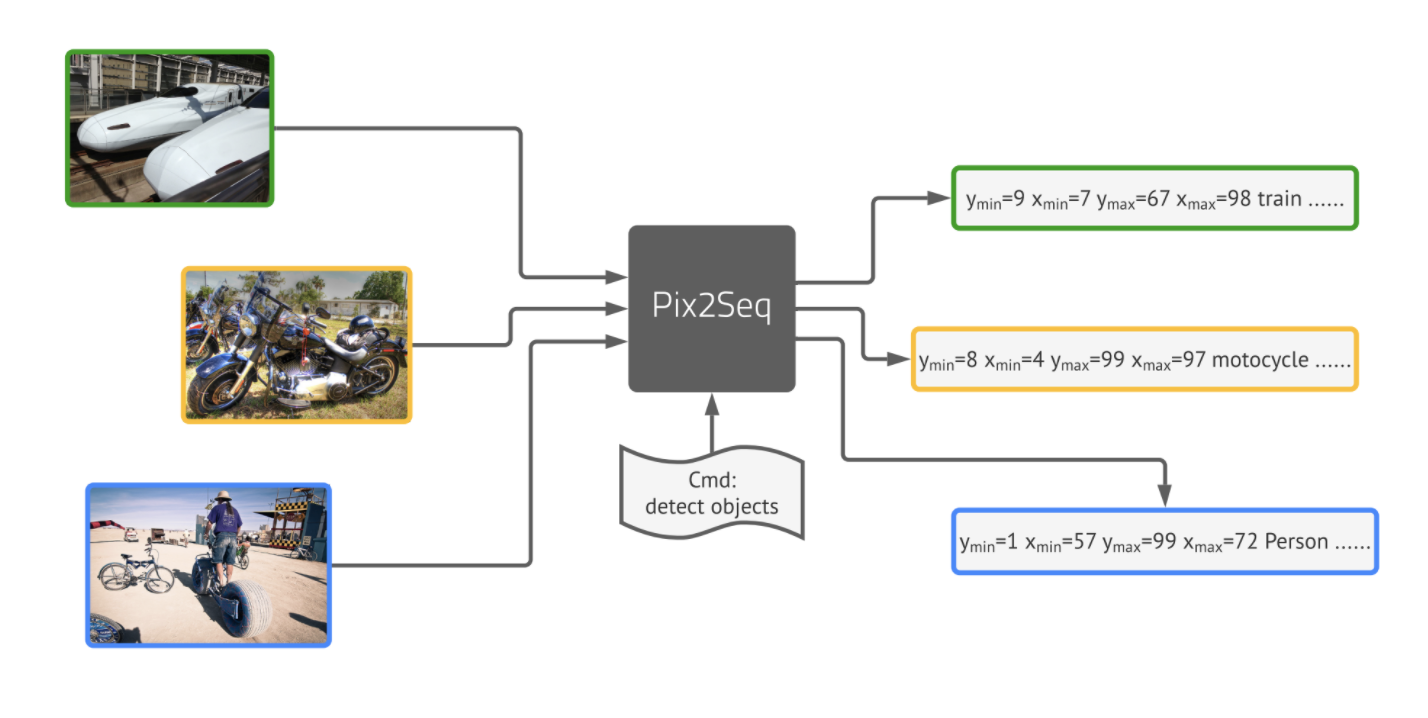
Pix2Seq Framework
Pix2Seq 아키텍쳐는 4가지의 주요 component로 구성되어 있다.
- Image Augmentation : 비전 태스크에서 많이 사용하듯 한정된 셋의 학습 데이터를 늘리기 위해 이미지 어그멘테이션 기법을 사용했다.(e.g. 랜덤 스케일링, crop)
- Sequence construction & augmentation : 이미지에 대한 object annotation은 바운딩박스와 분류 레이블로 주어지는데 이를 토큰 시퀀스로 바꾼다.
- Architecture : encoder-decoder 구조로 인코더가 픽셀 인풋을 받고 디코더가 타겟 시퀀스를 뽑는다.
- Objective/loss function : 모델은 이미지와 토큰이 주어졌을 때의 log-likelihood를 최대화 하도록 학습된다.
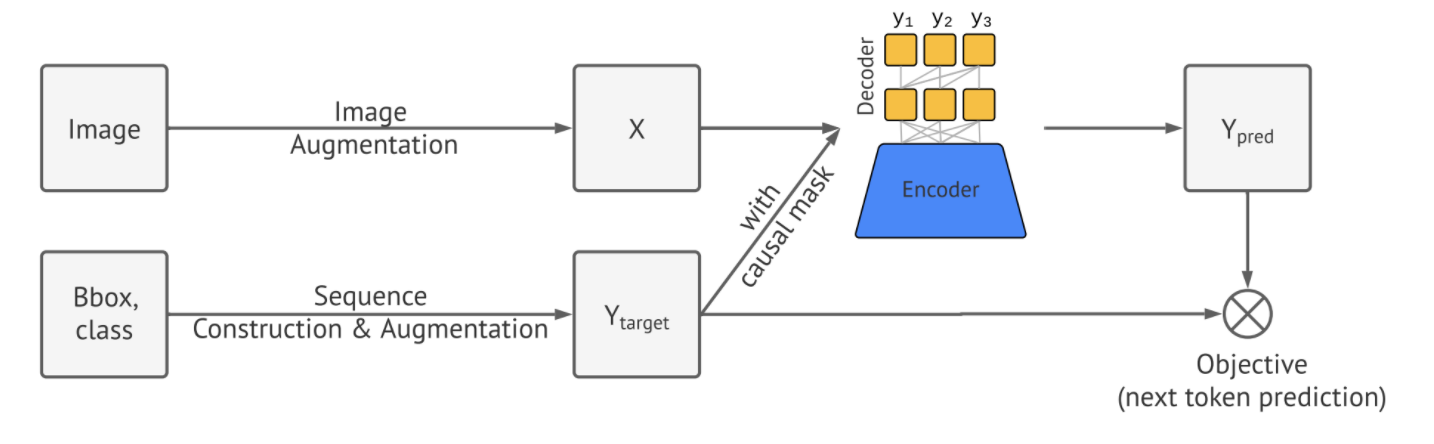
Sequence Construction from Object Detection
보통의 object detection 디텍션 데이터(COCO, Pascal VOC, OpenImages)에서 이미지는 다양한 개수의 object를 가지고 있고 바운딩박스와 분류 레이블로 구성되고, Pix2Seq는 이를 토큰 시퀀스로 바꾼다.
분류 레이블은 자연스럽게 토큰으로 표현되지만, 바운딩박스는 그렇지 않다. 바운딩박스는 두개의 coner porint(왼쪽위, 오른쪽 아래)로 구성되거나 중앙점에 높이와 넓이를 더하는 것으로 결정된다. 좌표를 구성하는 연속 숫자를 이산화하는 것을 제안한다. 구체적으로 object는 다섯개의 토큰()으로 표현되고 각각의 연속적인 좌표는 1과 사이의 숫자와 클래스로 바꾼다.
모든 토큰에 대해 공유하는 사전을 가지고 있고, 사전의 크기는 와 클래스의 개수의 합이 된다. 바운딩 박스에 대한 이런 quantization 방법은 작은 크기의 사전으로 높은 precision을 가질 수 있게 한다. 가령, 크기의 이미지는 600개의 bin을 가지면 quantization이 완벽하게 된다. 하지만 이는 보통 3만 2천 개 이상의 vocab을 가지는 언어 모델보다 훨씬 작은 크기이다.

짧은 토큰 시퀀스로 표현된 object description들을 얻었으니 이를 하나의 시퀀스로 serialize하는 단계가 필요하다. object의 순서는 detction task를 하는 데 필요가 없으니 random ordering 방식으로 했다. 다른 determinisitic한 ordering 방법론도 생각해보았지만, random ordering 방법만큼의 성능을 보일 것이라고 생각했다. 이는 뉴럴네크워크와 auto regressive한 방법론이 남아있는 object들이 무엇인지 학습할 수 있다고 생각했기 때문이다.
마지막으로 object의 개수들이 다르기 때문에, 생성된 시퀀스의 길이도 달랐고, 시퀀스의 끝을 나타내기 위해 마지막에 [EOS] 토큰을 추가하였다.
Architecture, Objective and Inference
- Architecture : 인코더-디코더 구조를 사용하였다. 인코더는 일반적인 이미지 인코더(e.g. ConvNet, Transformer, 혹은 두개의 combination)이다. 디코더는 트랜스포머 디코더를 사용하였다. 이미지와 이전 토큰이 주어졌을 때, 토큰을 하나에 하나 생성한다. 이는 최신 object detector에 복잡하고 커스텀되어있는 디코더에 비해 매우 간단하다.
- Objective : 언어모델과 비슷하게 토큰을 예측하는 방식으로 학습되고 loss는 maximum likelihood loss이다.
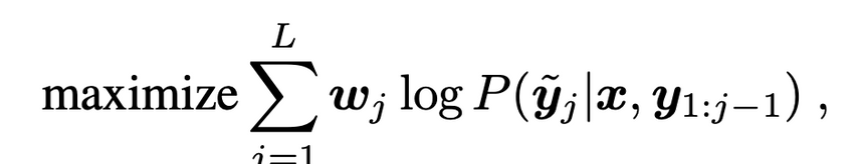
- 는 실험에서 다 1로 뒀지만 token의 종류(e.g. 좌표 vs 클래스 레이블)에 따라 다르게 가져갈 수 있다.
- Inference : inference 단계에서는 model likelihood에서 sample 토큰을 뽑았다. 이는 가장 큰 likelihood를 뽑는 방식이 될 수도 있고, stochastic한 sampling방법이 될 수도 있다. 우리는 nucleus sampling방법이 가장 높은 recall을 가진 것을 확인했다.
[EOS]토큰이 나오면 시퀀스가 끝났다. 시퀀스 생성이 끝나고 다시 이를 bounding box와 레이블로 바꾸는 방식은 아주 간단했다.- nucleus sampling : 확률을 내림차순으로 정렬해 놓고 누적 분포가 p 이상인 토큰까지 자른 뒤 거기서 샘플링하는 방식 https://velog.io/@nawnoes/Top-p-샘플링-aka.-Nucleus-Sampling
Sequence Augmentation to Integrate Task Prior
[EOS] 토큰이 나오면 generation을 멈추게 했지만, 실제로는 모델이 모든 object를 예측하지 않고 끝을 내는 경향이 있었다. 이는 1) 실제로 annotation에 몇 label이 annotate되지 않은 annotation noise일 수 있고 2) recognize하고 localize 하는데에서의 uncertainty때문 일수도 있다. precision과 recall 모두 object detection에 중요한 요소이기 때문에, recall을 높이기 위해 [EOS] likelihood를 임의적으로 낮춰 토큰 샘플링을 늦추는 방식을 진행했지만 noisy하고 반복되는 예측을 하는 결과를 냈따.
일부 이러한 precision과 recall간 trade off는 모델이 detection이라는 채스크를 모르기 때문이라고 생각이 된다. 이러한 문제를 해결하기 위해 우리는 sequence augmentation 기법을 도입하여 태스크에 대한 사전지식을 넣으려고 했다. target sequence인 는 전통적인 language modeling에서 input sequence인 와 같다. 그리고 모든 토큰은 ground-truth이다. sequence augmentation에서는 우리는 대신 실제와 synthetic한 noise token을 포함하여 input sequence를 augment했다. 우리는 또한 target sequence를 수정하여 모델이 이를 따라하는게 아니라 noise token을 찾아낼 수 있도록 하였다. 이는 모델이 noisy하거나 반복되는 예측을 하지 않도록 하는 효과가 있었다.
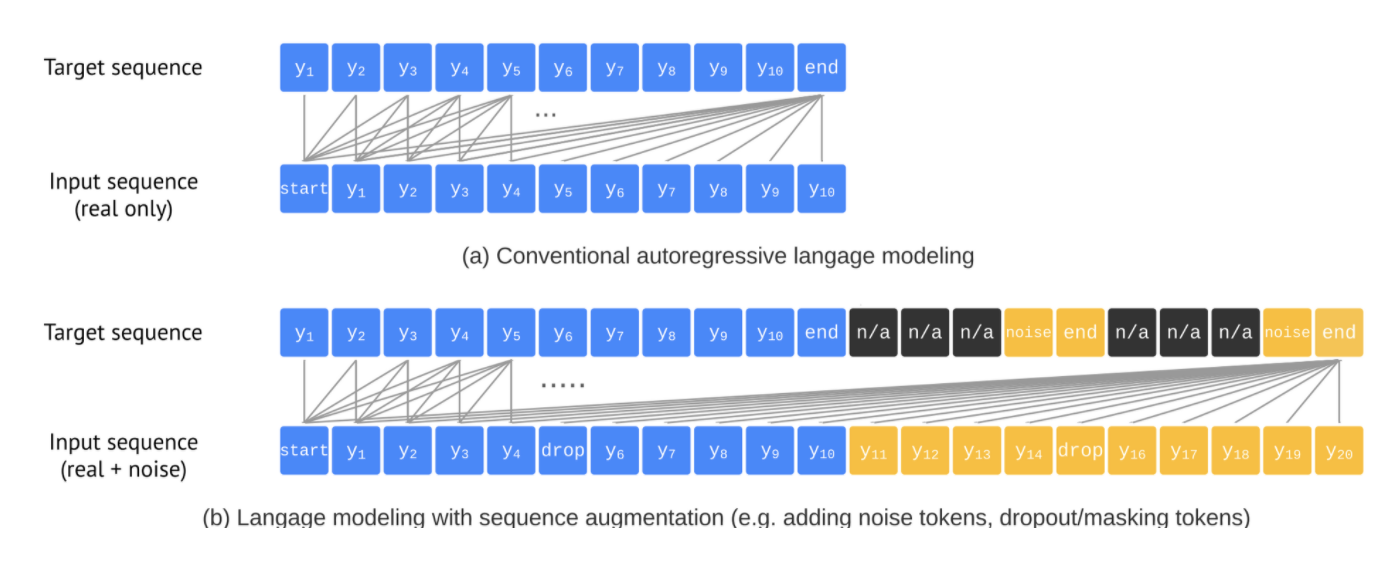
Altered sequence construction
우리는 먼저 input sequence를 augment하기 위해 synthetic noise object를 아래와 같은 방식으로 만들었다. 1) 실제 ground-truth object에 noise를 추가하는 방식 (random scaling or shifting their bounding box) 2) 아예 새로운 random box를 만들어 랜덤 레이블을 부여하는 방식. 이때, 몇개의 노이즈는 실제 bounding box와 같거나 겹칠 수 있다는 점이다. 노이즈 object가 생성되고 토큰으로 표현된 뒤 원래의 input 문장 뒤에 추가하였다. target 시퀀스에 대해서는 noise object에 대해서는 noise class로, noise object에 대한 좌표는 n/a 로 예측하도록 했다. 이때 n/a 에 대한 loss weight는 0으로 설정하였다.
Altered inference
sequence augmentation을 사용하여 [EOS] 토큰을 늦추어 recall을 높이는데 성공했다. 그러므로 우리는 모델이 최대길이 만큼 예측하도록 했고, 고정된 크기의 object 리스트를 뽑도록 했다. 시퀀스에서 바운딩 박스를 뽑을 때는 [noise]를 가장 높은 likelihood를 가진 분류 레이블로 바꿨다. object의 score를 매길 때는 선택된 레이블 토큰의 가장 높은 likelihood를 사용했다.
Result