회사에서 "기본기가 탄탄한 자바 개발자 (제2판)"를 주제로 공부하면서 JVM 소스 코드를 뜯어볼 일이 생겼다. invokevirtual 같은 바이트코드 명령어를 이해하고 싶었기 떄문이다. 저자인 벤저민 J. 에번스의 "자바 최적화" 책도 읽어봤는데 그 때도 도저히 이해가 안갔었기 때문이다. C++ 코드긴 했지만 JVM을 어느정도 뜯어보고 나니 이해하는데 많이 도움이 되었다. 이 김에 다시 한 번 정리해보고자 한다.
객체
JVM에서는 객체가 객체 헤더와 인스턴스 데이터, 메모리 정렬 패딩으로 구성된다. 객체 헤더에는 mark word와 klass word가 있다.
+--------------------+
| Mark Word | // _mark
+--------------------+
| Class Pointer | // _metadata
+--------------------+
| Instance Data | // 클래스 필드
+--------------------+
| Alignment Padding |
+--------------------+
+--------------------+
| Mark Word |
+--------------------+
| Class Pointer |
+--------------------+
| Length | // 배열 길이
+--------------------+
| Array Data | // 배열 요소
+--------------------+
| Alignment Padding |
+--------------------+OpenJDK oop.hpp에는 다음처럼 명시되어 있다. oopDesc 클래스에 mark word, kclass가 필드로 선언되어 있고, field_addr 함수로 필드 데이터를 가져오도록 되어 있다.
class oopDesc {
private:
volatile markOop _mark; // Mark Word
klassOop _metadata; // Class Pointer (klass metadata)
public:
// 메모리에서 객체의 주소를 반환
address address() const { return (address)this; }
// 객체의 markOop를 반환
markOop mark() const { return _mark; }
void set_mark(markOop mark) { _mark = mark; }
// 객체의 클래스 메타데이터 포인터(klassOop)를 반환
klassOop klass() const { return _metadata; }
void set_klass(klassOop k) { _metadata = k; }
// 객체의 필드 데이터를 메모리에서 가져오는 함수
template <class T> T* field_addr(int offset) const {
return (T*)((address)this + offset);
}
};Mark word
OpenJDK markWord.hpp에는 다음처럼 명시되어 있다.
class markWord {
private:
uintptr_t _value; // Mark Word 값을 저장
public:
// Constants
static const int age_bits = 4;
static const int lock_bits = 2;
static const int self_fwd_bits = 1;
static const int max_hash_bits = BitsPerWord - age_bits - lock_bits - self_fwd_bits;
static const int hash_bits = max_hash_bits > 31 ? 31 : max_hash_bits;
uintptr_t value() const { return _value; }
// 락 상태 확인
bool is_locked() const {
return (mask_bits(value(), lock_mask_in_place) != unlocked_value);
}
// GC 세대 정보 반환
uint age() const {
return (uint) mask_bits(value() >> age_shift, age_mask);
}
// 객체 해시코드 반환
intptr_t hash() const {
return mask_bits(value() >> hash_shift, hash_mask);
}
};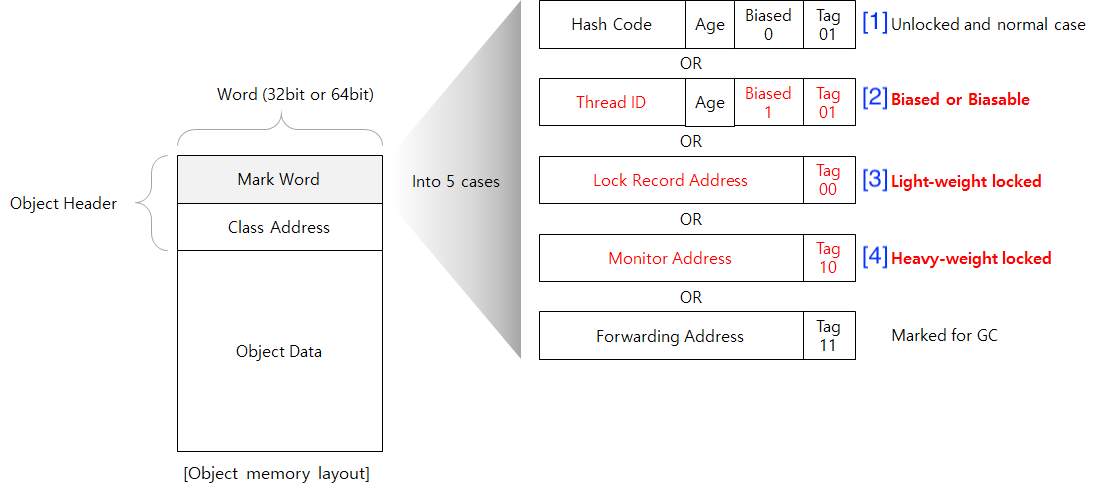
여기에는 JVM GC 정보나 세대(Age), Biased, Hash code 등이 저장된다.
Hash code 31비트
자바도 그렇고 JVM C++도 그렇고 특이하게도 hash code는 31 비트로 사용한다. 둘이 살짝 다른데 비교하자면 아래처럼 다르다.
| 특징 | Mark Word 31비트 제한 (Identity hash code) | 자바 해시코드 계산에서 31 사용 (Hash code) |
|---|---|---|
| 목적 | 음수 해시코드를 방지하고, JVM 데이터 구조와 호환. | 해시 충돌을 줄이고, 해시 테이블 분포 최적화. |
| 적용 범위 | JVM 내부에서만 적용 (Mark Word에 저장된 해시코드). | 자바 언어 레벨에서 hashCode() 메서드 연산. |
| 기술적 이유 | 부호 비트(sign bit)를 피하기 위해. | 소수의 성질로 분포 특성을 개선. |
| 작동 방식 | 비트 마스크로 상위 비트를 제외. | 필드 간의 곱셈 기반 연산. |
hash code 31비트
일단 hash code는 int 자료형이기에 32비트(4바이트)를 가진다. 그럼에도 불구하고 31비트를 쓰는 이유는, 31비트가 소수이기 때문에 해시 분포에서 유리하기 때문이다. 그리고 2n +- 1 연산은 비트 연산으로 빠르게 계산할 수 있기 때문에 마이크로 최적화에 유리하다.
bit case) 1011 & 1100 = 1000 ← 비트 하나하나 AND만 하면 끝
add case) 1111 + 0001 = 1 0000 (4비트에서 오버플로 발생, n비트는 n단계 carry 전파 발생)
CPU는 다음 순서로 처리
Sum = A XOR B
Carry = A AND B
Result = Sum XOR Carry (다음 자리로 넘어감)
다만 HashMap이나 ConcurrentHashMap 자료형은 음수를 받아들일 수 없는 제약이 있어, 앞에 부호 비트를 제거한 31비트를 사용한다.
int index = (hash & 0x7FFFFFFF) % table.length;identity hash code 31비트
Mark word (identity hash code)는 비트 단위로 다른 정보를 저장하고 있기 때문에, 양수 음수 여부와 상관없이 25비트만 지원된다.
JVM Hash code 25비트
hash_bits를 잘보면 max_hash_bits에 따라 25비트(32비트 OS) 또는 31비트(64비트 OS)로 결정된다.
public:
// Constants
static const int age_bits = 4;
static const int lock_bits = 2;
static const int self_fwd_bits = 1;
static const int max_hash_bits = BitsPerWord - age_bits - lock_bits - self_fwd_bits;
static const int hash_bits = max_hash_bits > 31 ? 31 : max_hash_bits;근데 분명 Java 소스 코드 레벨에서는 hashCode()가 항상 32비트 정수를 반환하도록 되어 있다. 이러한 스펙 차이는 아키텍처 비트수 차이 때문인데, 32비트 OS는 age, biased_lock, lock 필드의 비트수 차지로 공간이 부족해 25비트만을 사용한다. 반대로 64비트 OS는 자리는 충분하나 음수의 문제로 31비트를 사용한다.
32비트 OS에서는 25비트 ID Hash code를 써야하지만 자바에서의 32비트 Hash code를 지원하기 위해, 남은 비트 수를 0으로 채운다. 이를 통해 2^25 = 약 33,554,432 가지의 고유 값을 지원한다.

더 궁금하다면 How is a 32-bit hashCode stored in a 25-bit mark word in Java without data loss? 를 참고하면 좋을 것 같다.
Age 4비트
GC 생명주기 및 -XX:MaxTenuringThreshold 옵션과 관련이 있는 필드이다. 4비트이기에 총 16가지를 기록할 수 있는데, 전체 비트를 다 쓰기도 하고 남기기도 한다. 추가적인 기능을 대비해서 남겨놓은 한편, 앞서 언급한 옵션에 값을 0 ~ 15 사이로 설정해 언제 Old generation으로 이동시킬지 설정할 수 있다.
Biased_lock 1비트
Biased locking과 관련된 필드이다. Synchronization block에 진입하는 thread가 여러 번 락을 얻는 경우, 락 상태를 유지하도록 해 락 획득과 해제의 오버헤드를 줄이는 기술이다. Biased_lock 필드를 1로 변경하면 JVM이 락 경합이 거의 없는 경우를 감지해서 해당 기술을 활성화한다. JDK 15에서부터는 비활성화되었다. 현대 어플리케이션에서는 성능 이점이 감소했고 유지 관련 비용이 높기 때문이다. 자세한 내용은 JEP 374: Deprecate and Disable Biased Locking을 참고하자.
lock 2비트
Lock 비트는 JVM에서의 Biased locking, Lightweight locking, Heavyweight locking을 지원하기 위한 필드이다.
| Lock 상태 | lock 필드 값 | Mark Word 내용 |
|---|---|---|
| Unlocked 상태 | 11 | Mark Word에 해시코드 또는 GC 정보가 저장. |
| Biased Locking | 00 | 특정 스레드 ID가 저장. |
| Lightweight Locking | 01 | Lock Record의 주소가 저장. |
| Heavyweight Locking | 10 | Monitor 객체의 주소가 저장. |
Lightweight locking
락 경합이 적은 경우 락 획득 비용을 줄이기 위한 최적화이다. 단일 스레드가 락을 사용할 때 일반적으로 사용된다.
-
객체의 Mark Word가 Unlocked 상태(기본 상태)일 때, JVM은 동기화 블록에 진입한 스레드에 Lightweight Locking 적용
-
JVM은 현재 스레드의 Lock Record를 생성하고, Mark Word를 해당 Lock Record를 가리키도록 업데이트
-
동기화 블록을 빠져나오면 Lock Record가 해제되고 Mark Word가 원래 상태로 복원
이 때 Lock record는 스레드의 스택에 저장된다.
Heavyweight locking
락 경합이 심한 경우에 사용된다. 객체의 동기화가 Monitor를 통해 관리되고 CPU와 메모리의 추가 비용이 발생한다.
-
Lightweight Lock 상태에서 다른 스레드가 동일한 락을 요청하면, JVM은 Lightweight Locking을 Heavyweight Locking으로 전환.
-
JVM은 객체에 대한 Monitor를 생성하고, Mark Word를 해당 Monitor의 주소로 업데이트.
-
Monitor는 OS의 Mutex를 사용하여 락 상태 관리.
Klass word
OpenJDK klass.hpp에는 다음처럼 명시되어 있다. 객체의 클래스 구조에 대한 포인터로 이를 통해 객체가 속한 클래스의 메서드, 필드, vtable, 인터페이스 등을 추적할 수 있다. JVM 내부에서 클래스 메타데이터(Class Metadata)를 가리킨다.
// Klass는 모든 Java 클래스의 메타데이터를 표현하는 기본 클래스입니다.
// 객체의 이름, 상위 클래스, 인터페이스, 메서드 및 필드 정보 등 클래스 정보를 저장합니다.
class Klass {
protected:
// 클래스 이름 (Symbol*는 JVM 내부에서 문자열을 관리하는 구조체)
Symbol* _name;
// 상위 클래스 (부모 클래스)
Klass* _super;
// 가상 메서드 테이블(vtable)의 길이
int _vtable_length;
// 클래스 로더 (klass를 로드한 클래스 로더에 대한 참조)
KlassLoaderData* _class_loader_data;
// 메모리 레이아웃 정보 (객체 크기와 필드 배치를 관리)
int _layout_helper;
// 클래스의 접근 제한 플래그 (public, private, abstract 등)
AccessFlags _access_flags;
public:
// 클래스 이름을 반환합니다.
Symbol* name() const {
return _name;
}
// 상위 클래스를 반환합니다.
Klass* superklass() const {
return _super;
}
// vtable(가상 메서드 테이블)의 길이를 반환합니다.
const int vtable_length() const {
return _vtable_length;
}
// 클래스 로더 데이터를 반환합니다.
KlassLoaderData* class_loader_data() const {
return _class_loader_data;
}
// 메모리 레이아웃 정보를 반환합니다.
int layout_helper() const {
return _layout_helper;
}
// 클래스의 접근 제한 플래그를 반환합니다.
AccessFlags access_flags() const {
return _access_flags;
}
// 객체가 인터페이스인지 여부를 확인합니다.
bool is_interface() const {
return (_access_flags.is_interface());
}
};OpenJDK instanceKlass.hpp에는 다음처럼 명시되어 있다. 일반 Java 클래스의 메타데이터를 관리한다.
// InstanceKlass는 일반 Java 클래스의 메타데이터를 관리하는 클래스입니다.
// 필드, 메서드, 상수 풀, 인터페이스 등 Java 클래스와 관련된 세부 정보를 포함합니다.
class InstanceKlass : public Klass {
private:
// 상수 풀(Constant Pool)의 참조
ConstantPool* _constants;
// 클래스에 정의된 모든 메서드 배열
Array<Method*>* _methods;
// 클래스에 정의된 모든 필드 배열
Array<FieldInfo*>* _fields;
// 구현된 인터페이스 배열
Array<Klass*>* _interfaces;
// 상위 클래스의 참조
Klass* _super;
public:
// 상수 풀을 반환합니다.
ConstantPool* constant_pool() const {
return _constants;
}
// 클래스에 정의된 메서드 배열을 반환합니다.
Array<Method*>* methods() const {
return _methods;
}
// 클래스에 정의된 필드 배열을 반환합니다.
Array<FieldInfo*>* fields() const {
return _fields;
}
// 클래스가 구현한 인터페이스 배열을 반환합니다.
Array<Klass*>* interfaces() const {
return _interfaces;
}
// 상위 클래스를 반환합니다.
Klass* superklass() const {
return _super;
}
// 클래스의 필드 수를 반환합니다.
int fields_count() const {
return _fields->length();
}
// 클래스의 메서드 수를 반환합니다.
int methods_count() const {
return _methods->length();
}
// 인터페이스 수를 반환합니다.
int interfaces_count() const {
return _interfaces->length();
}
};필드를 정리하자면 아래와 같다. 이러한 클래스를 활용해 Java에서 선언한 필드와 메소드들이 관리된다.
| 필드 | 역할 |
|---|---|
_name | 클래스 이름 (Symbol* 구조체). |
_super | 상위 클래스 (부모 클래스). |
_vtable_length | 가상 메서드 테이블의 길이. |
_class_loader_data | 클래스를 로드한 클래스 로더에 대한 참조. |
_layout_helper | 메모리 레이아웃 정보 (객체 크기 및 필드 배치). |
_access_flags | 클래스의 접근 제한 플래그 (public, private, abstract 등). |
_constants | 클래스의 상수 풀. |
_methods | 클래스의 모든 메서드 배열. |
_fields | 클래스의 모든 필드 배열. |
_interfaces | 클래스가 구현한 모든 인터페이스 배열. |
Instance data
OpenJDK fieldInfo.hpp에는 다음처럼 명시되어 있다. 인스턴스에 있는 필드와 접근 제한자 등을 담당한다.
#ifndef FIELD_INFO_HPP
#define FIELD_INFO_HPP
#include "symbol.hpp" // Symbol 클래스 포함
#include "constantPool.hpp" // ConstantPool 포함
class FieldInfo {
private:
// 필드 정보를 저장하는 6개의 16비트(short) 배열
u2 _shorts[6];
// 필드에 대한 추가 메타데이터
u2 _allocation_type;
public:
// 접근 제한자 플래그 (public, private 등) 반환
u2 access_flags() const {
return _shorts[0];
}
// 상수 풀에서 필드 이름의 인덱스 반환
u2 name_index() const {
return _shorts[1];
}
// 상수 풀에서 필드 시그니처의 인덱스 반환
u2 signature_index() const {
return _shorts[2];
}
// 상수 풀에서 필드 초기값의 인덱스 반환
u2 initval_index() const {
return _shorts[3];
}
// 필드의 메모리 오프셋 반환
u4 offset() const {
return *((u4*)(&_shorts[4]));
}
// 필드가 경쟁 상태인지 여부 반환
bool is_contended() const {
return _shorts[4] != 0;
}
// 경쟁 그룹 반환
u2 contended_group() const {
return _shorts[5];
}
// 필드의 할당 타입 반환
u2 allocation_type() const {
return _allocation_type;
}
// 필드 오프셋이 설정되었는지 여부 반환
bool is_offset_set() const {
return offset() != 0;
}
// 상수 풀 핸들을 사용해 필드 이름 반환
Symbol* name(const ConstantPool* cp) const {
return cp->symbol_at(name_index());
}
// 상수 풀 핸들을 사용해 필드 시그니처 반환
Symbol* signature(const ConstantPool* cp) const {
return cp->symbol_at(signature_index());
}
// 접근 제한자 플래그 설정
void set_access_flags(u2 val) {
_shorts[0] = val;
}
// 필드 오프셋 설정
void set_offset(u4 val) {
*((u4*)(&_shorts[4])) = val;
}
// 필드 할당 타입 설정
void set_allocation_type(u2 type) {
_allocation_type = type;
}
// 경쟁 그룹 설정
void set_contended_group(u2 val) {
_shorts[5] = val;
}
// 필드가 내부적인지 여부 반환
bool is_internal() const {
return access_flags() & JVM_ACC_INTERNAL;
}
// 필드가 안정적인지 여부 반환
bool is_stable() const {
return access_flags() & JVM_ACC_STABLE;
}
// 필드 안정성 설정
void set_stable(bool z) {
if (z) {
set_access_flags(access_flags() | JVM_ACC_STABLE);
} else {
set_access_flags(access_flags() & ~JVM_ACC_STABLE);
}
}
};
#endif // FIELD_INFO_HPPAlignment padding
메모리 워드 단위를 맞추기 위해 사용되는 빈 공간이다. 주된 목적은 CPU가 메모리를 더 효율적으로 접근할 수 있도록 데이터의 시작 주소를 특정 크기(32비트, 64비트 등)에 맞추는 것이다.
Compressed OOPs
64비트 JVM에서 객체 참조를 32비트로 압축하여 메모리 사용량을 줄이는 최적화 기법이다. 64비트 OS에서는 그대로 64비트를 쓰기엔 대역폭이나 사용량의 문제가 있기 때문에, 최대한 효율적으로 컴퓨팅 자원을 절약하는 기법이다. 이론상 64비트 주소 공간은 16EB를 지원하지만 실제 어플리케이션에서 사용하는 메모리는 이보다 훨씬 적게 쓰기 때문에, 굳이 64비트를 다 쓸 필요는 없다.
8 바이트 정렬 최적화
64비트 OS에서 I/O를 할 때 데이터를 8로 묶어서 가져간다. 하지만 앞서 찾아본 JVM은 32비트로도 충분히 운용이 가능했다. 따라서 JVM에서는 32비트 offset을 관리하고, 하위 3비트는 항상 0으로 할당해 8 단위를 맞춘다. 이를 통해 데이터들을 테트리스 조합하듯이 짜맞춰 8바이트 경계를 쉽게 맞출 수 있도록 한 것이다. 그렇다보니 기존에는 2^32 = 4GB 까지 힙을 쓸 수 있었지만, 8바이트 정렬 덕분에 2^32 * 8 = 32GB까지 힙을 사용할 수 있게 되었다. 이런 제한은 어디까지나 가상 메모리에 대한 제한이다.
Generic
Java, Kotlin 처럼 JVM 계열 언어에는 abstract와 interface를 지원하는 게 많다. 실제로 어떻게 지원되는지 알아보자.
Type erasure
JVM에서는 타입 소거(Type erasure) 방식으로 Generic을 지원한다. Generic은 컴파일 타임에만 존재하고 JVM 바이트코드에서는 Generic 타입 정보를 제거한다. 따라서 런타임에는 타입 정보를 유지하지 않는 방식이다. 기본적으로 Object로 대체되며 upper bound가 있을 경우 해당 클래스로 대체된다.
// 컴파일 전
public class GenericClass<T> {
public void add(T item) {
System.out.println(item);
}
}
// 컴파일 이후
public class GenericClass {
public void add(Object item) {
System.out.println(item);
}
}
// 컴파일 전
public <T extends Integer> T process(T input) {
return input;
}
// 컴파일 이후
public Integer process(Integer input) {
return input;
}
// 컴파일 전
public void process(List<? super Number> list) { }
// 컴파일 이후
public void process(List list) { }타입 서명 (타입 시그니처)
VM이 메서드, 필드, 제네릭 등과 관련된 타입 정보를 표현하기 위해 사용하는 형식화된 문자열이다. 이는 바이트코드 수준에서 데이터 타입을 정확히 나타내기 위한 규칙으로, 클래스 파일의 Constant Pool에 저장된다. JVM에서는 Symbol이라는 구조체로 지원된다.
class Symbol : public MetaspaceObj {
private:
u1 _length; // 문자열의 길이 (바이트 단위)
u1 _body[1]; // 문자열 데이터를 저장하는 배열 (가변 크기)
public:
// 문자열의 길이를 반환하는 메서드
int length() const {
return (int)_length;
}
// 문자열의 내용을 반환하는 메서드
char* as_C_string() const;
// 특정 인덱스에 있는 문자 반환
char char_at(int index) const {
assert(index >=0 && index < length(), "symbol index overflow");
return (char)base()[index];
}
// 문자열 비교
bool equals(const char* str, int len) const {
int l = utf8_length();
if (l != len) return false;
return contains_utf8_at(0, str, len);
}
};
class SymbolTable : public AllStatic {
public:
static Symbol* new_symbol(const char* name, int length);
static Symbol* lookup(const char* name, int length);
};Java에서 문자열 상수를 선언하면 Constant pool에 등록해서 사용한다는 내용을 들어본 적이 있을 것이다. 실제로 저장되는 위치는 SymbolTable이라는 class고 클래스 함수로 관리하기 때문에, JVM 내에서 Symbol 객체를 캐싱하고 관리한다. 덕분에 동일한 문자열은 항상 동일한 Symbol 객체를 참조하도록 보장한다.
조금 뒤 알아볼 타입 서명도 결국 문자열이기 때문에 SymbolTable에 등록된다. Reflection API는 이 클래스에 접근하여 Symbol*를 통해 런타임에도 Generic을 알아낼 수 있는 것이다.
// constantPool.hpp
class ConstantPool {
private:
u2 _length; // Constant pool 크기
constantTag* _tags; // 각 항목의 태그 정보
u2* _indexes; // Constant pool의 인덱스
public:
// 특정 상수 풀 항목을 반환하는 메서드
const char* signature_at(int index) const {
return tag_at(index).is_signature() ? symbol_at(index)->as_C_string() : NULL;
}
};
// instanceKlass.hpp
class instanceKlass : public Klass {
private:
constantPoolHandle _constants; // Constant Pool 참조
Array<Method*>* _methods; // 메서드 배열
Symbol* _generic_signature; // 제네릭 타입 서명
public:
// 제네릭 타입 서명을 반환하는 메서드
Symbol* generic_signature() const {
return _generic_signature;
}
};
// method.hpp
class Method {
private:
Symbol* _signature; // 메서드 서명 (타입 소거 후)
ConstantPool* _constants; // 메서드의 Constant Pool 참조
public:
// 메서드 서명을 반환하는 메서드
Symbol* signature() const {
return _signature;
}
};Primitive types
JVM 기본 데이터 타입은 한 글자의 약어로 표현된다.
| 기본 타입 | 서명(Signature) | 설명 |
|---|---|---|
boolean | Z | 1바이트 크기 |
byte | B | 1바이트 크기 |
char | C | 2바이트 크기 |
short | S | 2바이트 크기 |
int | I | 4바이트 크기 |
long | J | 8바이트 크기 |
float | F | 4바이트 크기 |
double | D | 8바이트 크기 |
void | V | 반환 값 없음 |
Reference types
참조 타입은 L과 세미콜론 ;으로 감싸서 표현한다.
Lfully/qualified/ClassName;Generic은 <T>를 사용한다.
public class Example<T> {
}<T:Ljava/lang/Object;>Ljava/lang/Object;- <T:Ljava/lang/Object;>: T는 Object를 상속
- Ljava/lang/Object;: 클래스의 기본 상속 구조
기본적으로 참조 타입은 Object를 상속한다.
upper bound, lower bound, unbounded wildcard는 부호로 지원된다.
List<? extends Number> -> Ljava/util/List<+Ljava/lang/Number;>;
List<? super Number> -> Ljava/util/List<-Ljava/lang/Number;>;
List<?> -> Ljava/util/List<*>;Array types
배열 타입은 대괄호 [를 사용하여 표현된다.
int[]의 서명 -> [I
String[][]의 서명 -> [[Ljava/lang/String;Method types
메서드는 매개변수의 타입과 반환타입을 포함한다.
(매개변수 타입들)반환 타입
public int add(int a, int b); -> (II)I
public String add(int a, int b); -> (II)Ljava/lang/String;vtable
OpenJDK klassVtable.hpp에는 다음처럼 명시되어 있다. JVM이 가상 메서드 디스패치를 최적화하기 위해 사용하는 virtual method table이다. 클래스의 virtual methods에 대한 포인터가 저장된다. 각 클래스마다 고유한 vtable을 가진다. invokevirtual 바이트코드 명령어를 처리할 때 활용된다.
class Vtable {
private:
Method* _methods; // 클래스의 메서드 배열 (vtable에서 직접 사용)
int _length; // 메서드 개수
public:
Method* method_at(int index) const {
assert(index >= 0 && index < _length, "Index out of bounds");
return &_methods[index];
}
};아래와 같은 Java 코드가 있다면 vtable은 다음처럼 매핑된다.
class Animal {
void sound() { System.out.println("Animal sound"); }
void walk() { System.out.println("Animal walk"); }
}
class Dog extends Animal {
@Override
void sound() { System.out.println("Dog barks"); }
}Animal의 vtable
[0] -> Address of Animal::sound
[1] -> Address of Animal::walk
Dog의 vtable
[0] -> Address of Dog::sound
[1] -> Address of Animal::walk- 상속받은 클래스는 부모 클래스의 vtable을 복사하고 재정의한 메서드만 새롭게 대채한다.
- 각 메서드는 vtable 내에서 고정된 오프셋을 가지므로, 런타임에 메서드 주소를 빠르게 조회할 수 있다.
itable
OpenJDK klassVtable.hpp에 명시되어있다. JVM에서 인터페이스 기반 메서드 디스패치를 구현하기 위해 사용되는 테이블이다. 클래스는 구현하는 모든 인터페이스에 대해 별도의 itable을 생성한다. Java에서는 인터페이스를 다중 구현할 수 있으므로, 각 인터페이스에 대해 별도의 itable이 필요한 것이다. 이를 통해 invokeinterface 바이트코드 명령어를 처리한다.
class itableOffsetEntry {
private:
InstanceKlass* _interface; // 인터페이스 클래스
int _offset; // vtable에서 메서드 엔트리 시작 위치
}
class itableMethodEntry {
private:
Method* _method; // 메서드에 대한 포인터
}
class klassItable {
private:
InstanceKlass* _klass; // 현재 클래스
int _table_offset; // itable 시작 위치 오프셋 (클래스 데이터 내)
int _size_offset_table; // offset 테이블 크기 (itableOffsetEntry 개수)
int _size_method_table; // 메서드 테이블 크기 (itableMethodEntry 개수)
public:
itableOffsetEntry* offset_entry(int i) {
assert(0 <= i && i <= _size_offset_table, "index out of bounds");
return &((itableOffsetEntry*)vtable_start())[i];
}
itableMethodEntry* method_entry(int i) {
assert(0 <= i && i <= _size_method_table, "index out of bounds");
return &((itableMethodEntry*)method_start())[i];
}
}아래처럼 2개의 테이블을 사용해 다중 구현을 지원한다.
itable Offset Table
| 인터페이스 | vtable 오프셋 |
|---|---|
I | 0x10 |
J | 0x20 |
itable Method Table
| 메서드 | 구현체 메서드 |
|---|---|
I::methodI() | &C::methodI() |
J::methodJ() | &C::methodJ() |
invoke 명령어
JVM에는 총 5개의 invoke 명령어가 있다.
- invokevirtual - 인스턴스 메서드를 호출하기 위해 사용, vtable 사용
- invokeinterface - 인터페이스 메서드를 호출하기 위해 사용, itable 사용
- invokestatic - 정적 메서드를 호출하기 위해 사용, constant pool 사용
- invokespecial - 특수한 메서드에 대해 런타임 디스패치를 거치지 않고 호출할 메서드가 컴파일 시점에 정적으로 결정, constant pool 사용
- invokedynamic - 동적으로 메서드 호출 방식을 결정, constant pool과 bootstrapMethods(bootstrap), heap(call site 객체) 사용
위에서 살펴본 것처럼 invokevirtual과 invokeinterface는 각각의 자료구조를 사용하기 때문에 복잡하다. 하지만 invokestatic과 invokespecial은 constant pool를 사용하기 때문에 비교적 간단하다. 대신 generic을 지원하지 못하기에 static / private / constructor 등에 사용한다.
invokedynamic은 람다처럼 동적 메소드 호출을 지원하기 위해 등장한 바이트코드 명령어다. 덕분에 Java, Kotlin 같은 정적 JVM 언어에서의 함수형 프로그래밍을, Closure 같은 동적 JVM 언어에서의 동적 타입을 제대로 지원해줄 수 있게 되었다.
점점 low level
회사에서 "기본기가 탄탄한 자바 개발자 (제2판)"라는 책으로 신입 동기들과의 책 스터디가 이번달에 마무리 되었다. 책 제목이랑 대충 앞 챕터 몇 개 보고 무난할 거 같아서 골랐는데, 막상 사고 보니 저자 분이 "자바 최적화"를 집필하신 벤저민 J. 에번스 님이었다. 이분 또 바이트코드를 뭔가 엄청 알려줄 것 같은 기분인데... 자바 최적화 책을 먼저 읽은 나로서는 바이트코드 PTSD가 올 수 밖에 없었다. 아니나 다를까 역시 바이트코드로 많은 걸 설명하시는 선배님이셨고, 발자취조차 따라가기 벅찬 우리였다. 이제 애들이 내가 추천한 책은 안 읽는데요ㅠㅠ 얘들아 새해맞이로 오브젝트 스터디 반드시 해야지^^?

그 와중에 유일하게 바이트코드만 이야기하는 Reflection과 invoke 바이트코드 명령어 챕터 발표에 당첨되버린 나. 머리를 박지 않을 수 없었다.

이왕 머리 박은거... 이정도로 박았으면 그냥 제대로 알고 가자는 생각에 정리를 시작한 포스팅이지만, 하나하나 정말정말 어려웠다. 컴퓨터 구조 수업을 다시 듣는거마냥 C++와 비트 단위로 이해해야하는 내용에 증말 쉽지 않았다. 이렇게 공부하다보니 요즘 점점 low level로 내려가는 것 같다. 인간 컴퓨터가 되어버린건지 사실 코드를 안보면 내용이 잘 와닿지 않는 것도 한몫 한다...ㅋㅎ
우여곡절 끝에 정리를 끝냈고 나니까 이제 객체나 상속 같은 개념이 어떻게 구현되는지, 다른 언어들은 어떻게 구현될 것 같은지 대충 예상 아닌 예상을 감히 해볼 정도로 이해도가 많이 올라온 것 같다. 하다보니 JavaScript hoisting이 왜 적용되는지 궁금해져서 그쪽도 살짝 뒤져보긴 했는데, 그건 나중에 기회가 되면 정리해볼 생각이다.
그리고 이건 언제 생겼는지 모르겠는데 깃허브에서 이렇게 이쁘게 코드 구조를 정리해주는 UI가 생겼다. 덕분에 Command + F로 맨날 일일이 찾을 필요 없이 슉슉 원하는 곳으로 이동할 수 있었다. 이걸로 찾아보니까 뭔가 소스 코드 맨날 뜯어본 내공 있는 사람인 척 할 수 있어서 멋져보임.
