최근에 K6, async-profiler 등을 알게 되어 대학생 시절에 못 해봤던 부하테스트를 직접 해봤다. Grafana 나 flame-chart 같은 걸로 쉽게 접근할 수 있어서, 되게 편리하게 세팅하고 결과도 볼 수 있었다. 이 김에 욕심이 생겨서 Grafana LGTM + Opentelemetry + PMM 까지 연동해서, 서비스의 시작부터 끝까지 전부 확인해보고 싶었다.
대학교 때 꼭 해보고 싶은 것 중에 부하테스트랑 APM이 있었다. 트래픽이랑 성능 이야기를 하다보면 꼭 나오는 키워드인데, 내가 만든 서버에선 이런 걸 어떻게 할지 정말 감이 안와서... 막상 jmeter로 시도해봤을 땐 세팅을 제대로 한 건 맞는건지, 결과를 어떻게 봐야하는 건지 잘 몰라서 흥미가 좀 식었던거 같다. (백엔드 시작한지 반년도 안 돼서 마음만 앞선 응애 개발자) 그래도 이번 기회에 죄다 구축해서 신나시잖아요~!
부하 테스트 계획
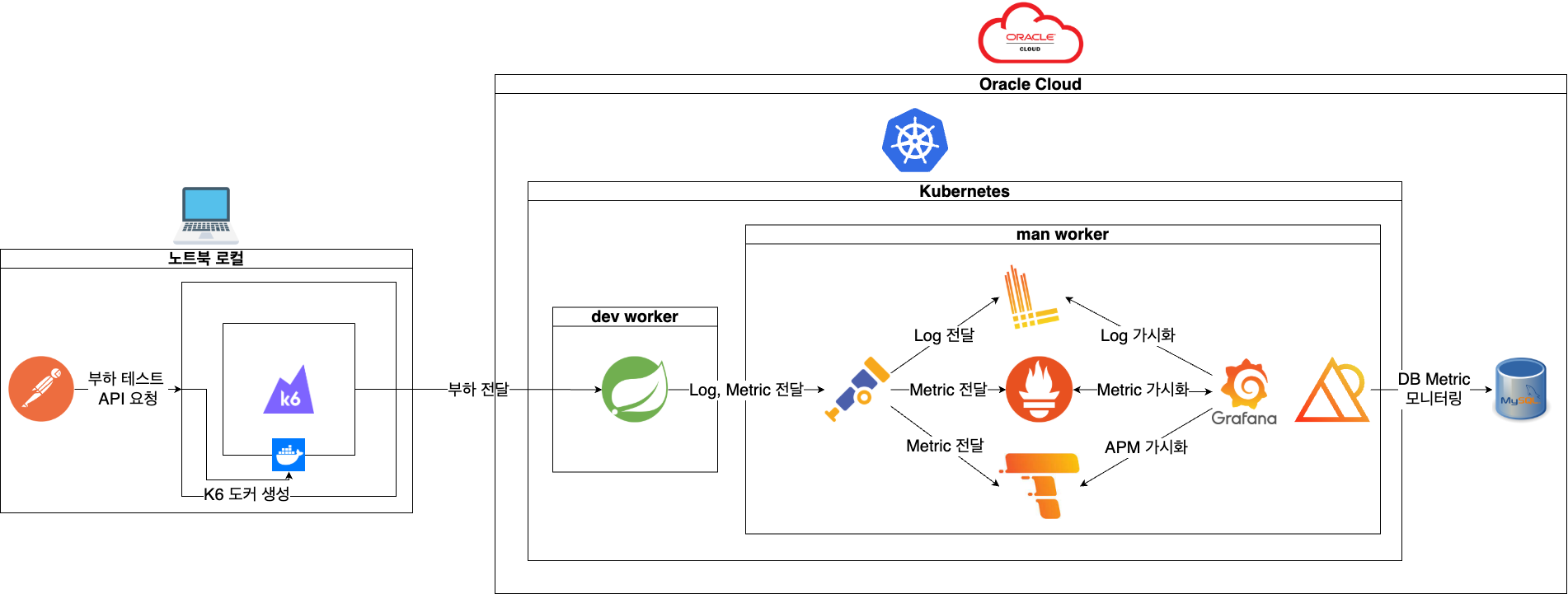
구성도
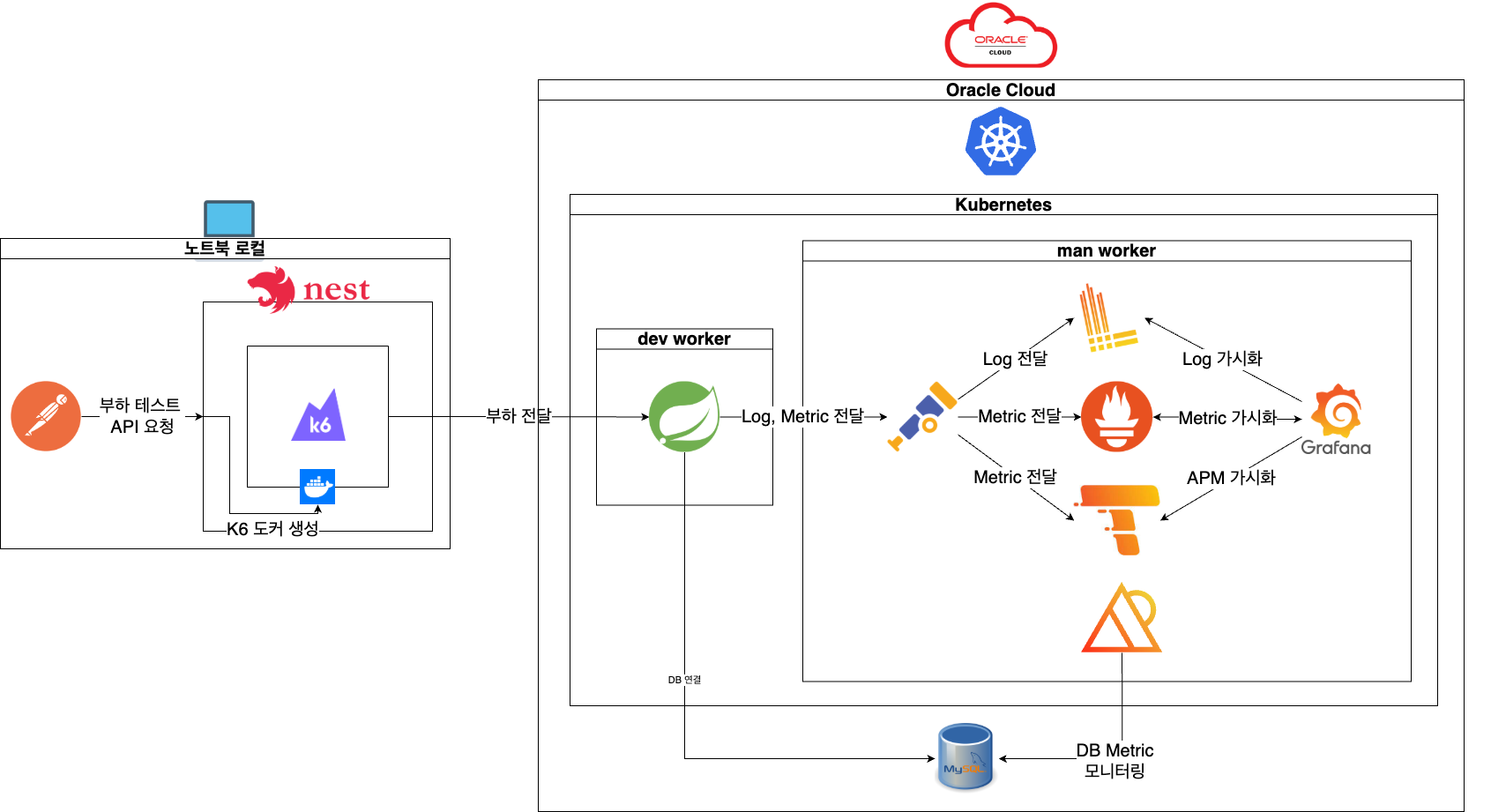
부하 생성기
- M1 Air CPU 8코어 메모리 16GB
대상 서버 및 DB
- K8S worker node 중 dev node
- Spring boot MVC 3.4.1
- MySQL 8.0
모니터링
- Opentelemetry: 성능 메트릭 및 트레이스 수집
- Loki: 애플리케이션 및 시스템 로그 수집 및 분석
- Prometheus: 서버 및 애플리케이션 성능 데이터 수집
- Tempo: 트랜잭션 트레이스 시각화
- Grafana: 통합 대시보드 구성 및 시각화
- PMM(Percona Monitoring and Management): MySQL 성능 메트릭 및 쿼리 프로파일링
부하 시나리오
- 가상 사용자: 10명
- 테스트 시간: 15명
- 대상 서버
- 플랫폼: Kubernetes
- 노드 사양: arm64 CPU 1코어 메모리 5GB
- Spring boot MVC 3.4.1
- 테스트 단계: 기존 환경에서 CPU를 1코어 -> 2코어 -> 3코어로 상향
- 테스트 목표:
- 각 코어별 서버 최대 처리량 지표 확보
- 병목 지점 확인 (Tomcat, DB Connection pool)
모니터링 항목
- Spring Boot
- 총 요청량
- 평균 요청 처리 시간
- 99% & 95% 응답 시간(PR99, PR95)
- RPS (초당 요청량)
- 네트워크, 호출 SQL 쿼리 등 처리 시간 (APM)
- JVM
- CPU & Heap 사용량
- 현재 Thread 개수
- GC 빈도
- K6
- 총 요청량
- RPS (초당 요청량)
- 평균 & 최대 응답 시간
- MySQL
- Connection 개수
- 쿼리 지연 시간
- CPU & Memory 사용량
서버 설정값
Tomcat
server:
shutdown: graceful # 애플리케이션 종료 시 요청을 정상적으로 처리하고 종료하는지 설정 (기본값: graceful)
tomcat:
threads:
max: 200 # 최대 워커 스레드 수. 요청 처리를 위해 사용할 최대 스레드 수 (기본값: 200)
min-spare: 10 # 최소 유휴 스레드 수. 준비 상태를 유지하는 최소 스레드 수 (기본값: 10)
max-queue-capacity: 2147483647 # 대기 큐의 최대 용량. 모든 스레드가 사용 중일 때 대기할 수 있는 요청 수 (기본값: Integer.MAX_VALUE)
max-connections: 8192 # 동시 연결의 최대 수. HTTP 커넥션에서 허용할 동시 연결 수 제한 (기본값: 8192)
accept-count: 100 # 최대 연결 대기 큐 크기. 허용된 스레드가 모두 사용 중일 때 추가 연결 요청을 대기시킬 수 있는 큐 크기 (기본값: 100)
connection-timeout: 60000 # 서버 소켓이 연결을 대기하는 최대 시간 (밀리초 단위, 기본값: 60000ms)
keep-alive-timeout: 30000 # Keep-Alive 커넥션이 유지되는 최대 시간 (밀리초 단위, 기본값: 30000ms)
max-http-header-size: 8192 # HTTP 요청 및 응답 헤더의 최대 크기 (바이트 단위, 기본값: 8192)
max-keep-alive-requests: 100 # 단일 Keep-Alive 연결에서 처리할 최대 요청 수 (기본값: 100)HikariCP
spring:
datasource:
hikari:
maximum-pool-size: 100 # 풀에서 최대 커넥션 수 (기본값: 10)
minimum-idle: 10 # 최소 유휴 커넥션 수 (기본값: 10)
idle-timeout: 600000 # 유휴 커넥션을 풀에서 제거하기까지의 시간 (기본값: 600,000ms = 10분)
max-lifetime: 1800000 # 커넥션이 풀에서 제거되기 전 최대 사용 가능 시간 (기본값: 1,800,000ms = 30분)
connection-timeout: 30000 # 풀에서 커넥션을 가져오기 위한 최대 대기 시간 (기본값: 30,000ms = 30초)
validation-timeout: 5000 # 커넥션 유효성을 검사하기 위한 최대 대기 시간 (기본값: 5,000ms = 5초)
initialization-fail-timeout: 1 # 초기화 실패 시 최대 대기 시간 (기본값: 1ms, 0은 비활성화)
read-only: false # 풀에서 커넥션을 read-only 모드로 가져올지 여부 (기본값: false)
leak-detection-threshold: 0 # 커넥션 누수를 감지하기 위한 임계값 (기본값: 0ms = 비활성화)
registerMbeans: false # JMX MBean 등록 여부 (기본값: false)부하 결과
요약
| 지표 | 1코어 환경 | 2코어 환경 | 3코어 환경 |
|---|---|---|---|
| 총 요청 수 | 4,521 | 8,782 | 7,133 |
| 평균 응답 시간 | 2.00초 | 1.00초 | 1.30초 |
| 99% 응답 시간 | 2.5~3.5초 | 1.0~1.3초 | 1.0~1.5초 |
| CPU 사용률(평균) | 99.96% | 98.79% | 97.42% |
| 최대 처리량(RPS) | 7 RPS | 12 RPS | 10 RPS |
| 에러율 | 0% | 0% | 0.14% |
| JVM Heap 사용량(평균) | 160~173MB | 82~91MB | 84~92MB |
- 코어 향상시 처리량 향상 기대
- 2코어, 3코어 환경에서 throttling 발생
- CPU bound 작업이 굉장히 많음
- Tomcat이 request를 처리하지 못 하는 경우 발생
- DB connection pool은 idle로 여유로운 상태
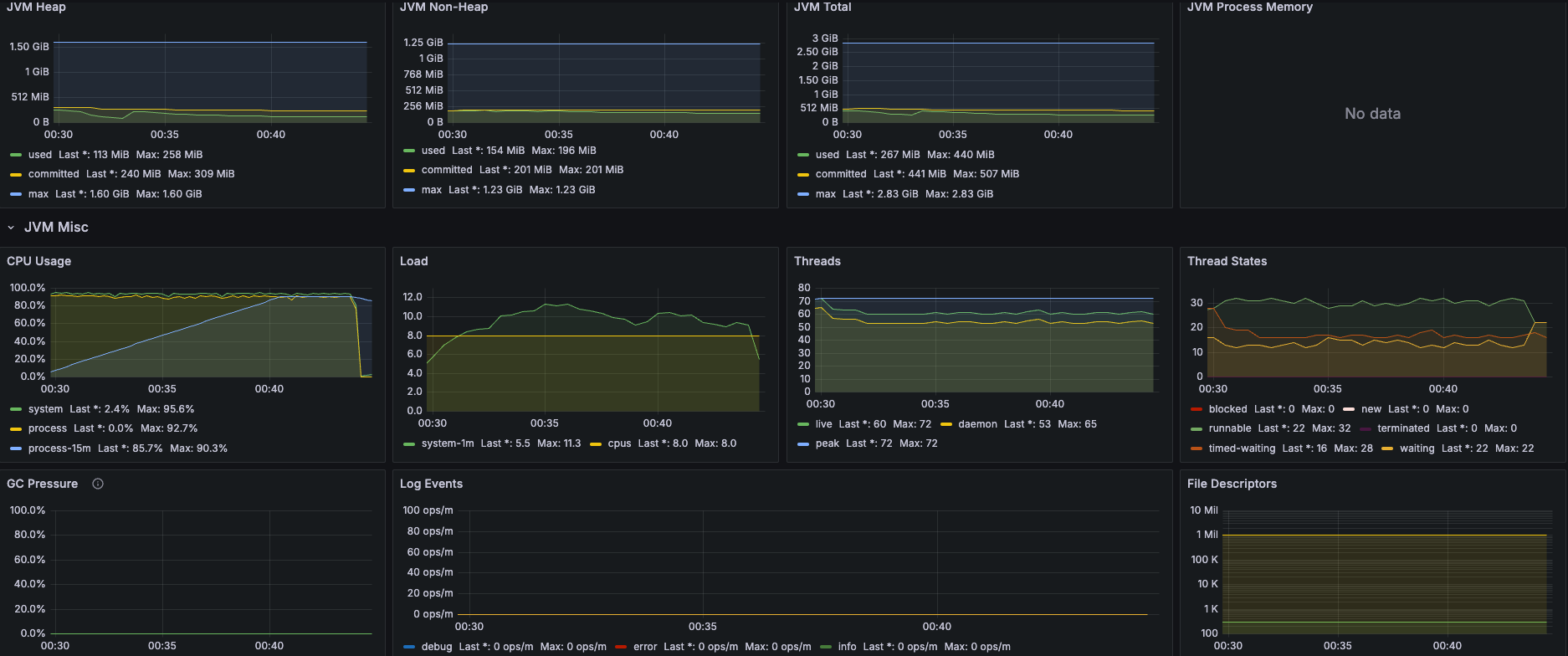
CPU 1코어
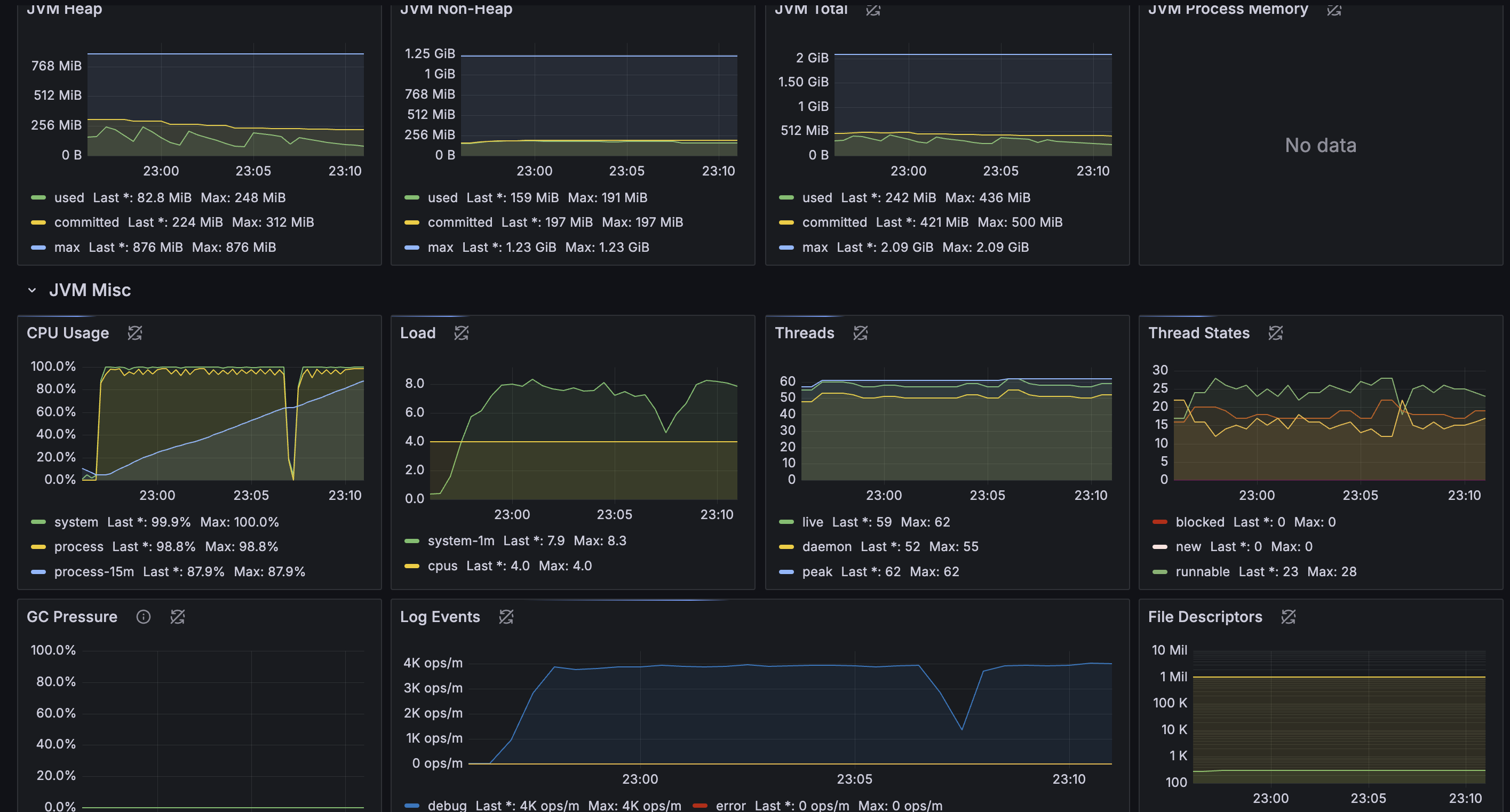
JVM
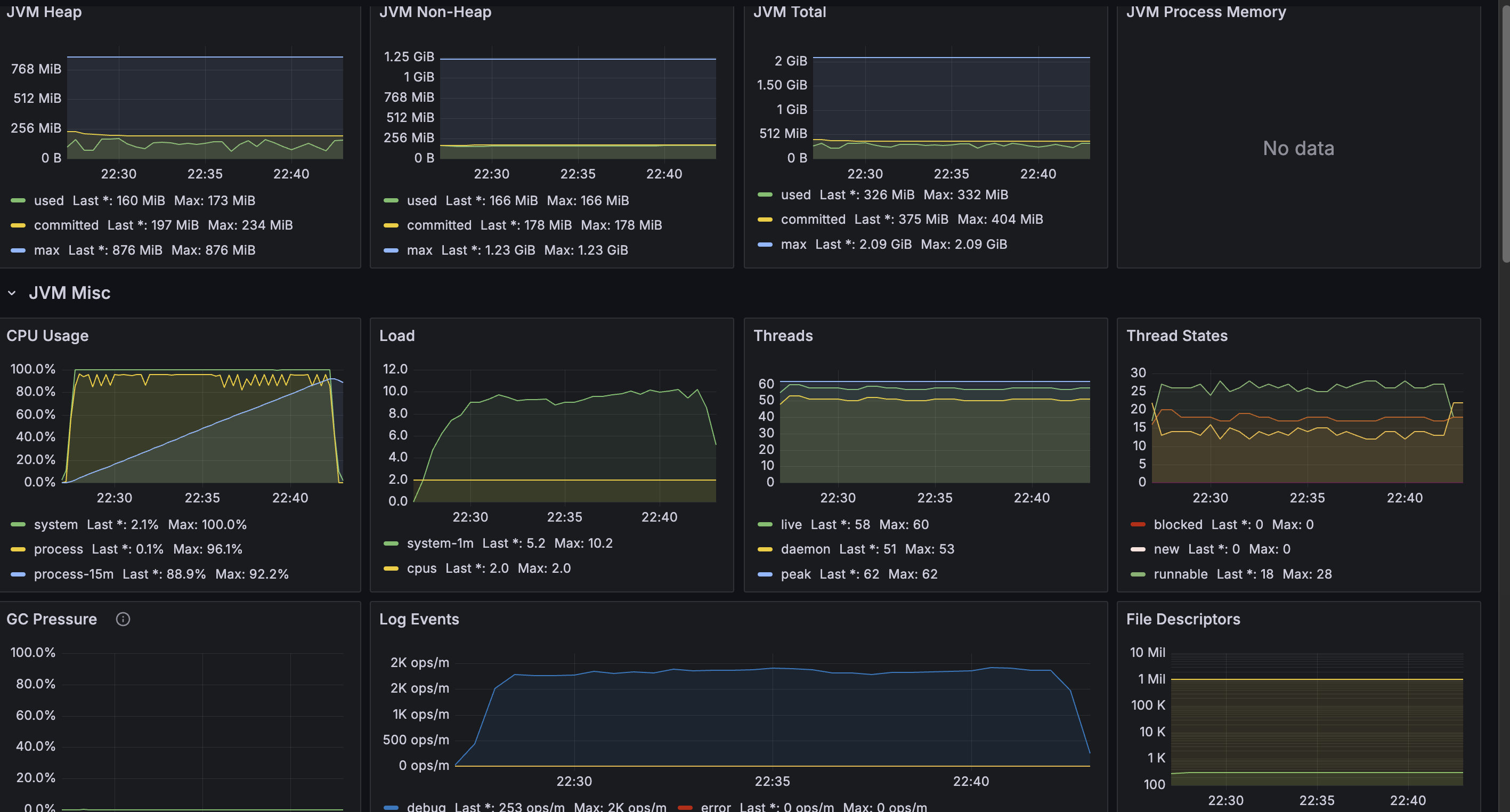
메모리는 평온한데 비해 CPU가 죽여달라고 하고 있다. GC도 거의 평온하고... Thread도 별 일이 없다.
APM
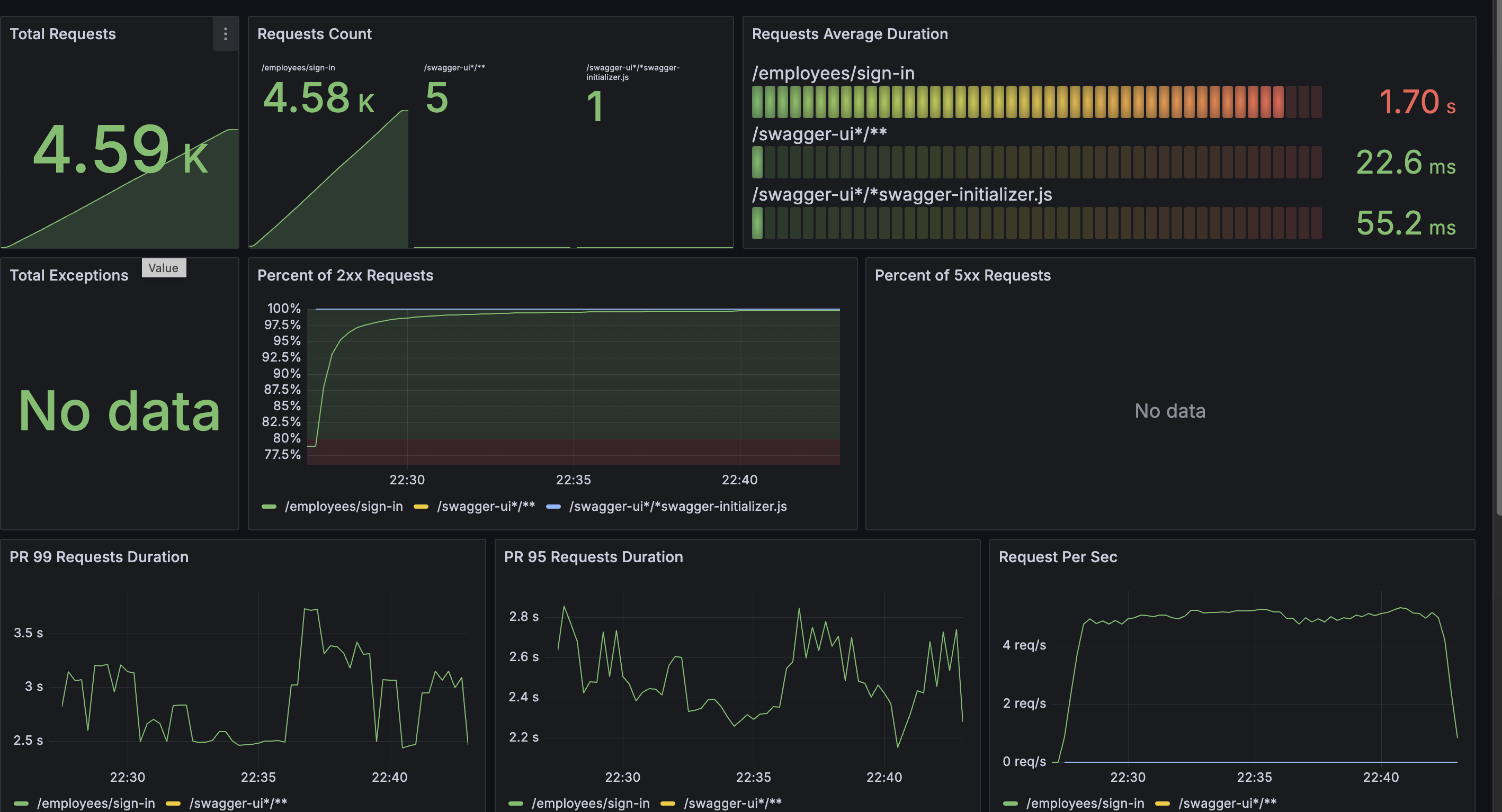
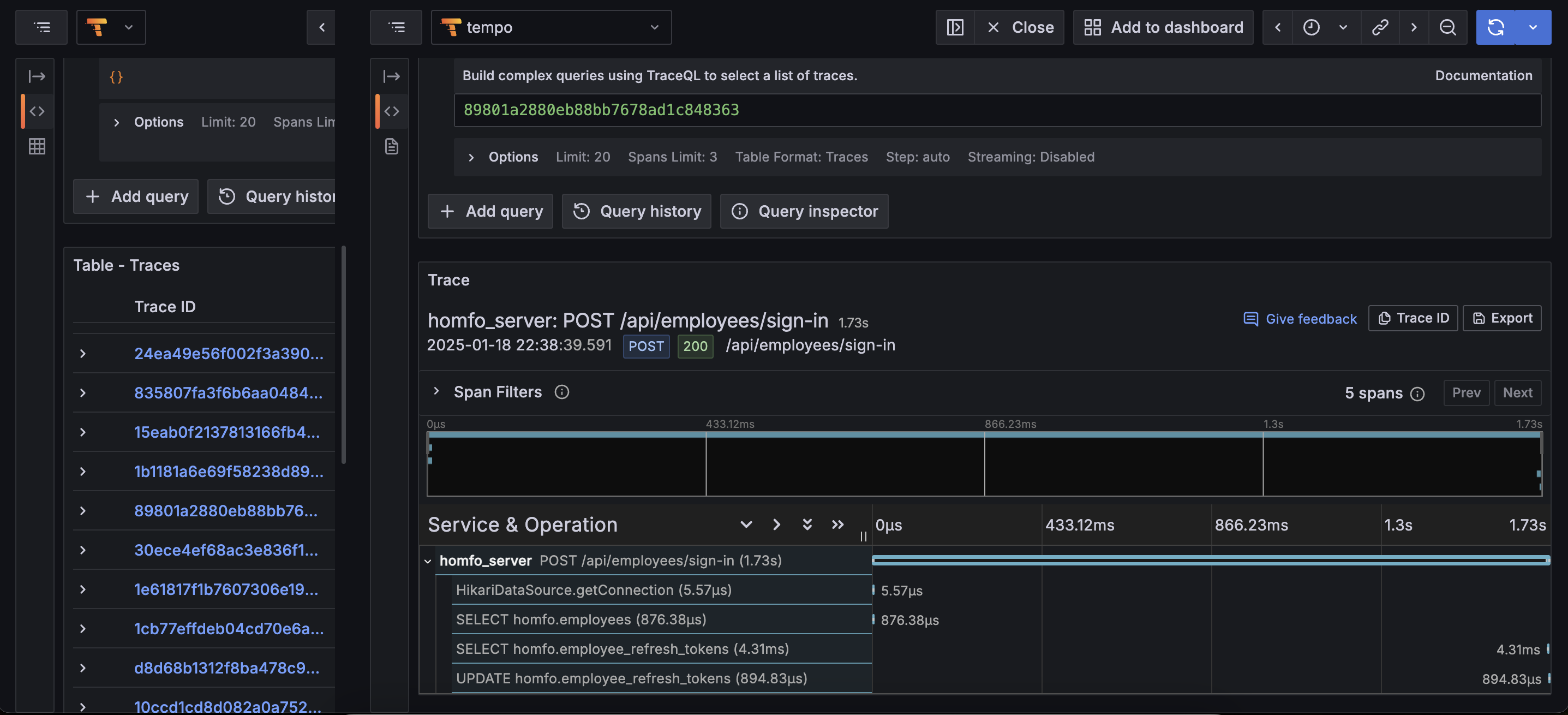
Request 처리 속도가 매우 느리다. 그리고 4RPS 로 찍히는 것으로 보아, 부하를 견디기 어려워하는 것 같다. 의외였던 것은 DB 쪽은 굉장히 빨랐다는 것이다.
K6
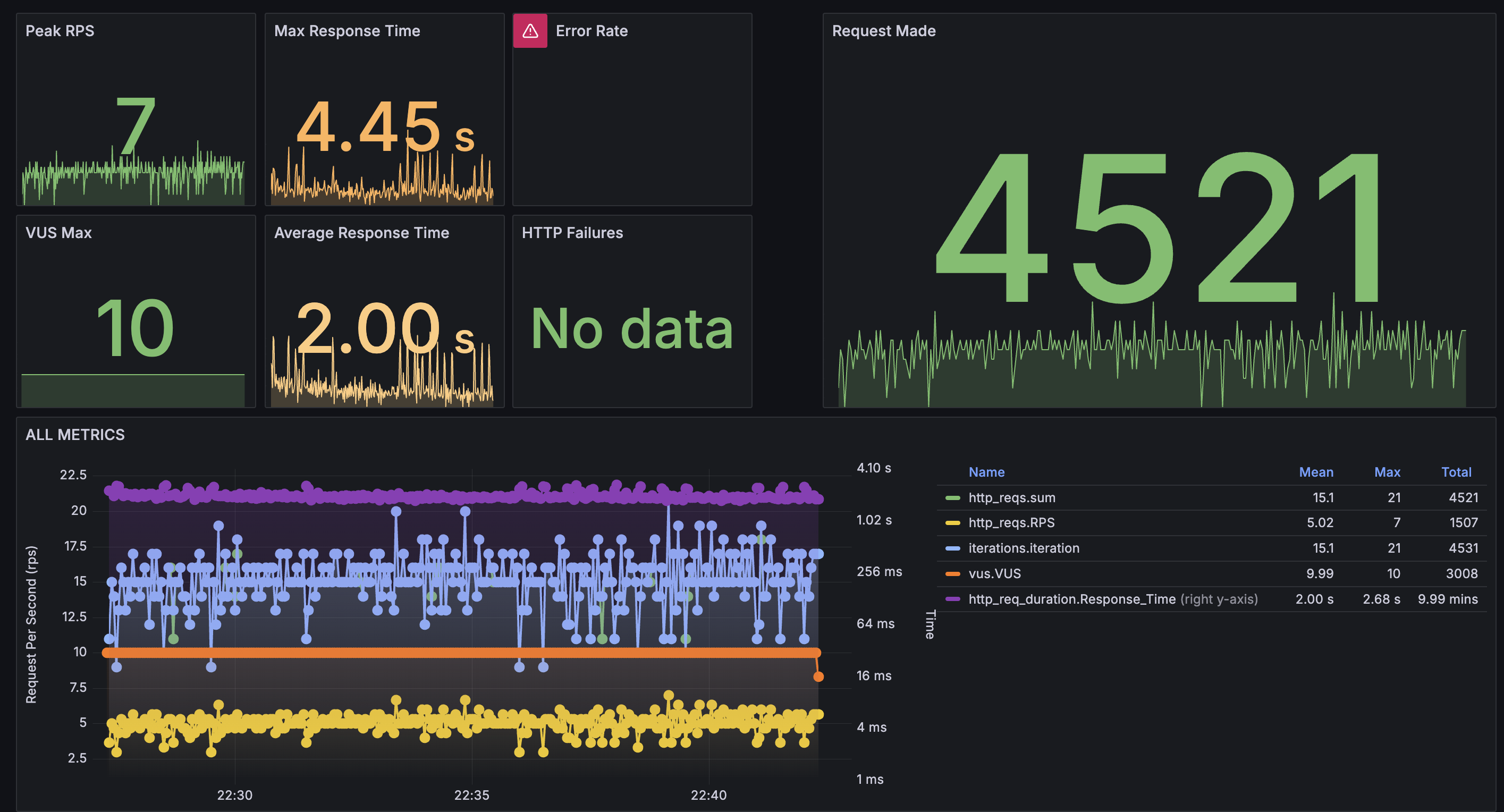
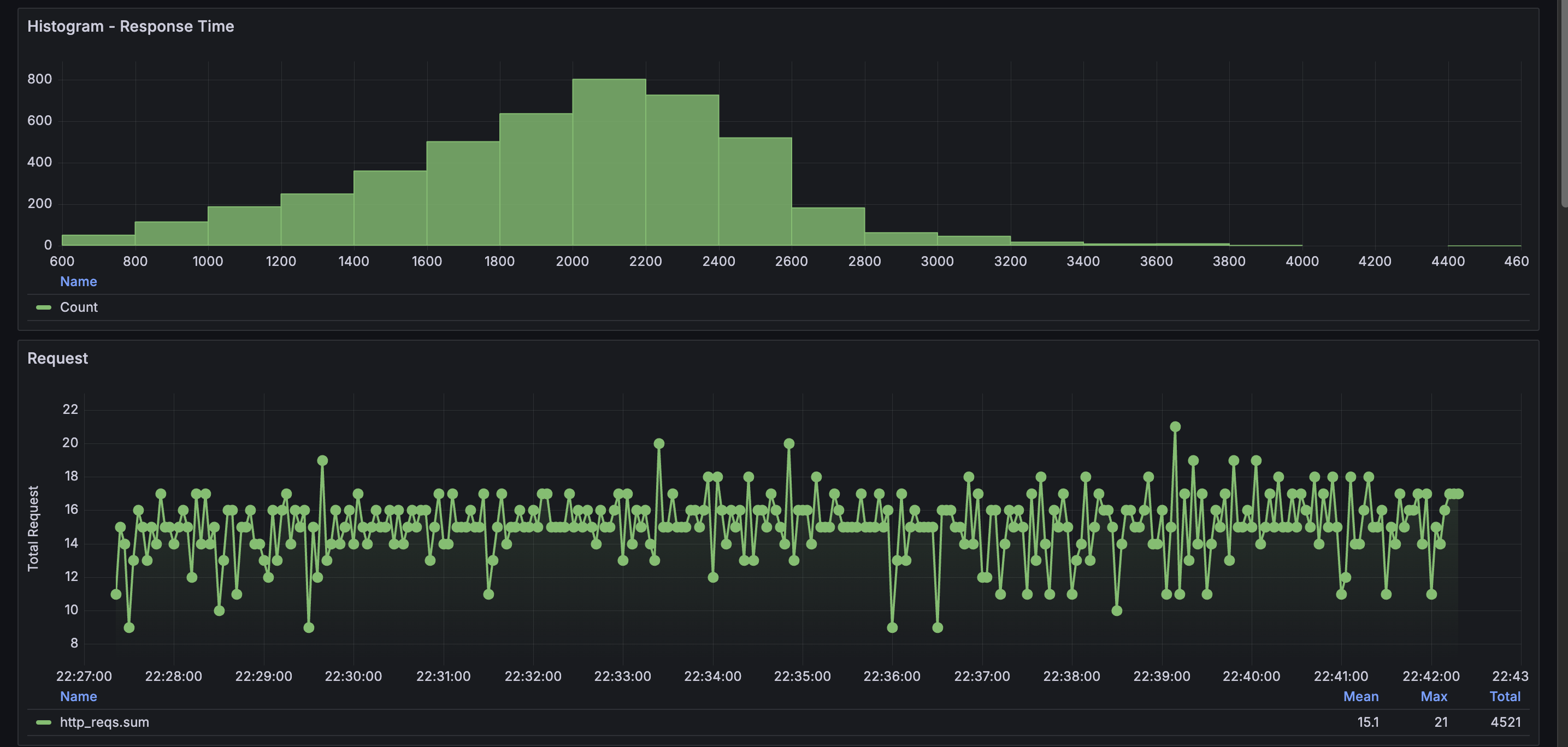
히스토그램으로 볼때는 1초 미만 응답이 굉장히 적다는 걸 알게 됐다. 힝...
CPU 2코어
JVM
2코어로 늘려보아도 여전히 CPU 부하만 심하다. 특이한 것은 중간에 0퍼까지 CPU 사용량이 떨어지는 케이스가 있었다. Full GC라고 하기엔 메모리가 너무 평온해서... CPU throttling이나 Tomcat request throttling를 의심하고 있는데, 확신을 얻으려면 Thread dump를 떠야하나..?
APM
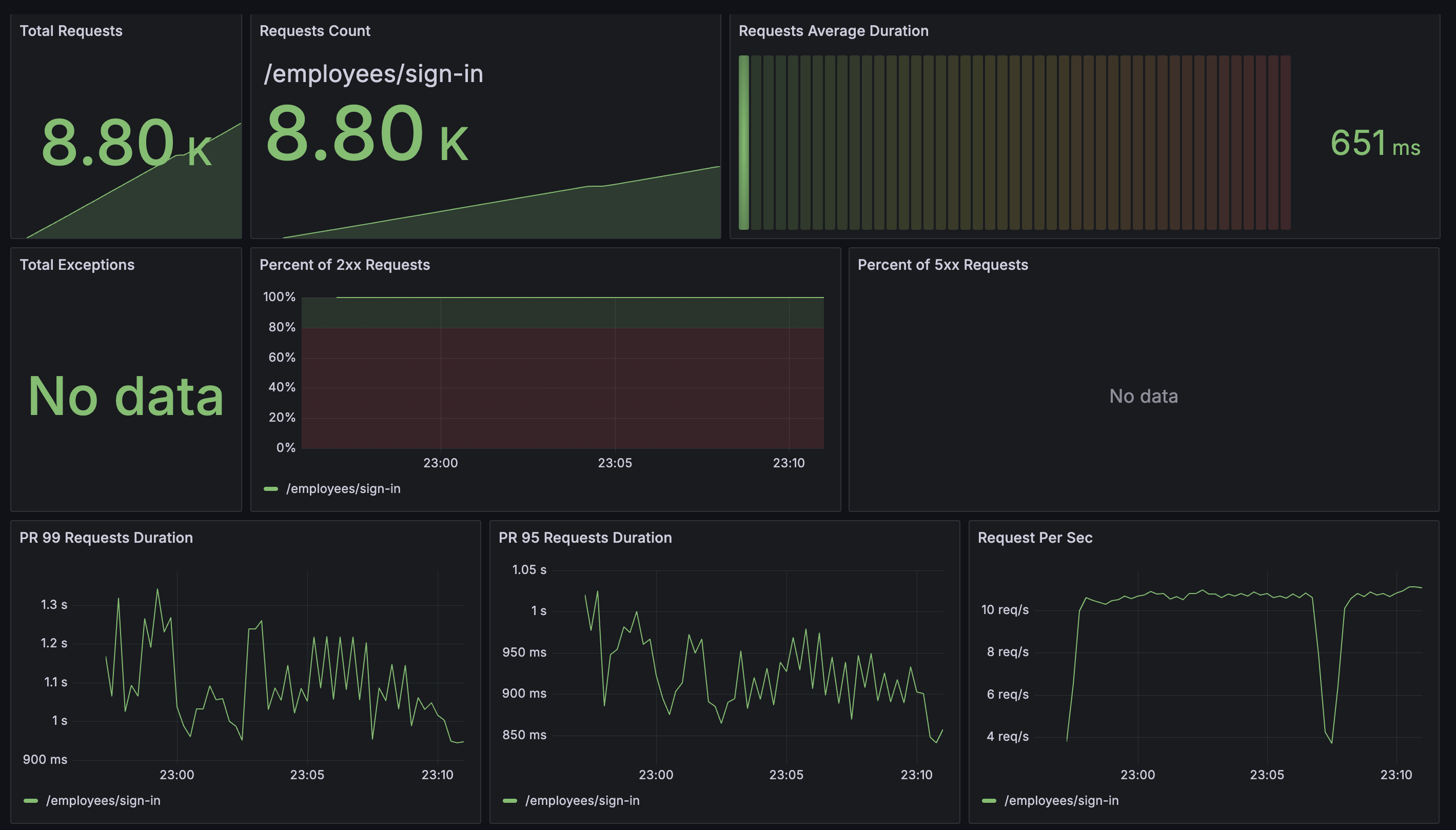
기존보다 요청량이 2배 가까이 늘었다. 그럼에도 불구하고 PR99 PR95 상으로는 요청 처리 속도가 많이 개선되었다. RPS도 2배 가까이 늘었다. 역시 돈은 좋다.
K6
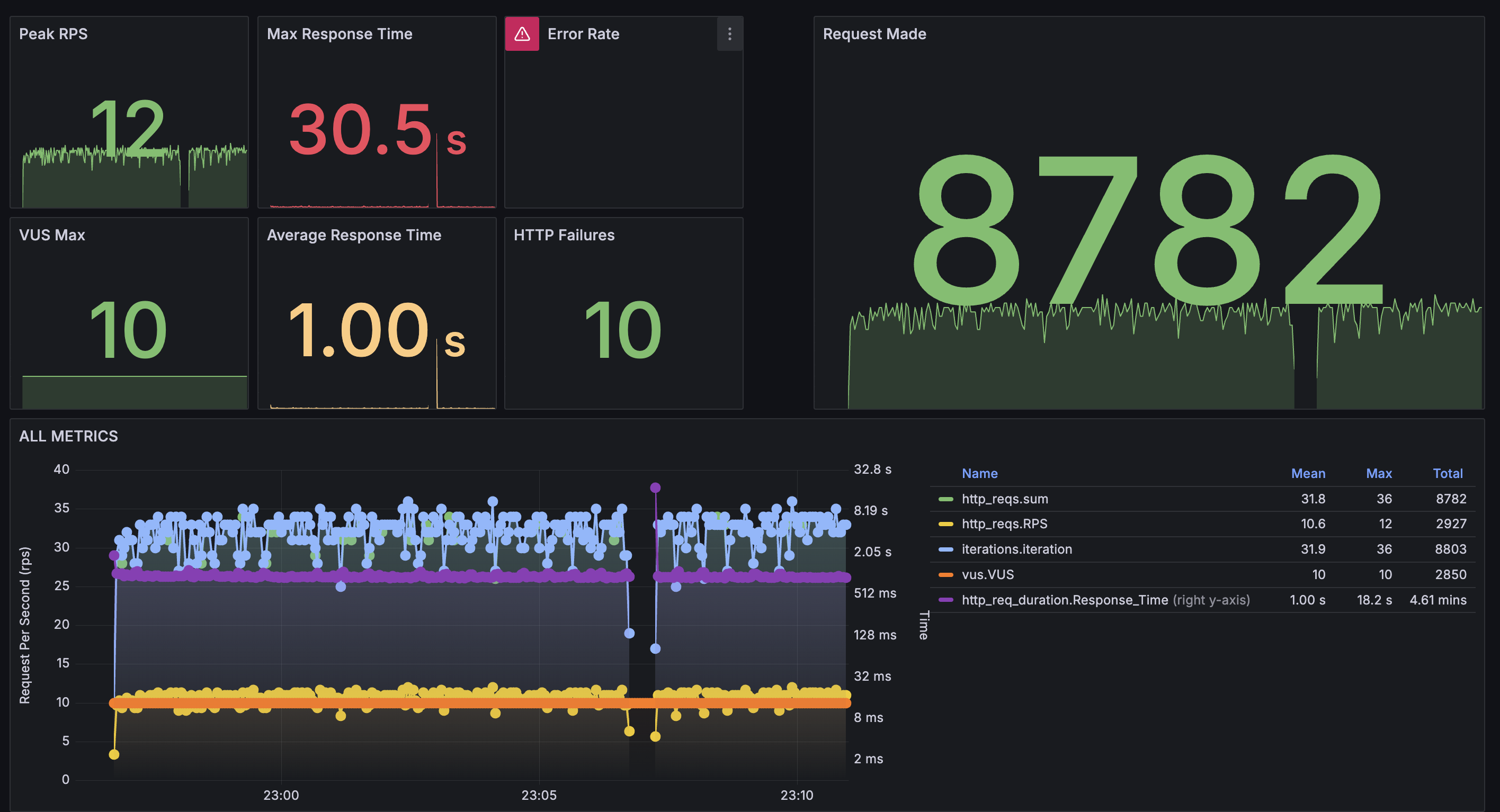
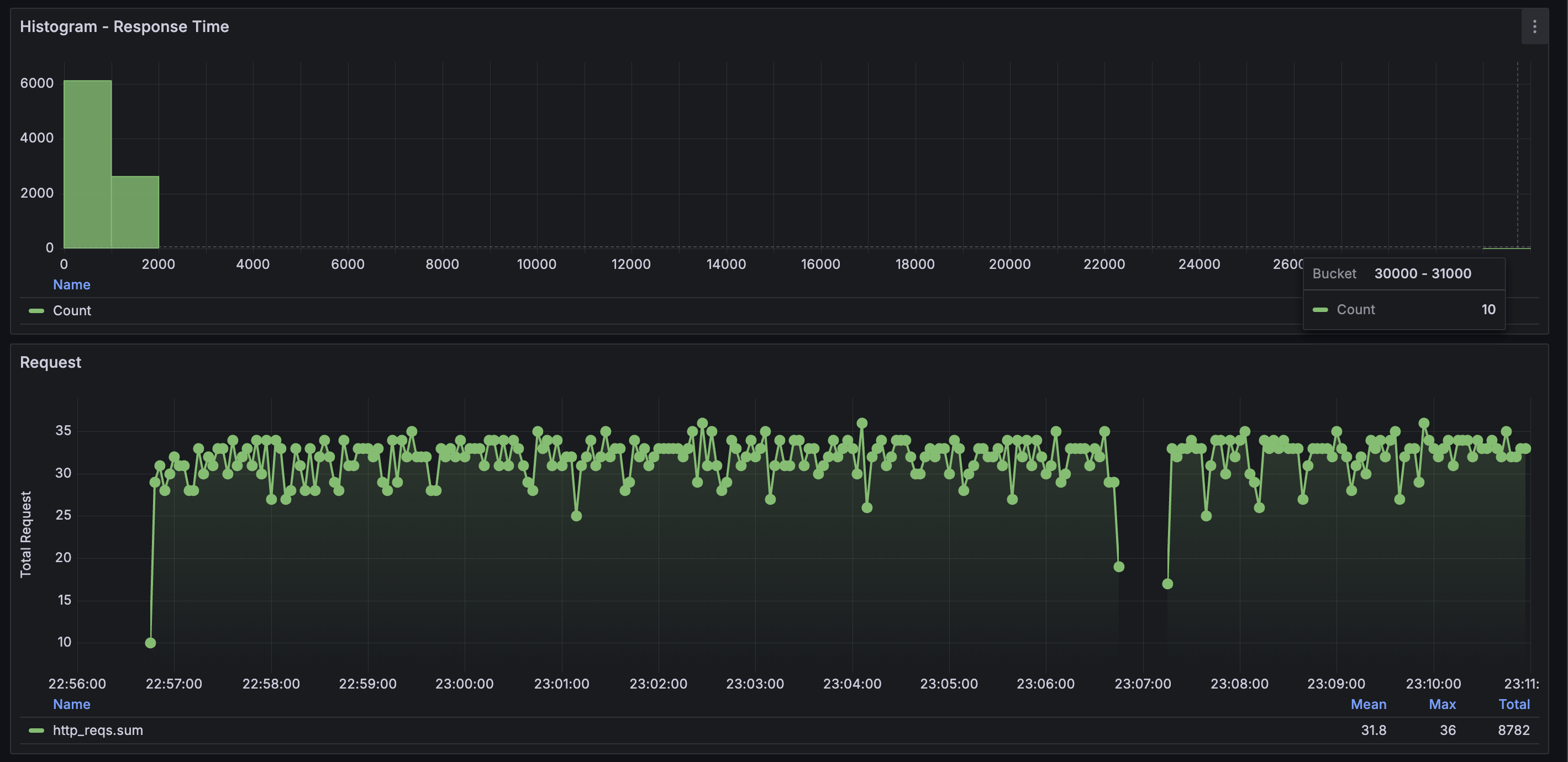
마찬가지로 평균 응답 시간은 개선되었는데, throttling이 발생한 시점에 timeout이 발생하였다.
CPU 3코어
JVM
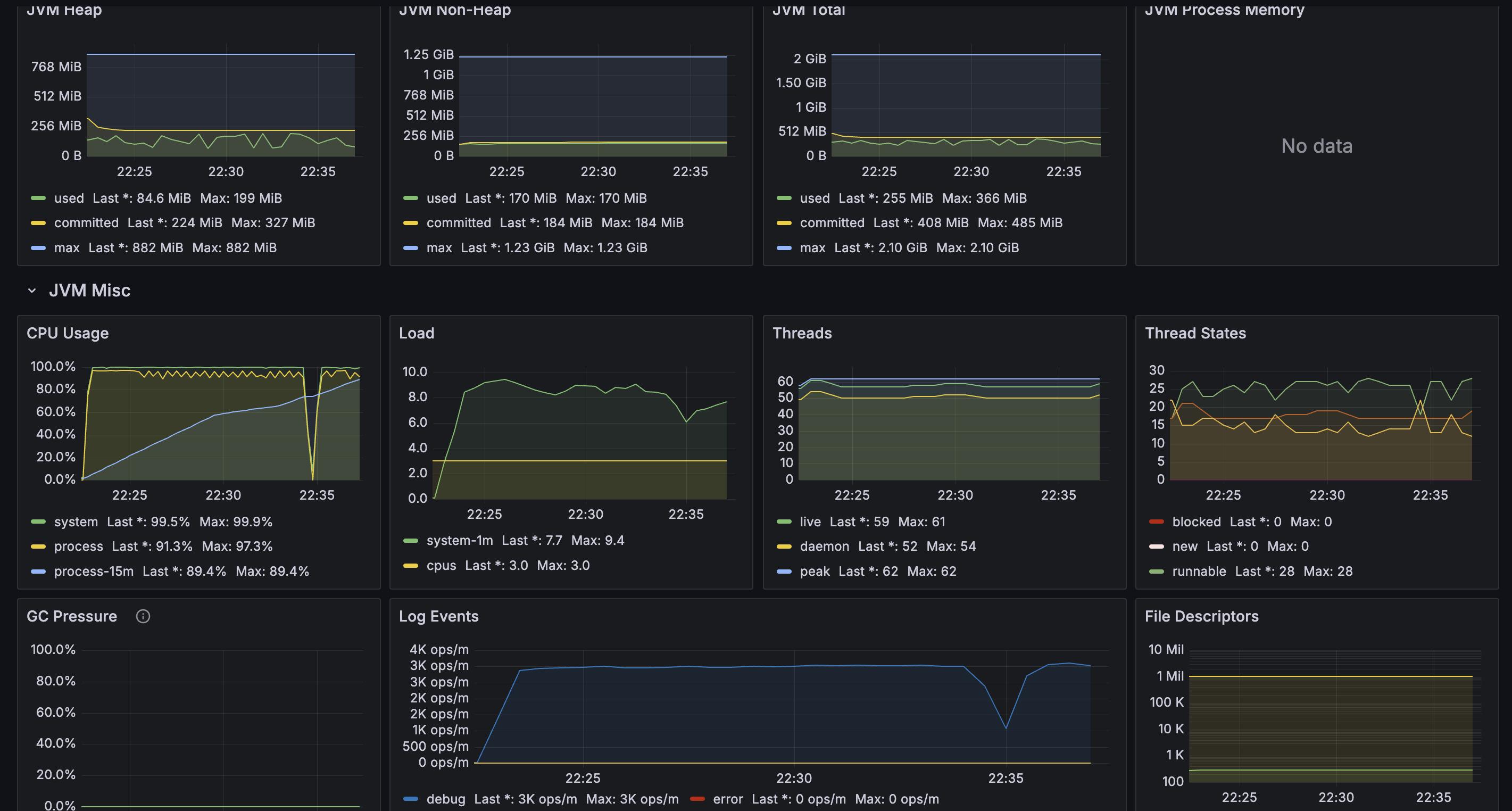
3코어로 늘려보아도 여전히 CPU 부하만 심하다. 로그인 API이다 보니까 암호화 & 복호화가 있어서 그런 듯 하다. 똑같이 throttling이 발생한 것으로 보인다.
APM
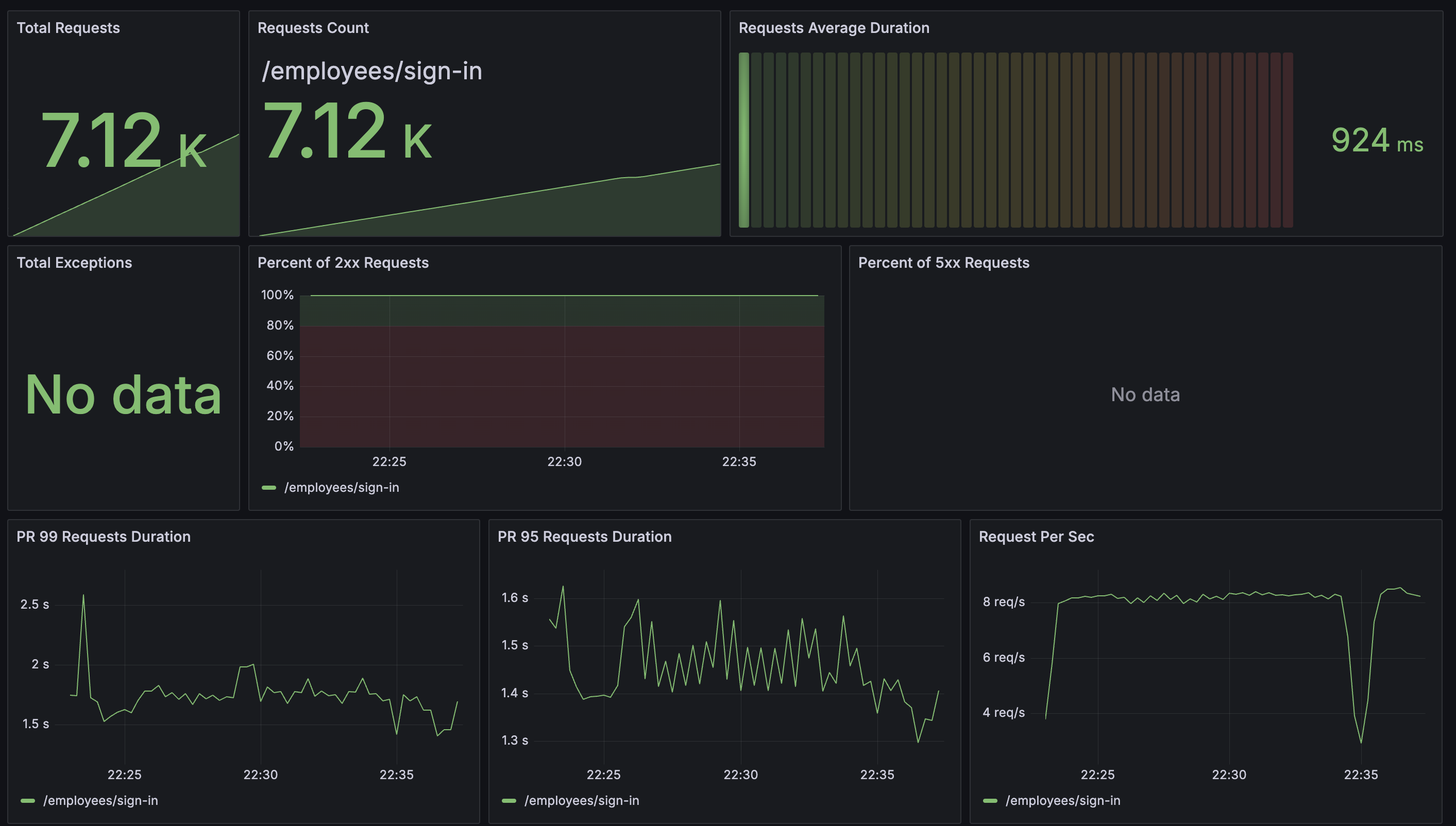
3코어로 늘렸음에도 2코어에 비해 불구하고 처리 속도는 개선되지 않았다.
K6
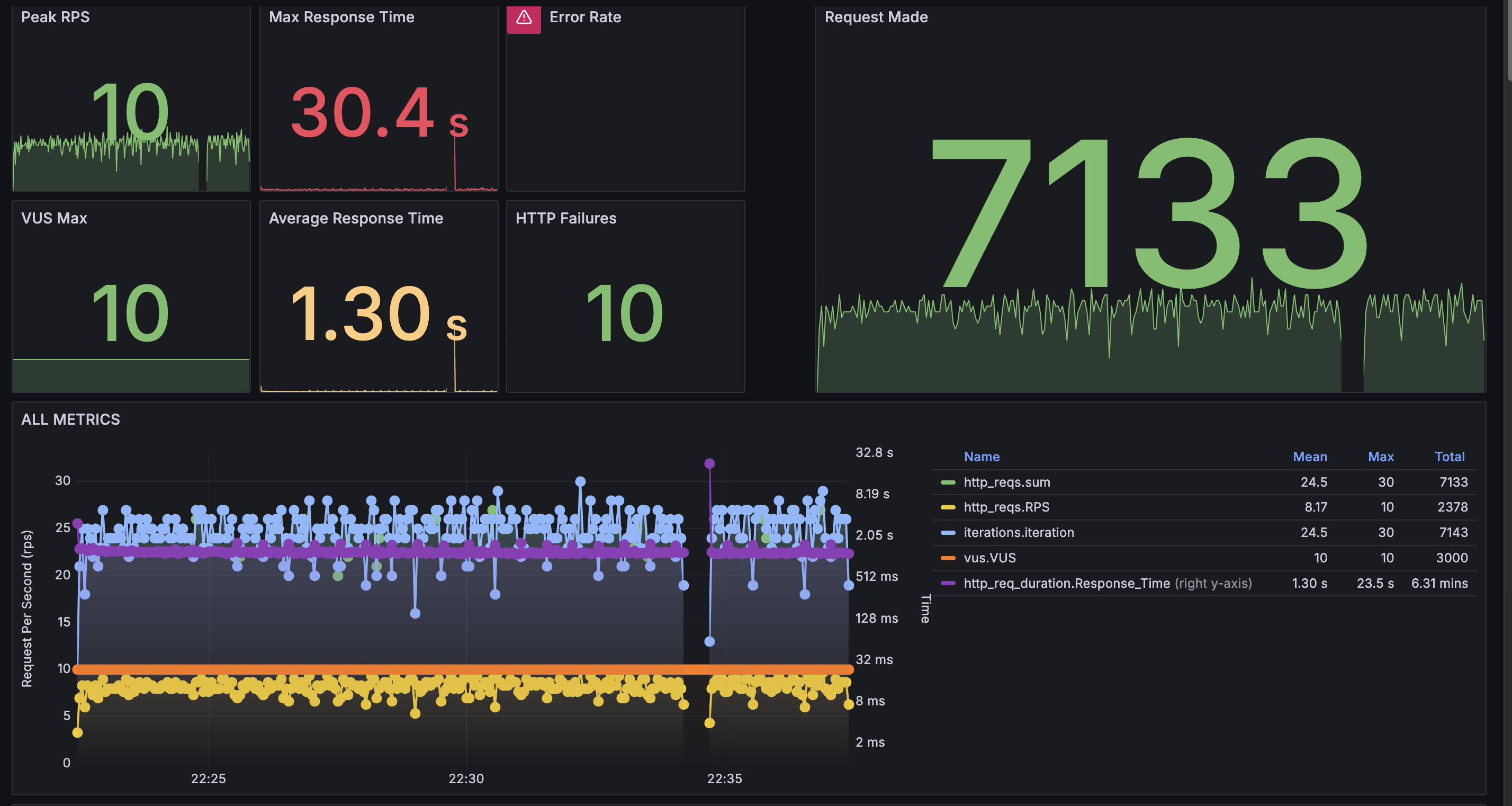
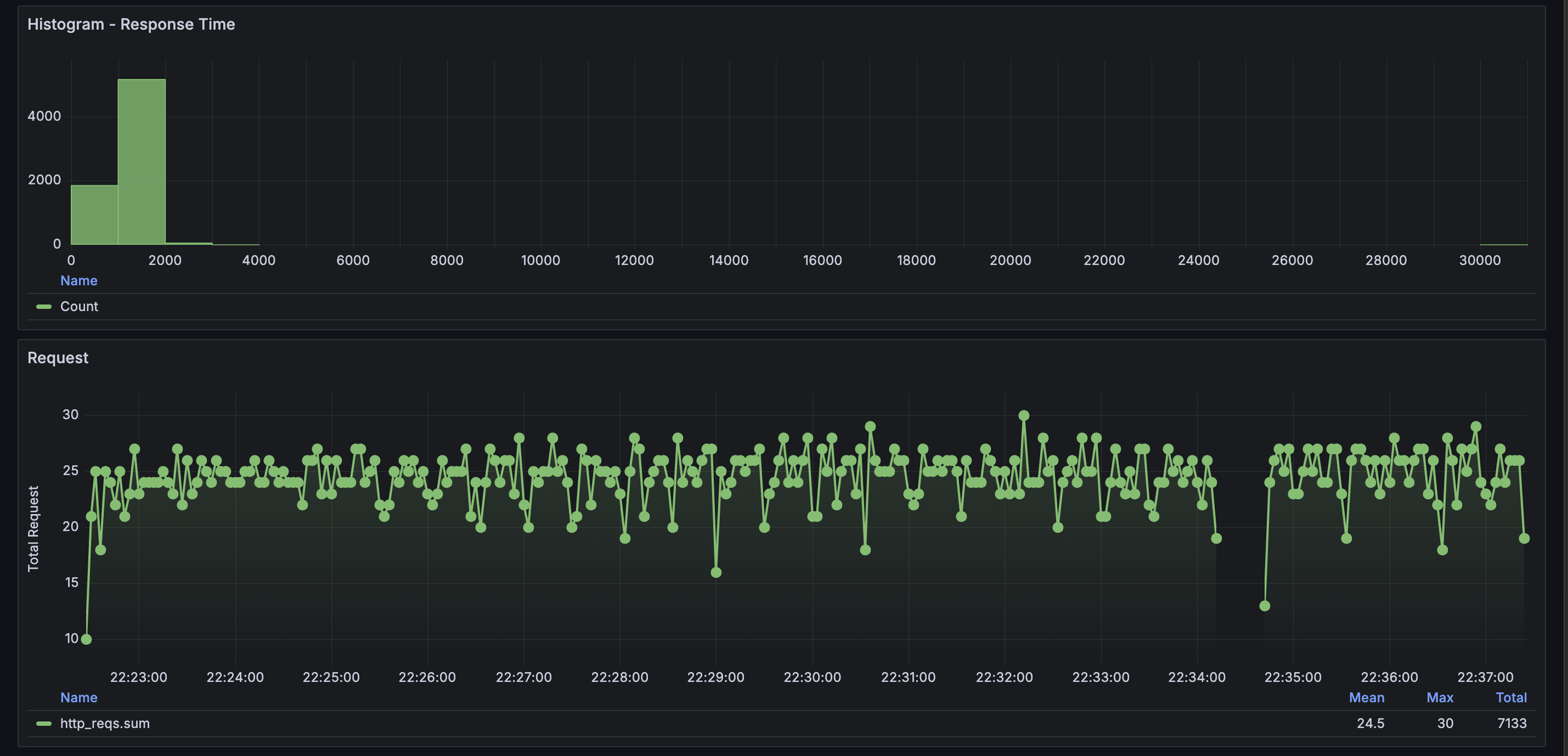
2코어랑 비슷하게 처리하고 있지만 throttling으로 인해 connection time out이 발생한 듯하다.
에라이 8코어
CPU 작업이 너무 많은 것 같아서 뭔가 덤프를 떠보고 싶었다. async-profiler를 써보려고 했는데 아무리 해도 pod 프로파일링이 안 돼서 실패했다. libasyncProfiler.so를 pod에도 넣어보고, worker node에서 crictl ps나 jps -l로 PID 잡아서 시도도 해봤는데 flamechart.html를 주지 않는다ㅠㅠ 딱히 방법이 잘 생각 안나서 답답한 마음에 확 8코어로 올려봤다.
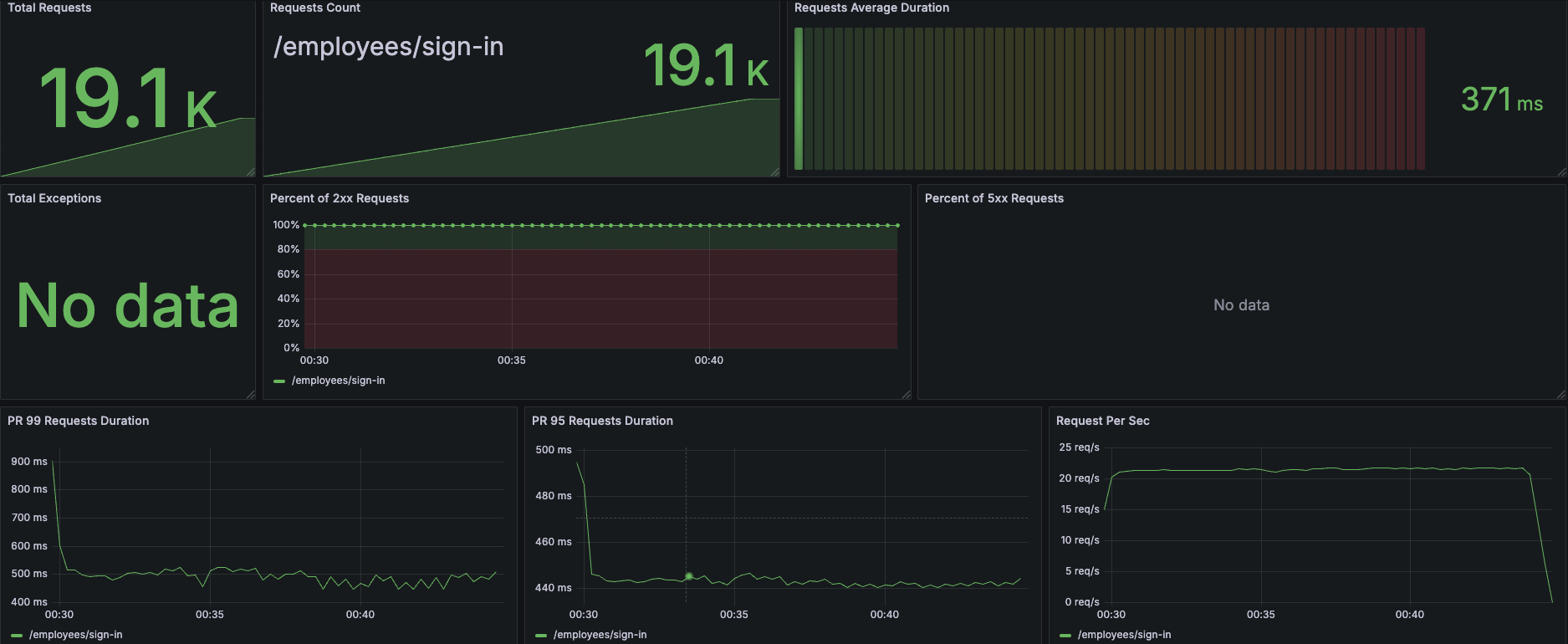
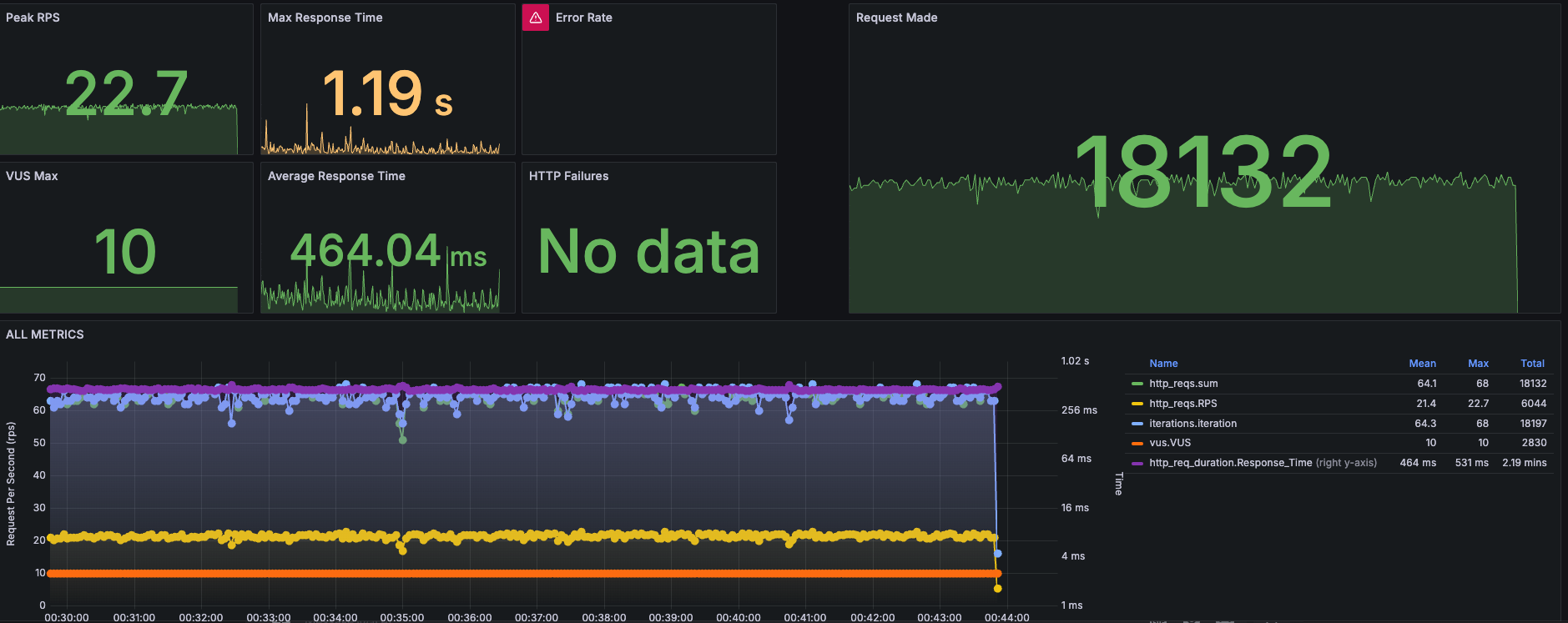
8코어로 올리니까 처리속도가 눈에 띄게 좋아졌다. 생각보다 잘 처리해서 request가 18K가 왔다 ㄷㄷ.. 근데 왜 이런건지 dump를 안 떠보니까 이만큼 모니터링을 구축해도 눈뜬 장님이 된 것 같다. 아쉬운 대로 다른 방법을 찾아보다가, 생각해보니 이상민 님의 "성능의 신" 강의에서 jstack 이야기를 들었던게 떠올랐다. 그래서 적용해보니 아래처럼 눈에 띄는 Thread 들이 있었다.
"http-nio-8080-exec-2" #54 [70] daemon prio=5 os_prio=0 cpu=244252.27ms elapsed=342.46s tid=0x0000ffff7f9626b0 nid=70 runnable [0x0000fffee5e0b000]
java.lang.Thread.State: RUNNABLE
at org.springframework.security.crypto.bcrypt.BCrypt.key(BCrypt.java:437)
at org.springframework.security.crypto.bcrypt.BCrypt.crypt_raw(BCrypt.java:559)
at org.springframework.security.crypto.bcrypt.BCrypt.hashpw(BCrypt.java:656)
at org.springframework.security.crypto.bcrypt.BCrypt.hashpw(BCrypt.java:603)
at org.springframework.security.crypto.bcrypt.BCrypt.hashpw(BCrypt.java:593)
at org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder.encode(BCryptPasswordEncoder.java:110)
at com.homfo.auth.domain.entity.DefaultHashStrategy.encrypt(DefaultHashStrategy.java:13)
at com.homfo.auth.domain.entity.Token.hash(Token.java:20)
at com.homfo.employee.domain.entity.EmployeeAuthToken.<init>(EmployeeAuthToken.java:55)
at com.homfo.employee.domain.entity.EmployeeAuthToken$TokenStrategyBuilder.build(EmployeeAuthToken.java:41)
at com.homfo.employee.domain.aggregate.EmployeeTokenAggregateImpl.createNewToken(EmployeeTokenAggregateImpl.java:49)
at com.homfo.employee.domain.service.EmployeeService.signIn(EmployeeService.java:141)
at아이고 길다 확인해보니 로그인할 때 Bcrypt 암호화를 확인하는게 있는데, 이 작업이 CPU를 엄청 쓰는 듯 했다. elapsed=342.46s 인데 cpu=244252.27ms 인 걸 보면 해당 Thread는 71.32%의 시간을 CPU에서 보냈다는 뜻이 된다. 찾아보니 암호화 강도를 11로 해놨는데 이거 때문에 오래 걸린 듯 하다. 강도를 낮춰봐야겠다.
암호화 강도 낮추기
일단 Dump로 대략적인 원인을 예상할 수 있으니 암호화 강도를 낮춰보자. 관리자는 트래픽이 별로 안 많을 것 같아서 암호화 강도를 강하게 한건데, 11만으로도 이런 성능이면 일반 유저 상대로는 더 낮춰야할 것 같다. 그래서 절반 5로 테스트 해보자.

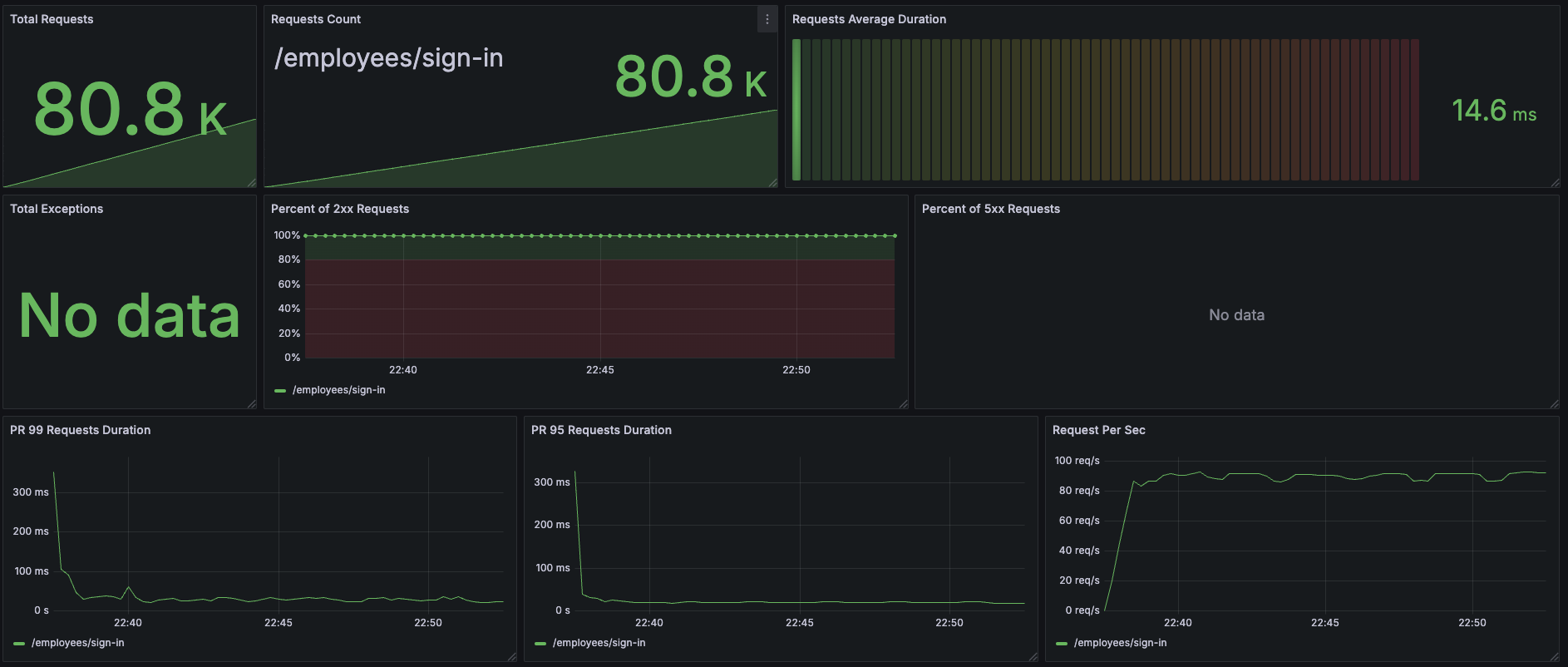
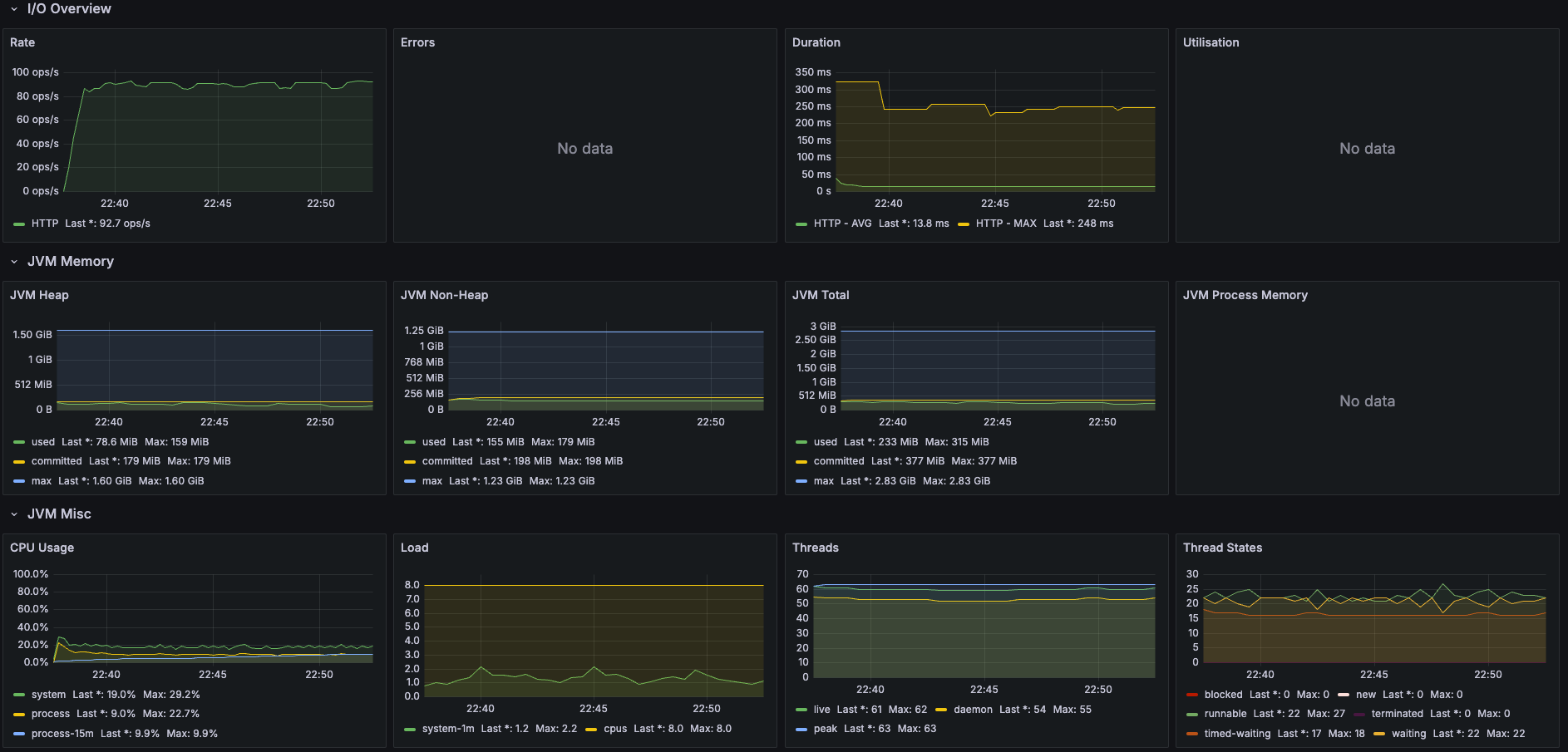
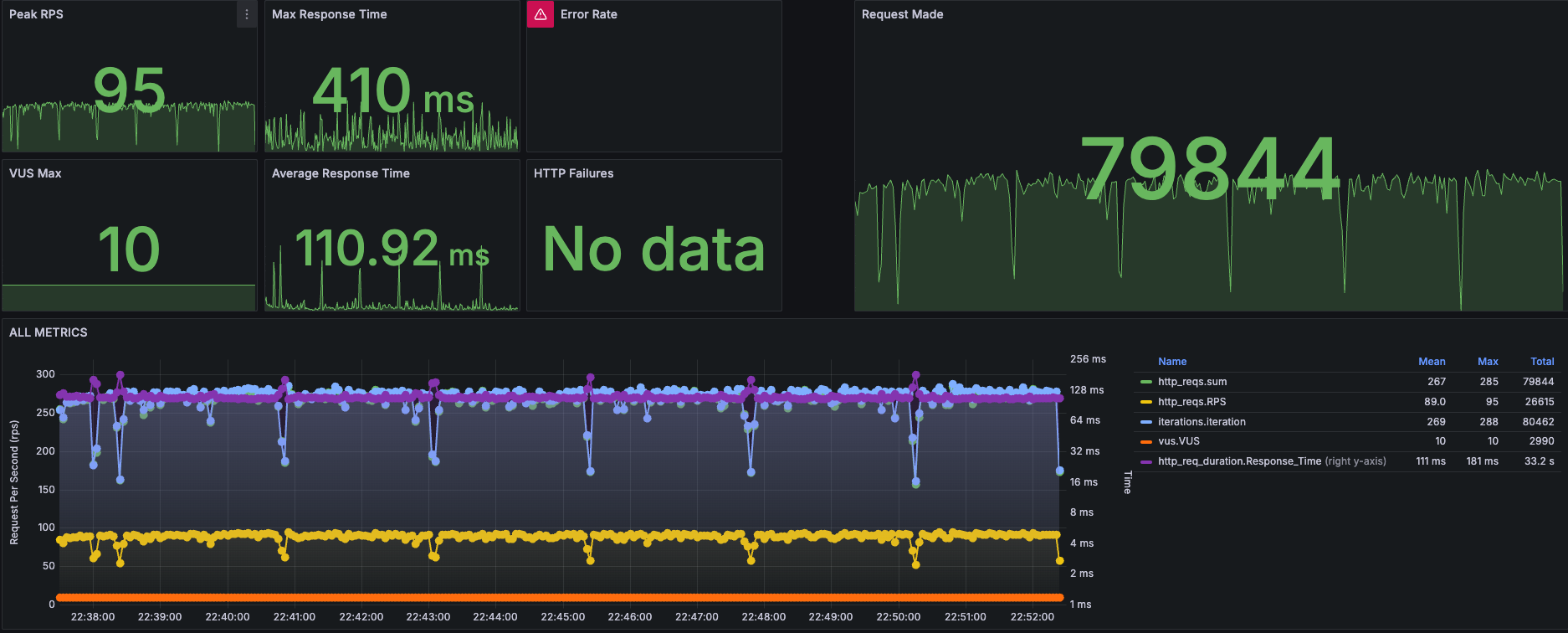
| 지표 | 이전 (암호화 강도 11) | 이후 (암호화 강도 5) | 변화율 (%) |
|---|---|---|---|
| 총 요청 수 | 19.1k | 80.8k | +323.04% |
| 평균 응답 시간 | 371ms | 14.6ms | -96.07% |
| 99% 응답 시간 | 924ms | 300ms | -67.54% |
| CPU 사용률 (평균) | 95.6% | 29.2% | -69.46% |
| 최대 처리량 (RPS) | 22.7 RPS | 95 RPS | +318.06% |
| JVM Heap 사용량 (평균) | 267MiB | 78.6MiB | -70.56% |
| 에러율 | 0% | 0% | 변화 없음 |
와... 암호화 강도가 이렇게 중요한 줄 몰랐다. CPU를 많이 쓴다는 정도만 알았는데, 이렇게 숫자로 보니까 엄청나게 체감된다. 숫자 하나 수정으로 100 RPS를 견디고도 CPU가 남아돌 줄이야...
Connection Timeout 측정
암호화 강도 5로 설정해놓고 다시 1코어로 돌아가서 측정해보니 Peak CPU 사용량이 85.6%, 평균 66.28%로 눈에 띄게 감소했다. 그럼에도 Timeout은 발생하고 있어서 처리 시간과 요청이 쌓이는 속도를 가지고 타임라인을 짜보면 해석이 가능할까 했다. 일단 tomcat max_thread는 400이고, accept_count는 200, max_connections는 10K이다.


15분 동안 총 47.6K의 요청이 발생했고, 1개의 리퀘스트를 처리하는데 100 ~ 250ms가 소요되고 있다. 한편 부하 생성기에서는 초당 평균 54.8개의 요청을 만들어내고 있다. 8초면에 max_thread에 도달하고, 10초면 accept_count에 도달한다. 3~4분 정도 지나면 max_connections에 도달한다. 초당 4 ~ 10개의 요청을 처리하니까 max_connections 도달 시간이 조금씩 뒤로 밀리다가 결국 연결조차 못하고, K6 대시보드에서도 해당 구간의 그래프가 빈 것으로 보인다. 30초 타임아웃이 발생한 건 accept_count 에 들어가 대기 큐에 있긴 하지만, 처리량이 빠르지 않아 타임아웃이 발생한 듯 하다.
이정도 쓰레드 개수면 context_switching이 엄청 발생할 것 같아서 이를 측정해보았다.
[root@ ~]# sudo perf stat -e context-switches -a sleep 900
Performance counter stats for 'system wide':
2,466,168 context-switches
900.005820079 seconds time elapsed부하테스트 동안 2.46M 번의 context switching이 발생했고, 초당 평균 2.740K가 발생했다. 추가로 vmstat으로 확인해보니 부하가 걸리는 동안, 1초에 1,883 ~ 3,364 번 context switching이 발생하고 있는 걸 확인할 수 있다. (cs 항목)
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 431316 4 2545016 0 0 0 2 1930 2604 42 15 43 0 0
0 0 0 428760 4 2545084 0 0 0 484 2136 3364 40 17 44 0 0
0 0 0 428876 4 2545092 0 0 0 0 2042 2693 46 14 40 0 0
6 0 0 428876 4 2545172 0 0 0 1136 2410 2994 44 20 36 0 0
2 0 0 424604 4 2545208 0 0 0 0 2191 3323 50 19 31 0 0
3 0 0 424364 4 2545248 0 0 0 0 2160 3047 39 15 47 0 0
1 0 0 423860 4 2545252 0 0 0 0 1988 3027 45 17 38 0 0
1 0 0 423860 4 2545320 0 0 0 0 2079 2993 47 12 41 0 0
1 0 0 423860 4 2545324 0 0 0 0 2044 2655 37 17 46 0 0
1 0 0 423860 4 2545744 0 0 0 0 1809 2620 51 21 28 0 0
9 0 0 345560 4 2545748 0 0 0 0 1658 2131 73 27 0 0 0
26 0 0 333240 4 2545772 0 0 0 0 1429 1883 90 10 0 0 0
11 0 0 286116 4 2545792 0 0 0 0 1498 2210 82 18 0 0 0
11 0 0 258900 4 2545832 0 0 0 36 1557 2001 82 18 0 0 0
11 0 0 254616 4 2545892 0 0 0 0 2093 3255 59 17 24 0 0
5 0 0 254616 4 2545944 0 0 0 0 2351 3214 47 16 37 0 0
0 0 0 254616 4 2545944 0 0 0 0 2311 3296 49 20 32 0 0
1 0 0 254616 4 2546028 0 0 0 0 2267 3185 40 16 43 0 0
0 0 0 254616 4 2546068 0 0 0 8 2011 2693 39 12 48 0 0
6 0 0 254616 4 2546152 0 0 0 12 2007 2632 41 14 45 0 0
3 0 0 254616 4 2546160 0 0 0 0 1984 2602 38 15 48 0 0지금까지 계속 CPU를 과도하게 사용하고, memory는 너무나도 평온했으니 오히려 max_thread를 줄이고 accept_count & max_connections를 늘리는게 맞는거 같다. 어차피 request 연결 후 대기하는 건 TCP 소켓 버퍼를 사용하는거라 메모리 사용량이 늘지, CPU 사용량이 늘진 않을거 같았다.
[root@ ~]# getconf CLK_TCK
100
[root@ ~]# sysctl -a | grep sched
kernel.sched_cfs_bandwidth_slice_us = 5000 # 각 태스크가 CPU를 사용할 수 있는 기본 시간 슬라이스, 마이크로초 단위
kernel.sched_child_runs_first = 0
kernel.sched_deadline_period_max_us = 4194304
kernel.sched_deadline_period_min_us = 100
kernel.sched_rr_timeslice_ms = 100 # 태스크가 CPU에서 실행될 수 있는 시간 슬라이스, 밀리초 단위
kernel.sched_rt_period_us = 1000000
kernel.sched_rt_runtime_us = 950000 # 실시간 태스크가 사용 가능한 CPU 실행 시간, 마이크로초 단위
kernel.sched_schedstats = 0일단 서버 VM은 초당 100번의 CPU 클럭을 가진다. 그리고 태스크가 CPU에서 실행될 수 있는 시간은 100ms, 실시간성이면 950ms 이다. 현재 요청을 처리하는데 100ms ~ 250ms이니까, context-switching 회수만 줄이면 timeslice를 좀 더 안정적으로 사용할 수 있지 않을까 싶다. 근데 어차피 1코어라... 쓰레드가 몇 개든 감당 안 될 것 같다.
Dump의 중요함
APM 만 구축해놓으면 정말 많은 걸 확인하고 개선할 수 있을 줄 알았는데, 정작 root cause는 dump가 필요하다는 것을 정말 많이 느꼈다. 1차 테스트 때 모니터링 + APM 만으로는 CPU 부하 원인이 뭔지 찾는데 많이 헤멨지만, thread dump 하나만으로 이렇게 쉽게 개선할 수 있을 줄은 꿈에도 몰랐다. dump의 중요성을 정말 많이 느꼈다.
다만 라이브 서비스에서 암호화 강도를 바꾸면, 기존 데이터와의 호환이 제대로 이뤄지나 걱정됐다. 한 번 설정된 암호화 강도를 바꿀 수 없다면 이런 종류의 최적화는 어렵지 않을까 했다. 그래서 간단하게 확인해보니 호환이 됐다.
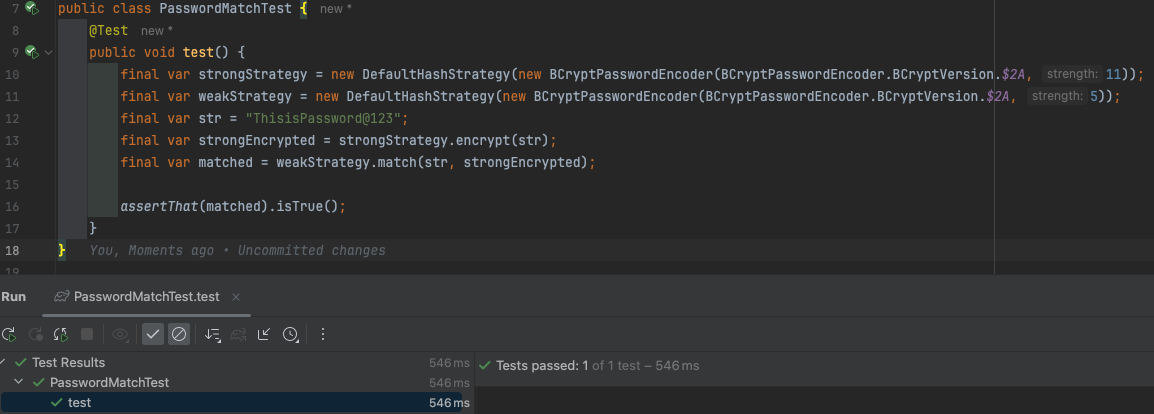
근데 BCrypt 알고리즘을 확인해보니까 해시 강도 정보는 해시 값에 포함되어 있기에, match() 함수를 쓸 때는 설정된 strength랑 상관 없이 해시 값의 해시 강도 정보를 사용한다. 따라서 초기 설정값이 굉장히 중요한 듯 했다. 다행히도 아래처럼 하면 강도를 바꾸면서 마이그레이션을 진행할 수 있다.
public class HashMigrationService {
private final BCryptPasswordEncoder weakEncoder = new BCryptPasswordEncoder(BCryptPasswordEncoder.BCryptVersion.$2A, 5);
private final BCryptPasswordEncoder strongEncoder = new BCryptPasswordEncoder(BCryptPasswordEncoder.BCryptVersion.$2A, 11);
// 기존 해시 검증 및 마이그레이션
public boolean verifyAndMigrate(String rawPassword, String storedHash, Consumer<String> updateHashCallback) {
if (strongEncoder.matches(rawPassword, storedHash)) { // 1. 기존 강한 해시로 검증
String newHash = weakEncoder.encode(rawPassword); // 2. 약한 해시로 재생성
updateHashCallback.accept(newHash); // 3. 새로운 해시를 저장
return true; // 검증 성공
}
return false; // 검증 실패
}
}got the following result on Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz:
Rounds:4 | Time: 0.0016 s
Rounds:5 | Time: 0.0029 s
Rounds:6 | Time: 0.0060 s
Rounds:7 | Time: 0.0115 s
Rounds:8 | Time: 0.0232 s
Rounds:9 | Time: 0.0459 s
Rounds:10 | Time: 0.0907 s /* Good enough */
Rounds:11 | Time: 0.1834 s /* Worth considering */
Rounds:12 | Time: 0.3563 s /* >250ms as discussed in comments */
Rounds:13 | Time: 0.7215 s
Rounds:14 | Time: 1.4437 s /* for critical systems and superuser passwords */
Rounds:15 | Time: 2.9140 s
Rounds:16 | Time: 5.8405 sReference: How many rounds is the recommended for bcrypt password hasing?
Bcrypt 지표를 확인해보면 Roun 5는 2.9ms가 소요되는데, 위 벤치마크 CPU는 8코어에 Hyper-thread 이므로 12 ~ 14코어 정도 성능이 나올 것이라 예측된다. 이걸 바탕으로 적절한 강도로 변경해나가는게 좋은 것 같다.
숫자 하나만으로 개선하는 경험을 해보면서, root cause를 찾는게 얼마나 중요한지 경험했다. 이런 단순한 개선만으로 ROI를 높이는 걸까? 라는 생각도 들었다. 이런 경험을 할 수 있었던 시스템을 직접 만들어본 덕분에, 성능 개선은 전체적으로 어떻게 과정을 밟아야하는지 알 수 있어 많이 즐거웠다.
Throttling이 발생한 걸 보고 Thread dump라던가 이런 걸 해볼 생각이 들었었는데, 이런 걸 자동화 하려면 어떻게 해야할지 고민도 들었다. 시스템에 특이한 사항이 생겼을 때 자동으로 Thread랑 Heap dump를 찍어준다면 정말 편리할텐데... Dynatrace만 봐도 최근 동향에 따라 Alert을 조절하는 자체적인 기능이 있었던걸 보면 충분히 가능하지 않을까 한다. 다만 엄청나게 쏟아지는 시스템 로그를 학습해야할 거 같다. (아 돈이면 다 된다구요?)
아무튼 파란만장했던 부하테스트가 끝나니, 앞으로 시스템을 위해 무엇들을 구축해나가야 하는지 방향이 보이던 활동이었다.

9개의 댓글

안녕하세요! 부하 테스트 진행해야 했는데 많은 도움이 되었습니다 ㅎㅎ 그런데 부하 시나리오에서
테스트 시간: 15명 요 부분 오타가 있네요!

안녕하세요! 잘 보고 있습니다!
저는 백엔드 취준생인데 성호님이 하신 것처럼 부하테스트를 하면 좋겠다라는 생각이 드는데 어떤식으로 진행하셨고, 참고하신 강의가 있으신지 여쭤봐도 괜찮을까요?

I was waiting in a long queue at the train station and got super bored. So I searched random things on my phone and stumbled on Slottica. At first, I thought it was some complicated site, but it was pretty simple. You sign up and you already get bonuses, spins, and a bunch of cool deals. What I liked about Slottica is that it didn’t push me to spend big. Just register, claim offers, and you can explore at your own pace. I actually forgot I was even in line.
안녕하세요! 이번에 2025 현대오토에버 신입 개발자에 지원하려고 하는 취준생입니다..!
혹시 궁금한 점 메일이나 커피챗 등 여쭤볼게 있는데 괜찮을까요??