해시 테이블(Hash Table)
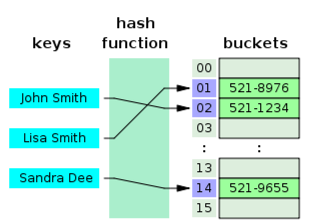
해시 함수(Hash Function)를 사용하여키(Key)를해시 값(Hash Value)으로 매핑하고, 이 해시 값을 인덱스 또는 주소로 삼아 데이터를 키와 함께 저장하는 Key-Value 로 이루어진 자료구조
키(Key)
- 고유한 값, 해시 함수의 입력이 됨
- 가변 길이인 키를 그대로 저장소의 인덱스로 사용할 경우 키의 길이만큼의 정보를 저장할 공간도 따로 마련해야하기 때문에 고정된 길이의 해시로 변경함
해시 값(Hash Value)
- 저장소에 최종적으로 저장되는 값
- 저장소 → 버킷, 슬롯(Bucket, Slot) : 데이터가 저장되는 곳
해시 함수(Hash Function)
- 가변 길이인 키를 고정 길이의 해시로 변경해주는 역할을 함
- 위 과정 전체를
해싱(Hashing)이라 함 - 키를 해시 함수에 입력으로 넣어 출력으로 나오는 것이 해시이고, 이 해시가 키의 저장 위치가 됨 → 키로 해시를 만들어내는 함수
해시 테이블 장점
- 적은 리소스로 많은 데이터를 효율적으로 관리할 수 있음
- 해시 함수는 언제나 동일한 해시 값을 반환하고, 해당 인덱스만 알면 데이터에 굉장히 빠르게 접근이 가능함 → Key-Value 가 1:1로 매핑되어, 삽입, 삭제, 검색의 과정에서 모두 평균적으로 의 시간 복잡도를 가짐(매우 빠른 속도)
해시 테이블 단점
- 해시 충돌이 발생함 → 개방 주소법(Open Address), 체이닝(Chaining) 과 같은 기법으로 해결
- 순서나 관계가 있는 배열에는 어울리지 않음
- 데이터가 저장되기 전에 저장 공간을 마련해둬야함 → 공간 효율성이 떨어짐
- 해시 함수의 성능에 따라 해시 테이블의 성능도 달라짐 → 해시 함수의 의존도가 높음
직접 주소 테이블(Direct Address Table)
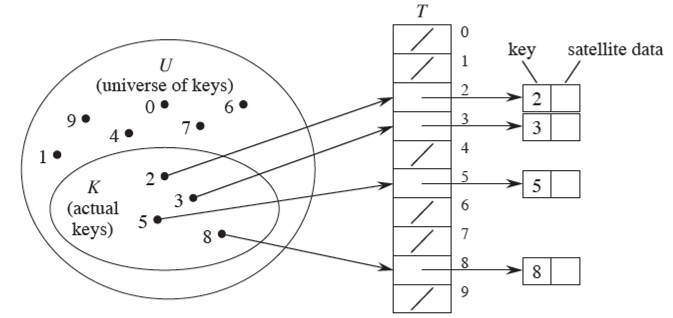
- 키의 전체 개수와 동일한 크기의 버킷을 가진 해시 테이블
- 키 개수와 해시 테이블 크기가 동일함 → 해시 충돌 문제가 발생하지 않음
- 전체 키가 실제 사용하는 키보다 훨씬 많은 경우, 메모리 효율성이 크게 떨어짐(굳이 만들 필요가 없는 버킷을 만들기 때문)
- 일반적으로 해시 테이블 크기가 실제 사용하는 키 개수보다 적은 해시 테이블을 운용함
해시 충돌(Hash Collision)
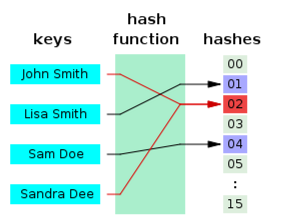
- 해시 함수가 서로 다른 키에 대해 동일한 해시 값을 반환하는 것
- 해시 충돌 발생 확률이 적을수록 좋음
- 모든 키가 같은 해시 값이 나오게 되면 데이터 저장 시 비효율성도 커지고, 보안도 취약해지므로, 해시 충돌이 균등하게 발생 하는 것도 중요함
해시 충돌 해결 방법
1. 체이닝(Chaining)
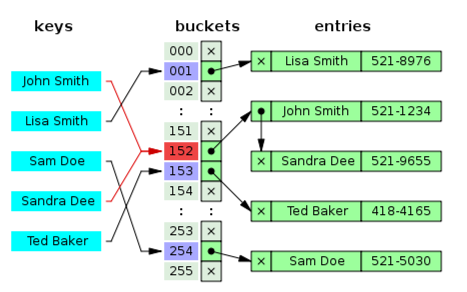
- 한 버킷당 들어갈 수 있는 엔트리의 수에 제한을 두지 않음으로써 모든 자료를 해시 테이블에 담는 것
- 해당 버킷에 데이터가 이미 있다면, 노드를 추가하여 다음 노드를 가리키는 방식으로 구현(연결 리스트)
- 미리 공간을 잡아둘 필요 없이, 충돌 발생 시 공간을 만들어서 연결해주면 됨 → 유연함
- 같은 해시에 자료들이 많이 연결되면 검색 효율이 떨어짐 → 메모리 문제 발생
2. 개방 주소법
- 한 버킷당 들어갈 수 있는 엔트리가 하나뿐인 해시 테이블 → 1:1 관계 유지
- 충돌이 일어나면 비어있는 해시에 데이터를 저장하는 방법
- 메모리 문제가 발생하지 않으나, 해시 충돌이 생길 수 있음
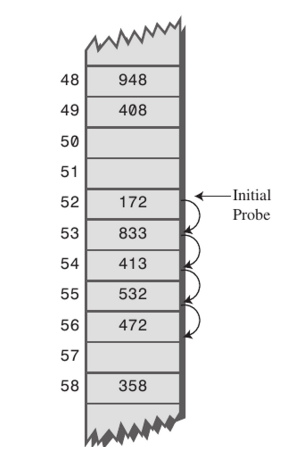
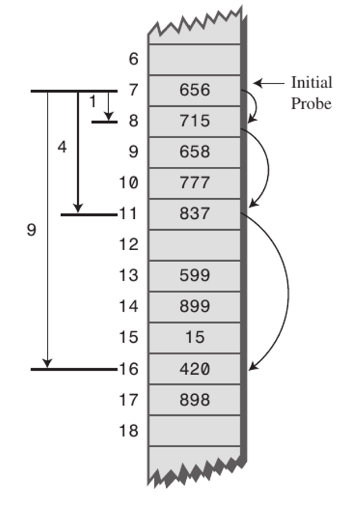
- 해시를 찾아가는 방법
- 선형 탐색(Linear Probing)
- 최초 해시 값에 해당하는 버킷에 다른 데이터가 저장되어있으면 해당 해시 값에서 고정 폭을 옮겨 다음 해시 값에 해당하는 버킷에 액세스 함
- 구현은 쉬우나, 특정 해시 값 주변 버킷이 모두 채워져 있는 Primary Clusterting 문제에 취약함
- 값이 들어있는 버킷의 수가 많으면 검색 시간이 증가
- 제곱 탐색(Quadratic Probing)
- 고정 폭이 아닌 1칸 → 4칸 → 9칸 → 16칸 씩 건너뛰면서 빈 칸을 찾음
- Primary Clustering 을 줄일 수 있음
- 여러 개의 서로 다른 키들이 동일한 초기 해시 값을 갖는 Secondary Clustering 문제에 취약함
- 이중 해싱(Double Hashing)
- 탐사할 해시 값의 규칙성을 없애버려서 Clustering 을 방지하는 기법
- 2개의 해시 함수를 준비해서 하나는 최초의 해시 값을 얻을 때, 또 다른 하나는 해시 충돌이 일어났을 때 탐사 이동폭을 얻기 위해 사용함
- 최초 해시 값이 같더라도 탐사 이동폭이 달라지고, 탐사 이동폭이 같더라도 최초 해시값이 달라짐 ⇒ Primary, Secondary Clustering 모두 완화 가능
- 선형 탐색(Linear Probing)
해시 함수 매핑 개선
-
특정 값에 치우치지 않고 해시 값을 고르게 만들어내는 해시 함수가 좋은 해시 함수라고 할 수 있음
-
나눗셈법(Division Method)
- 가장 기본적인 해시함수로, 숫자로 된 키를 해시 테이블 크기 으로 나눈 나머지를 해시 값으로 변환함
- 간단하면서도 빠른 연산이 가능한 것이 장점
- 해시의 중복 방지를 위해 테이블의 크기 은 소수로 지정해서 사용하는 것이 좋지만, 남는 공간이 발생해 메모리상으로 비효율적임
-
곱셈법(Multiplication Method)
- 숫자로 된 키가 이고, 는 0과 1 사이의 실수일 때 로 정의됨
- 2진수 연산에 최적화된 컴퓨터 구조를 고려한 해시함수
-
유니버설 해싱(Universal Hashing)
- 다수의 해시 함수를 만들고, 이 해시 함수의 집합에서 무작위로 해시 함수를 선택해 해시 값을 만드는 기법
- 서로 다른 해시 함수가 서로 다른 해시 값을 만들어내므로 같은 공간에 매핑할 확률을 줄이는 것이 목적

조금 느릴게요~