자료구조 (Data Structure)
컴퓨터 과학에서 효율적인 접근 및 수정을 가능하게 하는 자료의 조직, 관리, 저장을 의미
데이터 값의 모임, 데이터 간의 관계, 데이터에 적용 가능한 함수나 명령을 의미
저장되는 데이터의 형태에 따라 선형 자료 구조와 비선형 자료구조로 구분
선형 자료구조 (Linear Data Structure)
데이터가 일렬로 나열되어 있는 자료구조
1. 배열 (Array)
동일한 자료형의 데이터를 하나의 연속된 메모리 공간에 일렬로 나열하고 관리하는 자료구조
특징
데이터 접근이 용이함 (인덱스로 접근하므로 직접 접근이 가능하여 데이터 접근의 속도가 빠름)
구조가 간단하여 프로그램 작성이 간편함
크기가 고정 되어있으며, 불필요한 공간을 요구하므로 메모리 공간 사용량이 높음
데이터 삽입 / 삭제 시 데이터들의 이동이 필요하므로 삽입 / 삭제가 어려움
구현 - Java
/* 선언 */
int[] integerArray;
String[] stringArray;
/* 생성 */
integerArray = new int[100];
stringArray = new String[10];
/* 초기화 */
for (int i = 0; i < integerArray.length; i++) {
integerArray[i] = i;
}
stringArray = new String[]{"hello", "world"};
String[] names = {"Bob", "Tracy", "Jack"};시간 복잡도
- 데이터 조회 :
- 데이터 삽입 / 삭제 :
2. 연결 리스트 (Linked List)
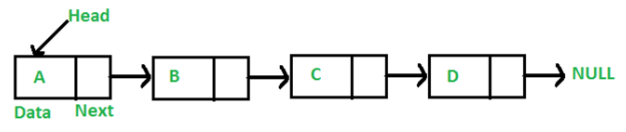
각 노드가 데이터와 포인터를 가지고 일렬로 연결되어있는 방식의 자료구조
특징
동적 크기를 가짐
데이터 삽입 / 삭제가 용이함
데이터 접근이 느림 (순차접근 방식
포인터 변수를 위한 여분의 메모리 공간이 필요함
헤드(Head) : 연결 리스트의 첫 노드에 대한 참조값을 가짐
노드 (Node)
데이터와 다음 노드에 대한 참조값(주소)를 가짐
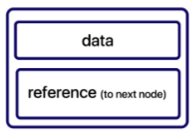
구현 (Java)
class Node<E> {
E data;
Node<E> next;
Node(E data) {
this.data = data;
this.next = null;
}
}단방향 연결 리스트 (Singly LinkeList)
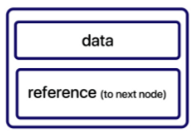
노드에 데이터와 다음 노드를 가리키는 노드 변수 next 를 가짐
next 가 NULL 인 노드가 연결리스트의 마지막 노드
위 그림과 같은 노드들이 여러개가 연결되어있는 연결리스트
양방향 연결 리스트 (Doubly LinkedList)
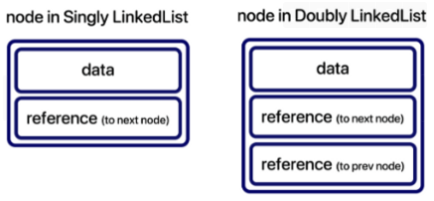
실제 Java 에서 제공하는 LinkedList 는 양방향 연결 리스트의 형식
노드에 데이터와 다음 노드를 가리키는 노드 변수 next 와 이전 노드를 가리키는 노드 변수 prev 를 가짐
위 그림과 같은 노드들이 여러개가 연결되어있는 연결리스트
시간 복잡도
- 데이터 조회 :
- 맨 앞/뒤에 데이터 삽입/삭제 :
- 단방향 연결리스트의 경우 맨 뒤의 데이터 삭제 시
- 중간의 원하는 위치에 데이터 삽입/삭제 :
배열 vs 연결 리스트
1. 데이터 접근 속도
배열은 임의 접근(Random Access) 가 가능한 반면, 연결 리스트는 순차 접근 (Sequential Access) 를 하므로 배열이 더 효율적
2. 데이터의 삽입/삭제
배열은 데이터를 맨 앞이나 중간에 삽입/삭제하는 경우 모든 데이터의 이동이 필요하므로 비효율적
중간 삽입/삭제는 배열과 같은 시간 복잡도를 가지나, 맨 앞이나 맨 뒤에 삽입할 경우 연결 리스트가 더 효율적
3. 메모리 할당
배열은 정적 메모리 할당이 이루어짐 (Compile Time)
연결 리스트는 동적 메모리 할당이 이루어짐 (Run Time)
배열은 크기가 고정이 되어있어 다 차게 되면 새로운 메모리 공간이 필요함
연결 리스트는 동적으로 할당 받을 수 있음
둘 중 절대적으로 뛰어난 자료 구조는 없음 => 해당 상황에 맞춰 사용
- 데이터 삽입/삭제가 빈번한 경우 연결 리스트를 사용
- 데이터 접근 속도가 중요한 경우 배열을 사용
3. 스택 (Stack)
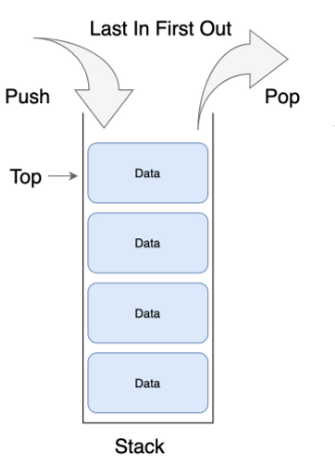
특징
삽입, 삭제 연산이 한 방향에서만 이루어지는 자료구조
나중에 들어간 원소가 먼저 나오는 후입 선출 (LIFO, Last In First Out) 구조를 가짐
용어
Top : 스택에 데이터가 삽입/삭제 될 위치
주요 연산
PUSH : 스택의 Top 에 원소 삽입
POP : 스택의 Top 에 있는 원소 삭제 및 반환
PEEK : 스택의 Top 에 있는 원소 반환
시간 복잡도
데이터 삽입/삭제 :
Top 데이터 조회 :
특정 데이터 조회 :
활용
- 시스템 스택 (System Stack) / 실행시간 스택 (Runtime Stack)
- 인터럽트 루틴 처리
- 웹 브라우저 방문 기록 관리 (뒤로가기)
- 실행 취소 (UNDO)
- 수식의 후위 표기법 (Postfix Notation)
- 수식의 괄호식 검사
- 계산기 검사
- 깊이 우선 탐색 (DFS, Depth First Search)
4. 큐 (Queue)
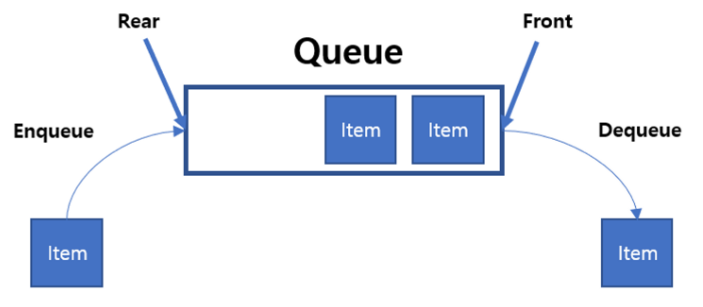
특징
한 방향에서는 삽입 연산이, 반대 방향에서는 삭제 연산이 이루어지는 자료구조
가장 먼저 들어온 원소가 가장 먼저 나오는 선입 선출 (First In First Out) 구조를 가짐
용어
Front / Head : 큐에서 데이터가 삭제될 위치 (가장 먼저 들어온 데이터)
Rear / Tail : 큐에서 마지막 데이터가 삽입된 위치 (가장 나중에 들어온 데이터)
주요 연산
enQueue : 큐에 원소 삽입
deQueue : 큐의 원소 삭제 및 반환
시간 복잡도
데이터 삽입/삭제 :
Front/Head 데이터 조회 :
특정 데이터 조회 :
활용
- 프로세스 레디 큐
- 스케쥴링 (Scheduling)
- 캐시 (Cache) 구현
- 네트워크 패킷 전송 시 필요한 버퍼 대기 큐
- JavaScript 의 Event Loop 관리 (비동기 처리)
- 키보드 버퍼
- 프린터의 출력 처리
- 너비 우선 탐색 (BFS, Breadth-First Search)
