
Part 1. 빅데이터분석기획
Chapter 01. 빅데이터의 이해
Section 01. 빅데이터 개요 및 활용
데이터 : 추론과 추정의 근거를 이루는 사실
- 특징 : 단순한 객채로도 가치 있음, 객체 간 상호관계 속 더 큰 가치
-
정량 데이터 : 숫자
1-1. 정형 : 정해진 형식, 구조 (RDBMS)
1-2. 반정형 : Schema 정보를 데이터와 함께 제공, 연산 불가 (JSON, XML) -
정성 데이터 : 문자, 함축적 의미를 담은 데이터
2-1. 비정형 : 구조가 정해지지 않음, 동양상, 이미지, mp3 등
-
원본 Data → [데이터 수집 과정] → 재생산
- 가역 : 원본으로 환원 가능 (1:1)
- 불가역 : 원본으로 환원 불가능
-
지식의 피라미드
: 지혜 > 지식 > 정보 > 데이터 -
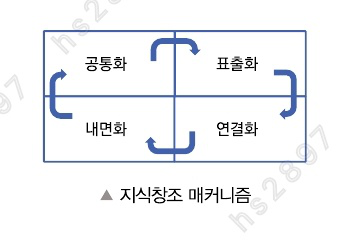
지식 형태
- 표출화 (암묵지→형식지)
- 연결화 (형식지→형식지)
- 내면화 (형식지→암묵지)
- 공통화 (암묵지→암묵지)
DBMS : DB를 관리하며 Applications 간 데이터 공유 가능한 환경 제공
- SQL : 데이터 정의, 조작 기능 제공 질의어
DB 활용
-
OLTP
: 현재 시점의 Data만을 DB가 관리, 복잡한 데이터 구조
: 데이터 갱신 위주 -
OLAP : Online Analytical Processing
: 단순한 데이터 구조, 정보 위주의 분석 처리,
OLTP에서 처리된 트랜잭션 데이터를 분석해 프로세싱
: 다차원적 데이터 접근 → 의사결정에 활용 가능한 정보 도출
: 데이터 조회 위주
Data Warehouse
: 일정 시간 동안 데이터 축적 → 의사결정을 위한 분석 작업 수행
- 특징
- 주제 지향성
- 통합성
- 시계열성
- 비휘발성
- 구조
: 데이터 모델 + ETL + ODS + Meta Data + OLAP + 데이터 마이닝 + 분석 Tool + 경영기반 솔루션
빅데이터
- 작은 용량에서 얻을 수 없던 새로운 인사이트, 가치 도출
빅데이터 5V
- Volume : 규모
- Variety : 형태
- Velocity : 속도
- Value : 가치
- Veracity : 진실성(품질)
- 데이터 처리의 변화
: 사전 처리(Preprocessing) → 사후 처리
: 필요 정보만 → 최대한 많이
: Quality → Quantity
- 데이터 분석의 변화
: 이론적 인과관계 → 단순 상관관계
빅데이터 활용 3요소
: 자원 + 기술 + 인력
-
빅데이터의 가치
: 고객 세분화, 맞춤형 개인화 서비스 제공
: 알고리즘 기반 의사결정 지원 -
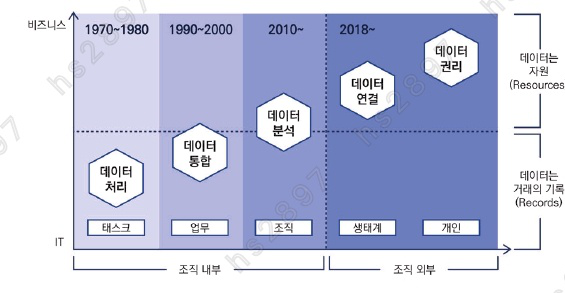
데이터 산업의 변화 과정
-
데이터 처리 (Task간 구분) [1970 - 1980]
: 데이터 = 업무 처리의 대상, 새로운 가치를 제공하지 않음 -
데이터 통합 (업무 간 구분) [1990 - 2000]
: 데이터 모델링, DBMS 등장 -
데이터 분석 (조직 간 구분) [2010 - ]
:Hadoop,Spark, 빅데이터 기술, 데이터 소비자의 역할, 데이터 리터러시 프로그램 -
데이터 연결 [2018 - ]
:Open API -
데이터 권리
: 마이데이터, 산업이 데이터 중심으로 재편
-
-
데이터 산업 구조
- Infra : 데이터 수집/저장/분석, HW & SW 영역
- Service : 데이터 활용 교육, 컨설팅, 솔루션 제공, 데이터 제공 및 처리
-
Data Scientist
: 데이터의 근원을 찾고, 복잡한 대용량 데이터를 구조화, 데이터 간 연결
Section 02. 빅데이터 기술 및 제도
빅데이터 플랫폼
: 빅데이터 수집/저장/처리/분석 등 전 과정을 통합적으로 제공하는 플랫폼
-
필요 이유
-
비즈니스 요구사항 변화 대응
: 장기적/전략적 접근, Cloud Computing 등 -
데이터 규모 증가, 처리 복잡도 증가
: 처리할 데이터의 규모 및 내용의 증가
: 정보의 수집 및 분석의 기간 증가
: 분산 처리 환경 필수
: 데이터 수집 경로의 다양화 -
데이터 구조의 변화
: 비정형 데이터의 비중 증가
: 데이터 실시간 처리의 필요성 강조
: 데이터 발생 속도의 증가 -
데이터 분석 유연성 향상
: AI의 발전 → 다양한 방법론을 통해 텍스트, 음성 등 다양한 형태의 데이터 분석 가능
-
-
기능
: 빅데이터를 처리하는 과정에서 발생하는 부하를 기술적 요소의 결합으로 해결- 부하 종류 / 해결법
- 컴퓨팅 부하: CPU 성능 향상 & Cluster에서의 효과적인 자원 할당
- 저장 부하 : File System 개선 & DB 성능 향상
- 네트워크 부하 : 대역폭의 효과적 분배 & 노드 간 최단거리 탐색
-
구조
: Software 계층 > Platform 계층 > InfraStructure 계층-
Software 계층
- Application 구성
- 데이터 처리 및 분석
- 데이터 수집 및 정제
-
Platform 계층
- 작업 스케줄링
- 데이터/리소스 할당 및 관리
- 프로파일링 모듈 운영
-
InfraStructure 계층
- 자원 배치, 스토리지 관리
- 네트워크, 노드 관리
- 빅데이터 처리 분석에 필요한 자원 제공
-
빅데이터 처리 과정과 요소 기술
-
처리 과정
: 데이터(생성) ▶ 수집 ▶ 저장(공유) ▶ 처리 ▶ 분석 ▶ 시각화-
생성
: DB, File System 등의 '내부 데이터'
: 인터넷 기준의 '외부 데이터' -
수집
: 데이터 원천을 크롤링해 데이터 검색 및 수집
:ETL(Extract, Transform, Load)를 통해 데이터 추출/변환/적재 -
저장
: 정형/반정형/비정형 데이터 저장
: 병렬 DBMS,Hadoop, NoSQL 등 활용
: 시스템 간 데이터 공유 -
처리
: 분산 병렬 처리
: 인메모리 방식의 실시간 처리(MapReduce) -
분석
: 특정 분야/목적의 특성에 맞는 분석 기법 선택
: 통계 분석, 데이터 마이닝, 텍스트 마이닝, 기계학습(ML) -
시각화
: 정보, 실시간 자료 시각화
-
1. 빅데이터 수집
-
크롤링
: 분산 저장되어있는 문서를 수집 → 검색 대상의 색인으로 포함 -
로그 수집기
: 조직 내 웹 서버, 시스템의 로그 수집 -
센서 네트워크
: 초경량, 저전력의 많은 센서로 구성된 유/무선 네트워크 -
RSS Reader, OpenAPI
: 데이터 생산 및 공유에 참여 -
ETL 프로세스
: 다양한 원천 데이터를 취합 → 추출 → 공통된 형식으로 변환 → 적재
2. 빅데이터 저장
-
NoSQL
: 비관계형 DB, SQL을 사용하지 않는 DBMS
:ACID의 유연한 적용 -
공유 데이터 시스템
:CAP이론= 분산 데이터베이스 시스템은 일관성, 가용성, 분할 내성 중 2개만 충족 가능
: 기존 RDBMS 대비 높은 성능과 확장성을 위함 -
병렬 DB 관리 시스템
: 다수의 마이크로프로세서 탑재, 작은 단위 동작의 트랜잭션
: 여러 디스크에서 DB처리를 동시에 진행 -
분산 파일 시스템
: 네트워크로 공유하는 파일 시스템
:GFS(Google File System), AWS S3, HDFS -
네트워크 저장 및 공유
:SAN,NAS
3. 빅데이터 처리
-
분산 시스템과 병렬 시스템
: 분산된 다수의 COM을 단일 시스템처럼 사용
: 작업을 분할해 동시에 처리 -
분산 병렬 컴퓨팅
: 독립된 컴퓨팅 자원을 네트워크 상에 연결
: 미들웨어를 이용해 하나의 시스템으로 활용 -
Hadoop
: 분산처리 환경에서 대용량 데이터 처리/분석을 지원하는 OpenSource Framework
: HDFS(분산파일시스템) + HBase + MapReduce(분산 컴퓨팅 프레임워크) -
Apache Spark
: 인메모리 방식의 분산형 컴퓨팅 플랫폼
:Hadoop보다 빠른 속도가 특징
:Scala, R, Java, Python지원 -
MapReduce
: 구글에서 개발, 효과적인 병렬/분산처리 지원
: 분산 병렬 데이터 처리 기술 표준
MapReduce 처리 단계
: Split ▶ Map ▶ Shuffle ▶ Reduce
: 입력 데이터 READ → 데이터 분할(Split) → 분할된 데이터 할당(Map)
→ 중간 데이터 통합 및 재분할 → 중간 데이터 셔플(Shuffle) → Reduce → 출력 데이터 생성
4. 빅데이터 분석
-
데이터 분석 방법 분류
- EFA (탐구 요인 분석) : 데이터 간 상호 관계 파악
- CFA (확인 요인 분석) : 집합요소 구조 파악을 위해 통계적 기법을 통한 데이터 분석
-
데이터 분석 방법
:Classification(분류),Clustering(군집화),ML,TextMining,Web Mining,Opinion Mining,Reality Mining, 소셜네트워크 분석, 감성 분석 등
빅데이터와 인공지능
- 인공지능 : 사람이 생각하고 판단하는 사고 구조를 구축
- 기계학습 : 축적된 데이터를 통해 인간의 학습 능력과 같은 기능 구축
- 딥러닝 : 깊은 구조를 기반으로, 대량의 데이터를 이용해 사람처럼 스스로 학습
기계학습의 종류
- 지도 학습
: 학습 데이터로부터 하나의 함수 유추 - 비지도 학습
: 데이터 구성 방식 파악, 입력값에 대한 목표치 없음,군집화등 - 준지도 학습
: 목표가 있는, 없는 데이터 모두 학습에 사용 - 강화 학습
: 선택 가능한 행동 중 보상을 최대화하는 행동 선택
: 학습 과정에서의 성능에 초점 → 탐색/이용 간의 균형 중시
데이터 학습의 진화
-
전이학습
: 기존 학습된 모델의 지식을 새로운 문제에 적용
: 빠르고 효율적인 학습 수행
: 적은 양의 데이터로도 좋은 결과 도출
: 지도학습 분류 모형 중인식특화(이미지, 텍스트) -
전이학습 기반 사전 학습 모형
: 인지능력을 갖춘 Deep Learning 모형에 추가 데이터 학습 -
BERT
빅데이터와 인공지능 간 관계
-
양질의 데이터 확보 = 인공지능의 학습 데이터를 위해 필수적
-
Annotation을 통해 학습이 가능한 데이터로 가공
Annotation?
→ 데이터 주석을 작성하는 과정, 설명을 추가한다. -
인공지능 기술 동향
: ML Framework(TF, Keras) ▶ GAN ▶ Auto-Encoder ▶ XAI(설명가능 AI) ▶ AutoML ▶ LLM
개인정보
- 살아있는 개인에 관한 정보, 개인을 알아볼 수 있는 정보
- 다른 정보와 쉽게 결합해 특정 개인을 식별할 수 있는 정보
개인정보 처리 위탁
: 업무 처리를 목적으로 제3자에게 정보를 이전
: 제공하는 자의 업무
개인정보 제3자 제공
: 업무 처리 및 이익을 목적으로 정보를 제3자에게 정보를 이전
: 제공받는 자의 업무
빅데이터 개인정보보호 가이드라인
: 비식별화, 투명성 확보, 재식별 시 조치, 민감정보 및 비밀번호 처리, 기술적/관리적 보호 조치
개인정보보호 고려사항
- 정보주체의 권리를 보호하며, 데이터의 효율적 이용 방안 모색
- 주요 법령 및 규제 기관의 가이드라인 지속 파악
- 내부 개인정보 컴플라이언스 체계 구축
-
개인정보 보호법
: 당사자 동의 없는 개인정보 수집 및 활용, 제3자 제공 금지
: 정보 주체로부터 개인정보 제3자 제공 동의 필요
: 통계 작성, 학술 연구를 목적으로 '특정 개인을 식별 불가능한 형태'로 개인정보 제공 가능 -
정보통신망법
: 이용자 동의 없는 개인정보 수집 및 제3자 제공 = 처벌 -
신용정보 보호법
: 개인신용정보를 신용정보회사 등에 제공 시에, 서면 혹은 공인전자서명 전자문서로의 동의 필수
※ 개인식별정보
: 성명, 주소, 주민등록번호 등 개인을 식별 가능한 정보
- 데이터 3법 주요 개정안
: '가명정보' 개념 도입, 유사/중복 규정 정비, 개인정보처리자 책임 강화
개인정보 비식별화
비식별조치
: 개인을 식별 가능한 요소를 전부(일부) 삭제/대체
- 가이드라인
: 사전검토 → 비식별조치(가명, 총계, 삭제, 범주화, 마스킹)
→ 적정성평가(k-익명성,l-다양성,t-근접성) → 사후관리
가명정보
: 개인정보를 일부를 삭제/대체하는 과정을 거쳐 나온 산출물
: 추가 정보 없이 특정 개인 식별 불가능
- 절차
: 사전준비(목적 설정 등) → 위험성 검토 → 가명처리 → 적정성 검토 → 관리
