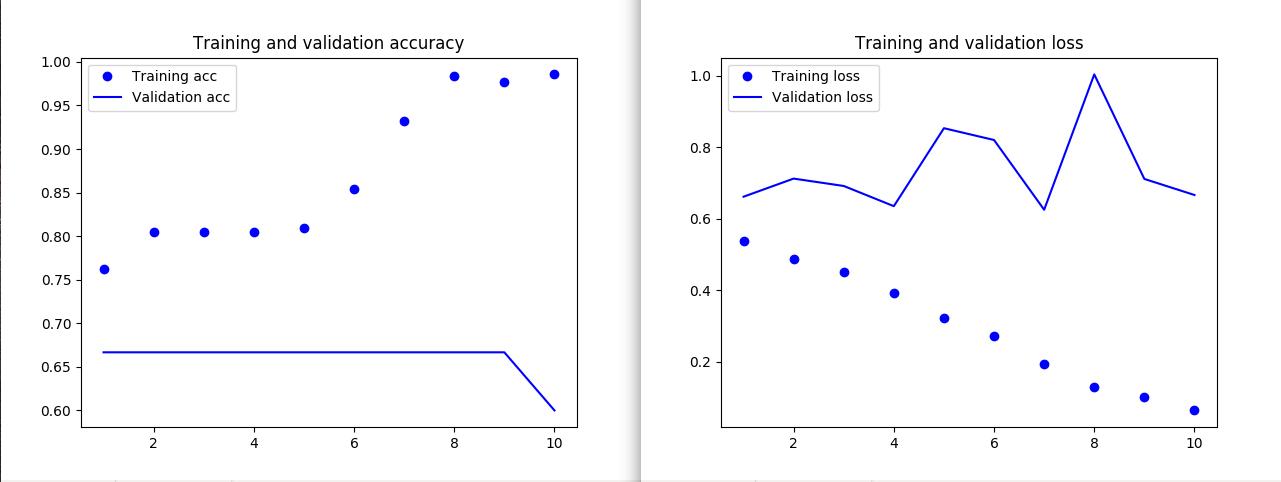
현재 training & validation accuracy
음... 딥러닝이 의미가 없다...
라벨이 좋지 않아서 그래.ㅠㅠ
라벨링 하는게 너무 힘들다... 너무 애매하다.
그냥 앗싸리 욕 있는것만 해봐야겠다.
물론 데이터가 극도로 적어서이긴 하지만.
이렇게 애매하게 했다간 데이터 많아져도 그대로일 것 같다.
...
아니야.
우선 데이터 모으는게 우선이 아닐까?
하.. 복잡하다.
Training accuracy는 1에 가까워지는데,
Validation accuracy는 오히려 점점 줄어들고 있다.
65~70대를 유지한 것 자체는 음... 희망적이라 봐야 하나?
...
이 글을 쓰게 된 계기는
토큰 전달 방법을 다르게 할까 싶어서이다.
현재 단순히 띄어쓰기로 전달하고 있는데.
음...
이건 나중 문제로 삼는게 낫겠다.
우선은 모델을 적용할 수 있는 방법을 확인해야겠다.
맞아! 이게 제일 중요하잖아.
다 만들어놓고.
적용 못하면 무슨소용이래??

남과 비교하지 말자.