DAGs Configuration
from datetime import datetime, timedelta
from textwrap import dedent
# The DAG object; we'll need this to instantiate a DAG
from airflow import DAG
# Operators; we need this to operate!
from airflow.operators.bash import BashOperator
with DAG(
'tutorial',
# These args will get passed on to each operator
# You can override them on a per-task basis during operator initialization
default_args={
'depends_on_past': False,
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
# 'wait_for_downstream': False,
# 'sla': timedelta(hours=2),
# 'execution_timeout': timedelta(seconds=300),
# 'on_failure_callback': some_function,
# 'on_success_callback': some_other_function,
# 'on_retry_callback': another_function,
# 'sla_miss_callback': yet_another_function,
# 'trigger_rule': 'all_success'
},
description='A simple tutorial DAG',
schedule_interval=timedelta(days=1),
start_date=datetime(2021, 1, 1),
catchup=False,
tags=['example'],
) as dag:
# t1, t2 and t3 are examples of tasks created by instantiating operators
t1 = BashOperator(
task_id='print_date',
bash_command='date',
)
t2 = BashOperator(
task_id='sleep',
depends_on_past=False,
bash_command='sleep 5',
retries=3,
)
t1.doc_md = dedent(
"""\
#### Task Documentation
You can document your task using the attributes `doc_md` (markdown),
`doc` (plain text), `doc_rst`, `doc_json`, `doc_yaml` which gets
rendered in the UI's Task Instance Details page.

"""
)
dag.doc_md = __doc__ # providing that you have a docstring at the beginning of the DAG
dag.doc_md = """
This is a documentation placed anywhere
""" # otherwise, type it like this
templated_command = dedent(
"""
{% for i in range(5) %}
echo "{{ ds }}"
echo "{{ macros.ds_add(ds, 7)}}"
{% endfor %}
"""
)
t3 = BashOperator(
task_id='templated',
depends_on_past=False,
bash_command=templated_command,
)
t1 >> [t2, t3]- basic pipeline 정의 이다.
- DAG 구조를 코드로 특정하기위한 configuration file이라고 보면된다.
- 이 파일이 어떤 프로세스를 수행하는거라고 오해하는 경우가 종종있는데, 이 스크립트는 단지 DAG Object를 정의하기위함이라는 것을 인지하고 있자.
Importing Modules
from datetime import datetime, timedelta
from textwrap import dedent
# The DAG object; we'll need this to instantiate a DAG
from airflow import DAG
# Operators; we need this to operate!
from airflow.operators.bash import BashOperator- 단지 Airflow DAG Object를 정의하는데 필요한 모듈들이다.
Default Arguments
# These args will get passed on to each operator
# You can override them on a per-task basis during operator initialization
default_args={
'depends_on_past': False,
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
# 'wait_for_downstream': False,
# 'sla': timedelta(hours=2),
# 'execution_timeout': timedelta(seconds=300),
# 'on_failure_callback': some_function,
# 'on_success_callback': some_other_function,
# 'on_retry_callback': another_function,
# 'sla_miss_callback': yet_another_function,
# 'trigger_rule': 'all_success'
},- 명시적으로 각 task의 구조체에 argument set을 넘겨줄 수 있다.
- 하지만, task 생성 시 default parameter들을 딕셔너리 형태로 정의해서 넘겨줄 수도 있음을 보여준다.
- 다른 목적으로 쓰이는 argument들도 쉽게 정의하여 사용할 수 있다.
- 예를들어 production 환경에서 쓰이는 경우 vs develop 환경에서 쓰이는 경우
Instantiate a DAG
with DAG(
'tutorial',
# These args will get passed on to each operator
# You can override them on a per-task basis during operator initialization
default_args={
'depends_on_past': False,
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
# 'wait_for_downstream': False,
# 'sla': timedelta(hours=2),
# 'execution_timeout': timedelta(seconds=300),
# 'on_failure_callback': some_function,
# 'on_success_callback': some_other_function,
# 'on_retry_callback': another_function,
# 'sla_miss_callback': yet_another_function,
# 'trigger_rule': 'all_success'
},
description='A simple tutorial DAG',
schedule_interval=timedelta(days=1),
start_date=datetime(2021, 1, 1),
catchup=False,
tags=['example'],
) as dag:- task들을 넣기위해 필요한 DAG object를 instanitate 하는 코드다.
- 위에서 설명한 default args를 여기에다가 넣어준다.
Tasks
t1 = BashOperator(
task_id='print_date',
bash_command='date',
)
t2 = BashOperator(
task_id='sleep',
depends_on_past=False,
bash_command='sleep 5',
retries=3,
)- Task들은 Operator 객체들이 인스턴스화할때 생성된다.
- task_id를 첫번째 인자로 넘겨줘서 task들을 식별할 수 있도록 해준다. (String)
- 위 Task는 다음 룰을 따른다.
- 명시적으로 arugment pass
- 그 외에는 default_args의 값이 알아서 pass
Templating with Jinja
templated_command = dedent(
"""
{% for i in range(5) %}
echo "{{ ds }}"
echo "{{ macros.ds_add(ds, 7)}}"
{% endfor %}
"""
)
t3 = BashOperator(
task_id='templated',
depends_on_past=False,
bash_command=templated_command,
)Adding DAG and Tasks docs
t1.doc_md = dedent(
"""\
#### Task Documentation
You can document your task using the attributes `doc_md` (markdown),
`doc` (plain text), `doc_rst`, `doc_json`, `doc_yaml` which gets
rendered in the UI's Task Instance Details page.

"""
)
dag.doc_md = __doc__ # providing that you have a docstring at the beginning of the DAG
dag.doc_md = """
This is a documentation placed anywhere
""" # otherwise, type it like this- 각 single task 마다 DAG에 대한 docs를 추가할 수 있다.
- Mark Down 형식으로 작성하면 된다.
Setting up Dependencies
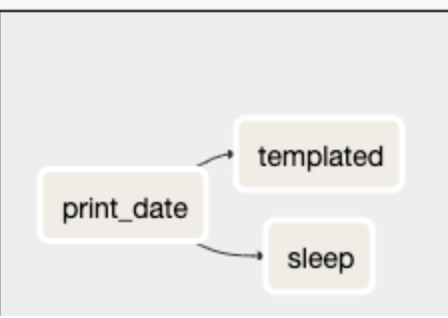
t1.set_downstream(t2)
# This means that t2 will depend on t1
# running successfully to run.
# It is equivalent to:
t2.set_upstream(t1)
# The bit shift operator can also be
# used to chain operations:
t1 >> t2
# And the upstream dependency with the
# bit shift operator:
t2 << t1
# Chaining multiple dependencies becomes
# concise with the bit shift operator:
t1 >> t2 >> t3
# A list of tasks can also be set as
# dependencies. These operations
# all have the same effect:
t1.set_downstream([t2, t3])
t1 >> [t2, t3]
[t2, t3] << t1- task 간에 dependency를 정의해주는 스크립트라고 이해하면된다.
Testing
Running the Script
python ~/airflow/dags/tutorial.py
- 이전 Step을 실행함으로서 default 경로에 airflow.cfg가 생긴다.
- exception이 raise 되지 않았다면 성공적으로 airflow dag에 대한 configuration이 마쳐진 것이다.
Command Line Metadata Validation
# initialize the database tables
airflow db init
# print the list of active DAGs
airflow dags list
# prints the list of tasks in the "tutorial" DAG
airflow tasks list tutorial
# prints the hierarchy of tasks in the "tutorial" DAG
airflow tasks list tutorial --tree

# command layout: command subcommand dag_id task_id date
# testing print_date
airflow tasks test tutorial print_date 2022-08-15
# testing sleep
airflow tasks test tutorial sleep 2022-08-15- ariflow tasks test command 는 task를 인스턴스화해서 테스트가 가능하게해준다.
Backfill
# optional, start a web server in debug mode in the background
# airflow webserver --debug &
# start your backfill on a date range
airflow dags backfill tutorial \
--start-date 2015-06-01 \
--end-date 2015-06-07- backfill은 dependency들을 따르고 파일로 로그를 남겨주고, status를 db에 기록해준다.
-depends_on_past=True를 했다면, 해당 task는 이전 task가 성공해야하는 것으로 의존성이 생긴다.
Pipeline Example
initial setup
# Download the docker-compose.yaml file
curl -Lf0 'https://airflow.apache.org/docs/apache-airflow/stable/docker-compose.yaml' > docker-compose.yaml
# Make expected directories and set an expected environment variable
mkdir -p ./dags ./logs ./plugins
echo -e "AIRFLOW_UID=$(id -u)" > .env
# Initialize the database
docker-compose up airflow-init
# Start up all services
docker-compose up
- localhost:8080 으로 접속하면 된다.
- default id,pwd : airflow
Table Creation Tasks
from airflow.providers.postgres.operators.postgres import PostgresOperator
create_employees_table = PostgresOperator(
task_id="create_employees_table",
postgres_conn_id="tutorial_pg_conn",
sql="""
CREATE TABLE IF NOT EXISTS employees (
"Serial Number" NUMERIC PRIMARY KEY,
"Company Name" TEXT,
"Employee Markme" TEXT,
"Description" TEXT,
"Leave" INTEGER
);""",
)
create_employees_temp_table = PostgresOperator(
task_id="create_employees_temp_table",
postgres_conn_id="tutorial_pg_conn",
sql="""
DROP TABLE IF EXISTS employees_temp;
CREATE TABLE employees_temp (
"Serial Number" NUMERIC PRIMARY KEY,
"Company Name" TEXT,
"Employee Markme" TEXT,
"Description" TEXT,
"Leave" INTEGER
);""",
)- postgres db에 table을 생성하기위해 task를 정의한다.
- using PostgresOperator
Data Retrieval Task
import os
import requests
from airflow.decorators import task
from airflow.providers.postgres.hooks.postgres import PostgresHook
@task
def get_data():
# NOTE: configure this as appropriate for your airflow environment
data_path = "/opt/airflow/dags/files/employees.csv"
os.makedirs(os.path.dirname(data_path), exist_ok=True)
url = "https://raw.githubusercontent.com/apache/airflow/main/docs/apache-airflow/pipeline_example.csv"
response = requests.request("GET", url)
with open(data_path, "w") as file:
file.write(response.text)
postgres_hook = PostgresHook(postgres_conn_id="tutorial_pg_conn")
conn = postgres_hook.get_conn()
cur = conn.cursor()
with open(data_path, "r") as file:
cur.copy_expert(
"COPY employees_temp FROM STDIN WITH CSV HEADER DELIMITER AS ',' QUOTE '\"'",
file,
)
conn.commit()Data Merge Task
from airflow.decorators import task
from airflow.providers.postgres.hooks.postgres import PostgresHook
@task
def merge_data():
query = """
INSERT INTO employees
SELECT *
FROM (
SELECT DISTINCT *
FROM employees_temp
)
ON CONFLICT ("Serial Number") DO UPDATE
SET "Serial Number" = excluded."Serial Number";
"""
try:
postgres_hook = PostgresHook(postgres_conn_id="tutorial_pg_conn")
conn = postgres_hook.get_conn()
cur = conn.cursor()
cur.execute(query)
conn.commit()
return 0
except Exception as e:
return 1Completing our DAG
[create_employees_table, create_employees_temp_table] >> get_data() >> merge_data()- 최종적으로 수행할 DAG 이다.
- merge_data()는 get_data() task에 의존성을 둔다.
- get_data()는 create_employees_table, create_employees_temp_table task에 의존성을 둔다.
- create_employees_table, create_employees_temp_table은 독립적으로 실행된다.
import datetime
import pendulum
import os
import requests
from airflow.decorators import dag, task
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.providers.postgres.operators.postgres import PostgresOperator
@dag(
schedule_interval="0 0 * * *",
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
dagrun_timeout=datetime.timedelta(minutes=60),
)
def Etl():
create_employees_table = PostgresOperator(
task_id="create_employees_table",
postgres_conn_id="tutorial_pg_conn",
sql="""
CREATE TABLE IF NOT EXISTS employees (
"Serial Number" NUMERIC PRIMARY KEY,
"Company Name" TEXT,
"Employee Markme" TEXT,
"Description" TEXT,
"Leave" INTEGER
);""",
)
create_employees_temp_table = PostgresOperator(
task_id="create_employees_temp_table",
postgres_conn_id="tutorial_pg_conn",
sql="""
DROP TABLE IF EXISTS employees_temp;
CREATE TABLE employees_temp (
"Serial Number" NUMERIC PRIMARY KEY,
"Company Name" TEXT,
"Employee Markme" TEXT,
"Description" TEXT,
"Leave" INTEGER
);""",
)
@task
def get_data():
# NOTE: configure this as appropriate for your airflow environment
data_path = "/opt/airflow/dags/files/employees.csv"
os.makedirs(os.path.dirname(data_path), exist_ok=True)
url = "https://raw.githubusercontent.com/apache/airflow/main/docs/apache-airflow/pipeline_example.csv"
response = requests.request("GET", url)
with open(data_path, "w") as file:
file.write(response.text)
postgres_hook = PostgresHook(postgres_conn_id="tutorial_pg_conn")
conn = postgres_hook.get_conn()
cur = conn.cursor()
with open(data_path, "r") as file:
cur.copy_expert(
"COPY employees_temp FROM STDIN WITH CSV HEADER DELIMITER AS ',' QUOTE '\"'",
file,
)
conn.commit()
@task
def merge_data():
query = """
INSERT INTO employees
SELECT *
FROM (
SELECT DISTINCT *
FROM employees_temp
)
ON CONFLICT ("Serial Number") DO UPDATE
SET "Serial Number" = excluded."Serial Number";
"""
try:
postgres_hook = PostgresHook(postgres_conn_id="tutorial_pg_conn")
conn = postgres_hook.get_conn()
cur = conn.cursor()
cur.execute(query)
conn.commit()
return 0
except Exception as e:
return 1
[create_employees_table, create_employees_temp_table] >> get_data() >> merge_data()
dag = Etl()- task들을 개발한 후 DAG로 therm을 wrap 한다.

OnePunchLotto