
How it works
- Pivot 원소 선택 후 분할 연산
- 여기서 분할 연산이라 함은 부분 배열로 나누는 것을 의미한다.
- 부분 배열은 2가지로 나눌 수 있다. 하나는 Pivot보다 작거나 같은 원소를 포함하는 부분 배열, 다른 하나는 Pivot보다 큰 원소를 포함하는 부분 배열이다.
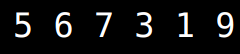
- 분할 전 위와 같은 원소가 있다고 해보자.
- 여기서 보통은 Pivot을 가운데 인덱스 원소로 두지만, 기초를 다질 때는 맨 앞의 원소로 둬도 된다.
- Pivot을 무엇으로 둘 것이냐는 Qucik Sort의 성능에 영향을 끼친다.
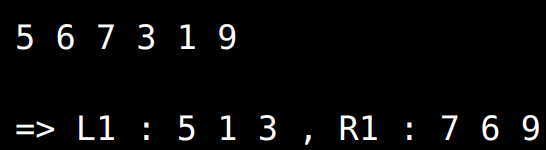
- 분할을 1회 수행하면 최초 배열에 대한 부분 배열로 나뉘게 된다.
- Pivot (5)보다 작거나 같은 것 : L1
- Pivot (5)보다 큰 것 : R1

- 분할을 2회 째 하게 되면, L1, R1 따로 분할을 수행한다. 분할의 개념은 첫 배열을 분할 할 때와 동일하다.
- 즉, L1은 Pivot이 5가 되어 L1_L2를, L1_R2로 분할되고, R1은 Pivot이 7이 되어 R1_L2, R1_R2로 분할된다.
- 위 Operation을 통해 코드 상에서 퀵 정렬은 재귀 형태로 적용 될 수 있음을 유추할 수 있다.

- 반복으로 수행하면 맨 마지막으로는 결국 정렬된 형태가 된다.
Code Review
Pivot : First Element
1. partition
#include <iostream>
#include <vector>
#include <chrono>
template <typename T>
auto partition(typename std::vector<T>::iterator begin, typename std::vector<T>::iterator end)
{
auto pivot_val = *begin;
auto left_iter = begin + 1;
auto right_iter = end;
while (true)
{
while (*left_iter <= pivot_val && std::distance(left_iter, right_iter) > 0)
++left_iter;
while (*right_iter > pivot_val && std::distance(left_iter, right_iter) > 0)
--right_iter;
if (left_iter == right_iter)
{
break;
}
else
{
std::iter_swap(left_iter, right_iter);
}
}
if (pivot_val > *right_iter)
std::iter_swap(begin, right_iter);
return right_iter;
}- partition이라는 함수는 하나의 배열을 부분 배열로 나눠주는 function이다.
- cpp template은 float이든, string이든 대응 할 수 있는 코드를 위해 사용하고, 자료형에 구애받지 않는 프로그래밍은 cpp에서 권장하는 방식이다.
- iterator를 사용하는 방식도 한 몫한다.
- pivot을 기준으로 왼쪽은 pivot보다 작거나 같고, 오른쪽은 pivot보다 큰 원소들이 위치되도록 한다.
- 여기서 pivot은 첫 번째 원소로 두었다.
while (*left_iter <= pivot_val && std::distance(left_iter, right_iter) > 0)
++left_iter;
while (*right_iter > pivot_val && std::distance(left_iter, right_iter) > 0)
--right_iter;- left_iter는 첫 번째 원소 (Pivot)의 바로 앞에서 시작해서 Pivot보다 큰 원소를 찾는다. 찾으면 Stop
- right_iter는 맨 마지막 원소에서 시작해서 더 작은 index로 이동하며 Pivot보다 작거나 같은 원소를 찾는다. 맞찬가지로 찾으면 Stop.
- std::distance가 양수인지를 Check 하는 것은 결국 left_iter나 right_iter가 이동하다 보면 같은 index를 가리키게 되는데, 이 때, 연산을 수행하지 않기 위함이다.
- 이 때가 std::distance가 0일 때 이다. while문에서는 false가 되주는 조건이 된다.
if (left_iter == right_iter)
{
break;
}
else
{
std::iter_swap(left_iter, right_iter);
}- 서로 같은 지점을 가리킬 때 break, 그 외 상황에서는 값을 swap한다.
- Pivot 보다 큰 값을 찾던 left_iter와 작거나 같은 값을 찾던 right_iter의 swap으로 해당 배열의 왼쪽이 작거나 같은 값, 오른쪽이 큰 값들이 모이게 되는 것이다.
if (pivot_val > *right_iter)
std::iter_swap(begin, right_iter);- 서로 같은 지점을 가리킬 때 iterator 이동 연산을 하지 않고 while문을 탈출한 후 수행해주는 연산이다.
- 서로 같은 지점인 index의 값이 pivot보다 값이 작으면, pivot과 값을 변경해준다.
- pivot이 더 큰 값이므로 오른쪽으로 가야된다.
return right_iter;- 분할 연산의 return 값을 right iterator다.
- 재귀 연산 수행 시 분할할 지점이다.
2. quick sort main
template <typename T>
void quick_sort(typename std::vector<T>::iterator begin, typename std::vector<T>::iterator last)
{
if (std::distance(begin, last) < 1)
return;
auto partition_iter = partition<T>(begin, last);
quick_sort<T>(begin, partition_iter - 1);
quick_sort<T>(partition_iter, last);
}- 어떤 배열을 받고, 1회 분할 수행 후 return 받은 iterator(해당 배열의 분할 연산 수행 후 right_iterator)를 받는다.
- return 받은 iterator로 재귀적인 분할 수행을 수행한다.
- 왼쪽, 오른쪽 배열을 재귀함수 형태로 삽입하여 부분 배열들도 partition 연산을 통해 정렬을 수행할 수 있도록 한다.
3. result
template <typename T>
void print_vector(std::vector<T> arr)
{
for (auto i : arr)
std::cout << i << ' ';
std::cout << std::endl;
}
int main()
{
std::chrono::system_clock::time_point start, end;
std::chrono::nanoseconds t_diff;
start = std::chrono::system_clock::now();
std::vector<int> S1{45, 1, 3, 1, 2, 3, 45, 5, 1, 2, 44, 5, 7};
print_vector<int>(S1);
quick_sort<int>(S1.begin(), S1.end() - 1);
print_vector<int>(S1);
end = std::chrono::system_clock::now();
t_diff = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start);
std::cout << "소요 시간 : " << (int)t_diff.count() << " ns" << std::endl;
return 0;
}Pivot : Middle Element
1. partition
template <typename T>
auto partition2(typename std::vector<T>::iterator begin, typename std::vector<T>::iterator end)
{
auto pivot_iter = begin + static_cast<int>(std::distance(begin, end) / 2) + 1;
auto pivot_val = *pivot_iter;
std::iter_swap(pivot_iter, end);
auto left_iter = begin;
auto right_iter = end - 1;
while (true)
{
while (*left_iter <= pivot_val && std::distance(left_iter, right_iter) >= 0)
++left_iter;
while (*right_iter > pivot_val && std::distance(left_iter, right_iter) >= 0)
--right_iter;
if (std::distance(left_iter, right_iter) < 0)
{
break;
}
else
{
std::iter_swap(left_iter, right_iter);
}
}
std::iter_swap(left_iter, end);
return pivot_iter;
}- interator의 중간 index로 두도록 pivot 값을 바꿔보았다.
- static_cast\ 연산은 버림을 수행하므로 유의한다. 아무튼 거의 가운데와 마찬가지인 것이다.
- 중간 인덱스의 값(pivot value)과 배열 마지막 값을 swap 후 quick sort 진행
- sort 마지막에 left terator와 end(pivot value)를 바꿔주고 pivot iterator를 Return
2. compare
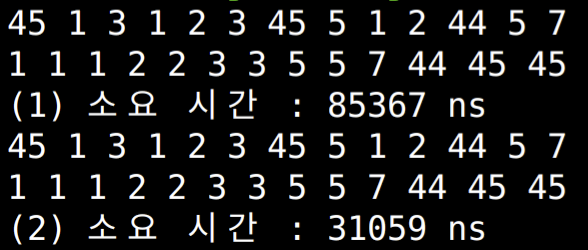
- (1)이 pivot을 first element로, (2)가 pivot을 middle element로 지정해봤을 때 속도를 측정해 봤다.
- 이 경우에는 pivot이 middle element일 때 더 빨랐다.
- 여러번 수행하더라도 더 빨랐다.
3. conclusion
- 퀵 정렬은 피벗을 어떻게 선택했는가에 따라 다르다.
- 최선의 경우가 중간 위치의 원소를 피벗으로 사용하는 것이다.
- 중간 위치를 피벗으로 하면 각 단계에서 동일한 크기의 부분 배열로 나눠진다.
- 중간 위치 값이 min 값 또는 max 값인 경우가 드물기 때문
- 재귀 트리 깊이가 정확하게 log(n)이 되기 때문이다.
- 중간 위치를 피벗으로 하면 각 단계에서 동일한 크기의 부분 배열로 나눠진다.
- 중간 위치 값이 아닌 피벗을 선택하면 분할된 크기가 불균형해져서 재귀 트리가 깊어질 수 있으므로 주의해야된다.
- 또한 정렬된 상태의 배열이면서, 맨 마지막 원소를 pivot으로 정했을 시 O(n^2)과 같은 Worst Time Complexity가 생길 수 있으므로 주의한다.
- 알아보니 퀵소트 방법이 정말 여러가지 였다.
Appendix

OnePunchLotto