분할 정복 이해하기 (divide-and-conquer)
- 주어진 문제의 규모가 너무 크다면 작은 부분 문제로 나눠 해결하는 방식
- 부분 문제로 나누는 작업을 반복해 해답을 찾고 다시 그 해답을 합쳐 처음 문제에 대한 해답을 유도한다.
- 분할 : 주어진 문제를 동일한 방식으로 해결할 수 있는 여러 부분문제로 나눈다.
- 정복 : 각 부분 문제에 대한 해답을 구한다.
- 결합 : 각 부분 문제의 해답을 결합해 전체 문제에 대한 해답을 구한다.
- 이진 검색은 원소를 찾았거나 range를 더 작은 부분으로 나눌 수 없을 때 검색을 종료했다. 분할 정복 알고리즘과는 조금 다른 면이 있는데, 검색 문제에서는 range에서 원소를 찾을 수 있으면 전체 시퀀스에서도 원소를 찾을 수 있다. 즉, 전체 일부에서 구한 해답이 전체에서 구한 해답과 같아 검색의 경우 결합 과정이 필요하진 않다.
- 분할 정복으로 해결할 수 있는 다수 계산 문제에서는 흔치 않은 경우다.
분할 정복을 이용한 정렬 알고리즘
- 정렬 알고리즘 구현 필요 요구 사항
- 모든 Data Type에 대해 동작 (Class, Struct 포함)
- 많은 양의 데이터 처리할 수 있어야 한다. 메인 메모리를 넘을 지라도 ..
- 점근적 시간 복잡도 측면 + 실제 동작 시 빠르게 동작해야한다.
- 현실적으로는 위에서 언급한 3가지를 만족하기는 어렵다. 특히 2, 3 번째 요구 사항을 동시에 만족하기는 어렵다.
Merge Sort
- 모든 데이터를 메인 메모리에 불러올 수 없는 경우에도 사용 가능한 정렬 알고리즘
- 작은 크기의 부분 집합으로 나눠 각각을 정렬하고, 정렬된 부분 집합을 오름차순 or 내림 차순으로 순서를 유지하며 합치는 방식이다.
- 각 부분 배열이 하나의 원소만 가질 때 까지 부분 배열로 나눈다. 그 이후 합치는 작업을 반복한다.

#include <iostream>
#include <vector>
template<typename T>
std::vector<T> merge(std::vector<T>& arr1, std::vector<T>& arr2)
{
std::vector<T> merged;
auto iter1 = arr1.begin();
auto iter2 = arr2.begin();
while (iter1 != arr1.end() && iter2 != arr2.end())
{
if (*iter1 < *iter2)
{
merged.emplace_back(*iter1);
iter1++;
}
else
{
merged.emplace_back(*iter2);
iter2++;
}
}
if (iter1 != arr1.end())
{
for (; iter1 != arr1.end(); iter1++)
merged.emplace_back(*iter1);
}
else
{
for (; iter2 != arr2.end(); iter2++)
merged.emplace_back(*iter2);
}
return merged;
}template<typename T>
std::vector<T> merge_sort(std::vector<T> arr)
{
if (arr.size() > 1)
{
auto mid = size_t(arr.size() / 2);
auto left_half = merge_sort<T>(std::vector<T>(arr.begin(), arr.begin() + mid));
auto right_half = merge_sort<T>(std::vector<T>(arr.begin() + mid, arr.end()));
return merge<T>(left_half, right_half);
}
return arr;
}int main()
{
std::vector<int> S {45, 1, 3, 1, ...}
auto sorted_S1 = merge_sort<int>(S1);
}Quick Sort
- 병합 정렬의 목적은 대용량 데이터 정렬이다.
- 퀵 정렬의 목표는 평균 실행 시간을 줄이는 것이다.
- 기본 아이디어는 병합 정렬과 같다.
- 퀵 정렬에서는 핵심 연산은 병합이 아니라 분할이다.
분할 연산 방법
- Input Array 주어지고 하나의 원소를 pivot(P)으로 선택
- Input Array -> Partial Array L, R로 나눈다.
- L : element <= P
- R : element > P
- L, P, R 순서로 Input Array를 재구성
- Input Array -> Partial Array L, R로 나눈다.
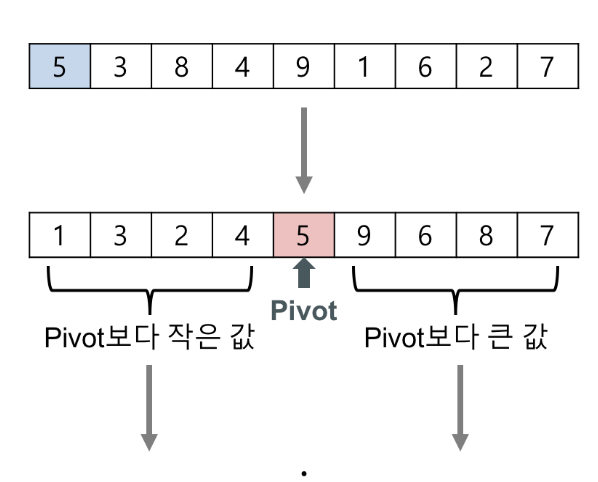
- 위의 분할 연산 수행 시 Pivot은 배열이 최종적으로 정렬되었을 때 P가 실제로 있어야 하는 위치로 이동하게 된다.
- 이런 특징은 퀵정렬의 핵심 아이디어 이다.
- Input Array A가 두 개 이상의 원소 -> A에 분할 연산 수행 (L, R 생성)
- 1단계의 Input으로 L을 사용
- 1단계의 Input으로 R을 사용
- 즉, 분할 연산에 의해 생성된 부분 배열에 재귀적으로 적용되는 것이다.
- 재귀적으로 반복할 수록 모든 원소가 차츰 오름차순 정렬된다.
- 재귀 트리, recursion tree는 빠르게 깊은 형태로 구성될 수 있다.

- 피벗은 임의의 원소를 피벗으로 선택해서 사용해도 무방하다.
#include <iostream>
#include <vector>
template <typename T>
auto partition(typename std::vector<T>::iterator begin,
typename std::vecotr<T>::iterator end)
{
auto pivot_val = *begin;
auto left_iter = begin + 1;
auto right_iter = end;
while (true)
{
// vector의 첫 원소부터 시작해 pivot보다 큰 원소를 찾는다.
while (*left_iter <= pivot_val && std::distance(left_iter, right_iter) > 0)
left_iter++;
// vector 마지막 우너소부터 시작해서 역순으로 pivot보다 작은 원소를 찾는다.
while (*right_iter > pivot_val && std::distance(left_iter, right_iter) > 0)
right_iter--;
if (left_iter == right_iter)
break; // 교환할 원소가 없음을 의미
else
// left_iter, right_iter가 가리키는 원소를 서로 교환
std::iter_swap(left_iter, right_iter);
}
if (pivot_val > *right_iter)
std::iter_swap(begin, right_iter);
return right_iter;
}- 분할 연산을 적용할 원소의 시작과 끝 iterator를 인자로 받아 분할 연산 시 발생하는 오른쪽 부분 배열의 시작 원소를 카리키는 반복자를 반환한다.
- 즉, 주어진 벡터가 분할되어 피벗보다 큰 원소는 오른쪽 부분에, 피벗보다 작거나 같은 원소는 왼쪽 부분에 나타나게된다.
- iter swap

template<typename T>
void quick_sort(typename std::vector<T>::iterator begin,
typename std::vector<T>::iterator last)
{
if (std::distance(begin, last) >= 1)
{
auto partition_iter = partition<T>(begin, last);
quick_sort<T>(begin, partition_iter - 1);
quick_sort<T>(partition_iter, last);
}
}- 분할 연산을 재귀적으로 수행한다.
int main()
{
std::vector<int> S1 {45, 1, 3, 1, ...}
quick_sort<int>(S1.begin(), S1.end() - 1);
return 0;
}- 퀵 정렬은 Pivot을 어떻게 선택했느냐에 따라 실행 시간이 달라진다.
- 최선의 경우 : 배열 중간 위치의 원소를 피벗으로 하는 경우
- 동일 크기의 부분 배열로 나눠지므로 재귀 트리의 깊이는 정확하게 log(n)이 된다.
- 배열 중간 값을 피벗으로 하지 않을 경우 분할된 크기가 서로 불균형하게 되어 재귀 트리가 깊어질 수 있다. (실행 시간 증가)
-
병합
- 최선 : O(nlogn)
- 평균 : O(nlogn)
- 최악 : O(nlong)
-
퀵
- 최선 : O(nlogn)
- 평균 : O(nlogn)
- 최악 : O(n^2)
선형 시간 선택
-
앞에서 살펴본 분할 정복 알고리즘은 각 단계에서 문제를 정확하게 두 개 부분문제로 나눴다.
-
그러나 각 단계에서 문제를 두 개 이상으로 분할하는 것이 더 유리한 경우도 있다. 이러한 문제를 다룬 것이 linear time selection이다.
-
Ex) 밴드퍼레이드
- 키가 들쑥 날쑥하지 않게 하기 위해 모든 학년에서 15 번째로 키가 작은 학생만 뽑아 참여
- 즉, 정렬되지 않은 원소 집합 S에서 i번 째로 작은 원소를 찾아야한다.
- 단순 방법은 O(n logn) 이지만, 분할 정복을 이용해 O(n)의 시간복잡도를 갖는 솔루션을 구해야한다.
-
- Input Vector V, i 번째로 작은 원소 searching
-
- V1, V2, V3, ... V(n/5) 로 분할
- 각 Vi는 5개 원소를 갖고 있고, 마지막 V(n/5)은 다섯개 이하의 원소를 가질 수 있다.
-
- 각각의 Vi를 정의
-
- 각각의 Vi에서 중앙값 m_i를 구하고, 이를 모아 집합 M을 생성
-
- 집합 M에서 중앙값 q를 찾는다.
-
- q를 Pivot으로 잡아 전체 Vector V를 L, R 두 vector로 나눈다.
-
- L은 q보다 작은 원소, R은 q보다 큰 원소만을 포함
- L에 k-1개 원소가 있다고 가정해보자
- i = k, q는 V의 i 번째 원소
- i < k, V = L로 설정 후 1단계로 이동
- i > k, V = R로 설정 후 1단계로 이동
#include <iostream>
#include <vector>
template<typename T>
auto find_median(typename std::vector<T>::iterator begin,
typename std::vector<T>::iterator last)
{
quick_sort<T>(begin, last); // 정렬
return begin + (std::distance(begin, last / 2);
}
template<typename T>
auto partition_using_given_pivot(typename std::vector<T>::iterator begin,
typename std::vector<T>::iterator end,
typename std::vector<T>::iterator pivot)
{
auto left_iter = begin;
auto right_iter = end;
while (true)
{
while (*left_iter < *pivot && left_iter != right_iter)
left_iter++;
while (*right_iter >= *pivot && left_iter != right_iter)
rigth_iter--;
if (left_iter == right_iter)
break;
else
std::iter_swap(left_iter, right_iter);
}
if (*pivot > *right_iter)
std::iter_swap(pivot, right_iter);
return right_iter;
}template<typename T>
typename std::vector<T>::iterator linear_time_select(
typename std::vector<T>::iterator begin,
typename std::vector<T>::iterator last,
size_t i)
{
auto size = std::distance(begin, last);
if (size > 0 && i < size)
{
auto num_Vi = (size + 4) / 5Map Reduce
- 대규모 데이터셋을 생성, 처리하기 위한 프로그래밍 모델 및 구현
- Key, Value 쌍을 처리하여 중간 단계 Key, Value를 생성하는 map 함수와 같은 중간 단계 Key에 해당하는 모든 중간 단계 Value를 병합하는 reduce 함수를 지정한다.
- 오픈 소스 구현 -> 하둡
- HDFS, Hadoop Disrtributed File System
- HDFS는 네트워크를 통해 연결된 여러 컴퓨터 클러스터로 확장할 수 있다.
map reduce 추상화
- map : 컨테이너 C를 입력으로 받아 모든 원소에 함수 f(x)를 적용하는 연산
- map(c, f(x))
- reduce : 컨테이너 C의 모든 원소 x에 함수 f(acc, x)를 적용해 하나의 값으로 축약하는 연산
- reduce(c, f(a, x) = a+x)
C++ 표준 라이브러리
std::accumulate()- 기본적으로 누적 연산 수행하므로 리듀스 연산의 제한된 형태
std::transform()- C++ 17에서 일반적이며 병렬 처리도 지원
#include <iostream>
#include <vector>
#include <algorithm>
#include <numeric>
#include <cmath>
void tranform_test(std::vector<int> S)
{
std::vector<int> Tr;
std::transform(S.begin(), S.end(), std::back_inserter(Tr),
[](int x) { return std::pow(x, 2.0); });
std::for_each(S.begin(), S.end(), [](int& x) { x = std::pow(x, 2.0); });
}std::transform()은 입력 벡터를 바꾸지 않고, 별도의 벡터를 만들어 반환- 첫 원소부터 마지막 원소까지 순서대로 적용되는 것이 보장되지 않는다.
- C++ 17 에서부터는 ExecutionPolicy를 첫 번째 인자로 받아 병렬 처리를 수행할 수 있다.
std::for_each()는 입력 벡터 자체를 변경
void reduce_test(std::vector<int> S)
{
auto ans = std::accumulate(S.begin(), S.end(), 0,
[](int acc, intx) { return acc + x});
}int main()
{
std::vector<int> S {1, 10, 4, 7, 3, ...};
transform_test(S);
reduce_test(S);
}맵리듀스 프레임워크를 이용한 부분 통합
- 원하는 연산을 map, reduce 두 단계로 표현할 수 있어야된다.
- map : 입력을 중간 단계 Key, Value로 표현
- reduce : 중간 단계 Key, Value를 원하는 방식으로 결합하여 최종 결과 생성

- 양의 정수 N이 있을 때, 1 ~ N 사이 소수를 찾아보자.
- Boost 라이브러리 사용
#include <iostream>
#include "mapreduce.hpp"
namespace prime_calculator {
bool const is_prime(long const number)
{
if (number > 2)
{
if (number % 2 == 0)
return false;
long const n = std::abs(number);
long const sqrt_number = static_cast<long>(std::sqrt(static_cast<double>(n));
for (long i = 3; i <= sqrt_number; i += 2)
{
if (n % i == 0)
return false;
}
}
else if (number == 0 || number == 1)
return false;
return true;
}template<typename MapTask>
class number_source : mapreduce::detail::noncopyable
{
public:
number_source(long first, long last, long step)
:sequence_(0), first_(first), last_(last, step_(step) {}
bool const setup_key(typename MapTask::key_type& key)
{
key = sequence_++;
return (key * step_ <= last_);
}
bool const get_data(typename MapTask::key_type const& key,
typename MapTask::value_type& value)
{
typename MapTask::value_type val;
val.first = first_ + (key * step_);
val.second = std::min(val.first + step_ - 1, last_);
std::swap(val, value);
return true;
}
private:
long sequence_;
long const step_;
long const last_;
long const first_;
};- 지정 범위 내 일정 간격 정수 생성하는 클래스
struct map_task : public mapreduce::map_task<long, std::pair<long, long>>
{
template<typename Runtime>
void operator()(Runtime& runtime, key_type const& /*key*/, value_type const& value) const
{
for (key_type loop = value.first; loop <= value.second; ++loop)
runtime.emit_intermediate(is_prime(loop), loop);
}
};- map 연산
struct reduce_task : public mapreduce::reduce_task<bool, long>
{
template<typename Runtime, typename It>
void operator()(Runtime& runtime, key_type const& key, It, it, It, ite) const
{
if (key)
std::for_each(it, ite, std::bind(&Runtime::emit, &runtime, true, std::placeholders::_1));
}
};
typedef mapreduce::job<prime_calculator::map_task,
prime_calculator::reduce_task,
mapreduce::null_combiner,
prime_calculator::number_source<prime_calculator::map_task>> job;
}- 하.. ㅅㅂ이게 머고
- 지금까지 분할 정복을 알고리즘 패러다임으로, 다음에는 소프트웨어를 확장시키는 도구로 사용했다.
- 분할정복과 같은 아록리즘 구현 시 데이터 타입에 종속적이지 않아야한다.
- template

OnePunchLotto