
데이터를 다루려면 우선 자료구조를 알아야 한다.
자료구조를 안 뒤 각 데이터에 맞는 자료구조를 사용하면 성능이 향상된다.
자료구조에는
배열 (Array)
연결 리스트 (Linked List)
스택 (Stack)
큐 (Queue)
해시 테이블 (Hash Table)
트리 (Tree)
그래프 (Graph)
힙 (Heap)
세트 (Set)
맵 (Map)
'등'이 있다.
그런데 고랭의 표준 라이브러리 중 컨테이너 패키지에는
힙, 리스트, 링만 구현이 되어 있다.
참고:
https://pkg.go.dev/std
그래서 책에서는 리스트, 링과
고랭 내장 타입 자료구조인 맵까지만 다룬다.
그 외의 자료구조는 스스로 만들 수도 있고
이미 만들어져 있는 패키지들을 사용할 수도 있다.
참고:
https://pkg.go.dev/github.com/golang-collections/go-datastructures
알고리즘 문제를 풀기 위해 기본적인 자료구조만 알아도 된다면
https://blog.logrocket.com/comprehensive-guide-data-structures-go/
여기를 참고하면 좋을 것 같다.
들어가기 전에 자료구조 설명을 (진짜) 간단히 하자면
배열: 연속된 메모리를 사용해 요소를 저장한다.
리스트: 비연속적인 메모리를 사용해 요소를 저장한다.
그래서 요소를 삽입하고 삭제하는 게 배열보다 빠르다.
큐: 빨대 같은 거다. 뒤에서 데이터를 넣으면 앞에서 데이터가 나온다.
스택: 맨 윗면만 열린 박스 같은 거다. 그래서 가장 마지막에 넣은 요소를 가장 먼저 뺄 수 있다.
링: 진짜 '링'이다. 리스트인데 처음과 끝이 연결되어 있다. 크기가 고정이다.
맵: {키:값} 이런 형태다.
[주의! 생각해 볼 것!!!]
책에서는 리스트와 링크드 리스트가 마치 같은 것처럼 이야기한다...
어... 사실 내가 알고 있는 내용을 바탕으로 해도 그 말이 옳은 것 같다.
왜냐면 내가 알기로
리스트: 각 요소가 위치한 곳의 메모리 주소가 다 다르다, 각 요소는 논리적으로 연속될 뿐이다.
링크드 리스트: 각 요소가 위치한 곳의 메모리 주소가 다 다르다, 각 요소의 테일이 다른 요소의 헤드를 가리킨다.
이러면 둘이 거의 같은 거잖아...?
근데 둘이 같으면 두 개의 이름을 쓸 이유가 없잖아?
그래서 검색을 해 보니
서로 다른 이야기를 하는 글들이 넘쳐난다.
다른 곳에서는
둘은 다른 개념이다.
리스트는 '메모리에서 연속적인 공간을 사용하고'(??????)
링크드 리스트는 '요소들이 메모리에서 모두 다른 주소를 차지한다'라고 말하고 있다.
While List or Dynamic Array stores items at continuous memory locations, Items in Linked Lists are scattered all over the heap memory. While List size is fixed, Linked Lists grows dynamically.
https://www.linkedin.com/pulse/c-data-structure-linked-list-muhammad-kashif#:~:text=Introduction,fixed%2C%20Linked%20Lists%20grows%20dynamically.
(list linked list difference 키워드로 검색)
이 이상 파면 지금 조금 골치 아파질 것 같아서 여기서 멈춘다.
누가 정확한 내용을 알면 댓글 좀 남겨 주세요...
그리고 새롭게 알게 된 점.
1) 스택, 큐, 트리 등이 배열과 리스트를 기반으로 만들어졌다(배열과 리스트를 기반으로 만들 수 있다).
2) 그렇다고 무조건 배열이나 리스트를 써야 하는 게 아니다. 동적 배열, 이중 연결 리스트, 환형 배열, 해시 테이블, 트리 기반 구조, 그래프 (등)로도 만들 수 있다.
배열의 요소는 서로 연속되어 있다.
그래서 예를 들어, 맨 앞에 값을 추가하면 그 뒤의 요소를 '전부' 한 칸 씩 뒤로 밀어야 한다.
그래서 효율적이지 않다.
그에 반해 (링크드)리스트는 포인터로 서로 연결된 형태라
맨 앞에 값을 추가하고 싶으면 원래 있던 맨 앞의 Prev 프로퍼티가 새 값의 Value를 가리키게 만들고
새 값의 Next 프로퍼티가 그 뒤 값의 Value를 가리키게 만들면 끝이다.
터커님은 이 부분을 언급하며 빅오 표기법도 말씀하시는데
이걸 간단히 설명하자면...
Big-O 표기법은
알고리즘에 걸리는 시간의 '최악(최대)'의 경우를 나타내는 표기법이다.
예를 들어 100장의 카드에서 내가 원하는 카드 한 장을 찾는데, 그게 맨 앞에 있으면 1트만에 알고리즘이 끝날 것이고, 그게 맨 뒤에 있으면 100트를 해야 할 것이다.
이를 기호로 표기한 것이 빅오 노테이션이라는 것.
빅오 노테이션의 기본적인 종류는 다음과 같다.
O(1): 상수 시간 - 입력 크기와 상관없이 항상 일정한 시간이 걸림.
O(log n): 로그 시간 - 입력 크기가 커질수록 시간이 조금씩 늘어남.
O(n): 선형 시간 - 입력 크기에 비례해서 시간이 늘어남.
O(n log n): 선형 로그 시간 - 데이터가 많아질수록 시간이 n보다 조금 더 빠르게 증가.
O(n^2): 제곱 시간 - 입력 크기의 제곱에 비례해서 시간이 늘어남. 입력이 두 배가 되면 시간은 네 배가 됨.
O(2^n): 지수 시간 - 입력 크기가 커질수록 시간이 매우 빠르게 증가.
O(n!): 팩토리얼 시간 - 매우 비효율적이며, 아주 작은 입력에 대해서만 사용 가능.
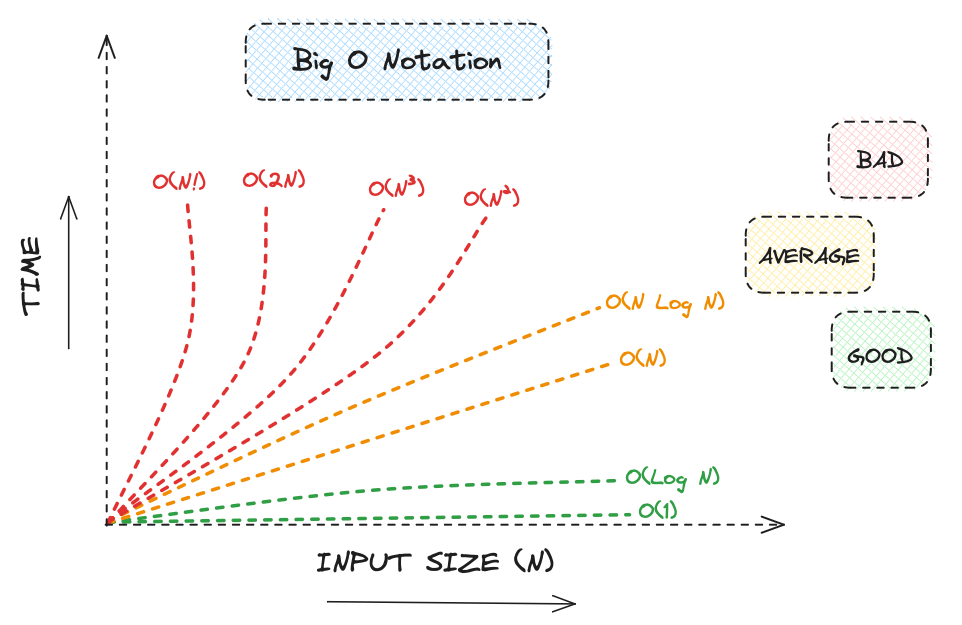
출처:
https://medium.com/@hlfdev/algorithms-discover-the-power-of-big-o-notation-17a367bd62a
그림에 오타가 있는데
O(n^2), O(2^n), 이게 맞다.
그렇다고 (링크드)리스트가 배열보다 항상 우월할까?
특정 요소에 접근하는 걸 생각해 보자.
배열일 땐 인덱스만 알면 바로 접근이 된다(주소를 바로 알 수 있다).
그래서 빅오가 O(1)이다.
(링크드)리스트는 어떨까?
내가 가려는 곳의 주소를 바로 알 길이 없다.
맨 처음 요소부터 포인터 타고 가야 한다.
그래서 O(N)만큼의 시간이 걸린다(물론 이건 최악의 경우다. 원래 빅오 표기법은 최악의 경우만 생각하니까.).
그래서 인덱스를 활용할 일이 많으면 배열을,
인덱스 사용할 일이 거의 없고 삽입과 삭제가 빈번하게 일어나면 (링크드)리스트를 써야 한다는 것이다.
그런데 또 모든 경우에 그런 게 아니다.(?!?!?!)
반전의 반전의 반전이 흔한 CS.
요소 수가 적으면 데이터 지역성이 배열이 훨씬 좋아서 배열 쓰는 게 더 나을 수 있다.
우리가 그걸 어떻게 알아?!?!?!
벤치마크 통해 성능 체크하면서 알아나가야 해요...
그 다음 책에서는 큐와 스택을 구현하는데 이 부분은 책을 보는 게 맞다고 생각해서 생략한다.
그 다음은 링.
자료구조에서는 링이라고 말하는 것이 고랭에서는 '링 버퍼'로 표현되고 있는 것 같다.
터커님이 말하는 내용도
링 버퍼, 혹은 순환 버퍼(Circular Buffer)는 고정된 크기를 가진 순환적인 저장 공간이다. 이 구조에서는 데이터가 버퍼의 끝에 도달하면 다시 버퍼의 시작으로 돌아가서 저장된다. 링 버퍼는 일정한 크기의 데이터를 순환적으로 저장할 때 유용하며, 오디오 처리, 스트림 데이터 처리 등에서 자주 사용된다.
이거 아닌가?
링은 링크드 리스트인데 첫 요소와 끝 요소가 연결된 거라고 머릿 속에서 그림을 그리면 쉽다.
중요한 건 지금 내가 어디에 있느냐는 것.
링은 저장할 개수가 고정되고, 오래된 요소는 지워도 되는 경우에 쓰기 적합하다.
like Ctrl+Z.
'링 버퍼'란 말이 진짜 잘 어울린다.
컨트롤+지를 통해 '버퍼'에 있는 데이터를 살리고 돌리고 할 수 있지 않은가!
이제 마지막, 대망의 맵이다.
어디에 가나(어떤 언어를 쓰나) 맵이 있다.
대부분의 현대 프로그래밍 언어는 맵 또는 유사한 형태의(키:값) 저장 구조를 기본 자료구조로 제공하다.
사용자가 구현할 필요 없이 그냥 갖다 쓰면 된다는 거다.
(참고)
파이썬에서는 딕셔너리.
자바에서는 맵 인터페이스와 이를 구현한 해시맵, 트리맵 등의 클래스.
C++에서는 맵과 unordered_map.
자바스크립트에서는 객체(오브젝트)를 맵으로 사용할 수 있고 ES6부터 별도 맵 객체도 제공됨.
고랭에서는 그냥 맵 타입이 내장되어 있음.
책에서는 맵 부분에서 키로 값을 더하고, 빼고, 그 요소가 유효한지(값이 있는지)를 확인한다.
이 부분은 책에서 다 확인이 가능하다.
터커님은 특정 자료구조를 사용하는 법 외에
퍼포먼스에 대한 내용을 자주 언급하고 있는데
이 뒤부터 맵이 다른 것에 비해 고르게 좋은 퍼포먼스를 낼 수 있는 이유를 설명한다.
맵은
데이터를 추가하고, 삭제하고, 읽을 때 모두
O(1)인데 어떻게 그럴 수 있는가?
이유를 알고 싶으면 '해시 함수'의 원리부터 알아야 한다.
터커님은 '맵을 다른 말로 해시맵 또는 해시테이블이라고 부를 만큼...'이라고 표현하지만
나는 이 셋이 다르다고 생각한다.
맵은 {키:값} 형태의 추상적 자료 구조!
해시맵은 맵을 '구현한 건데' 해시 함수를 사용해 키를 해시 코드로 변환하고, 이 해시 코드를 사용해 내부 배열에서 값의 위치를 저장한 거.
해시테이블은 맵을 '구현한 건데' 스레드 세이프를 위해 동기화가 내장된 거(해시맵에서는 동기화가 지원 안 됨).
(단일 스레드 환경에서는 해시맵 성능이 더 좋을 수 있음, 자바에서는 해시맵이 더 뒤에 나옴, 현대적인 자바 환경에서는 해시맵을 더 선호함.)
해시 함수는 간단하게 말하자면,
입력된 데이터를 '고정된 크기'의 '고유한 해시 값'으로 변환하는 함수다.
해시 함수는 제대로 얘기하자면 정말 분량도 길고 할 말도 많으니 여기서 다 할 수가 없다.
그래서 짧은 것을 양해 바란다.
그런데 해시맵 같은 거 만들면 '해시 충돌'이라는 문제가 생긴다.
이를 해결하는 방법 중 하나가 인덱스 위치마다 하나의 값이 아닌, 리스트를 저장하는 것인데...
package main
import (
"fmt"
"container/list"
)
type Entry struct {
Key string
Value int
}
type HashMap struct {
buckets []*list.List
size int
}
func NewHashMap(size int) *HashMap {
buckets := make([]*list.List, size)
for i := range buckets {
buckets[i] = list.New()
}
return &HashMap{buckets: buckets, size: size}
}
func (h *HashMap) Put(key string, value int) {
index := h.hash(key)
for e := h.buckets[index].Front(); e != nil; e = e.Next() {
if e.Value.(*Entry).Key == key {
e.Value.(*Entry).Value = value
return
}
}
h.buckets[index].PushBack(&Entry{Key: key, Value: value})
}
func (h *HashMap) Get(key string) (int, bool) {
index := h.hash(key)
for e := h.buckets[index].Front(); e != nil; e = e.Next() {
if e.Value.(*Entry).Key == key {
return e.Value.(*Entry).Value, true
}
}
return 0, false
}
func (h *HashMap) hash(key string) int {
hash := 0
for _, char := range key {
hash += int(char)
}
return hash % h.size
}
func main() {
hashMap := NewHashMap(10)
hashMap.Put("key1", 10)
value, exists := hashMap.Get("key1")
if exists {
fmt.Println("Value:", value)
}
}여기서 bucket이 그 리스트이니
참고하면 되겠다.
Tucker의 Go 언어 프로그래밍 - 자료구조편 끝!
