컴퓨터에서 문자 표현 코드 체계에는 앞서 소개한 아스키 코드, 유니코드 등이 있다.
💡 데이터를 저장하고 전송할 시 크기를 줄여 효율성을 높이기 위해 텍스트 압축 기술을 사용하는데 그 원리와 효과는 어떠할까?
1-0. 허프만 코딩 (Huffman coding)
- 출현 빈도가 높은 문자 → 비트 개수 적게
출현 빈도가 낮은 문자 → 비트 개수 많게 표현
=> 데이터를 표현하는 데 필요한 전체 비트 수를 줄일 수 있음 - 허프만 트리를 사용함
1-1. 허프만 코딩을 이용하여 텍스트 압축하기
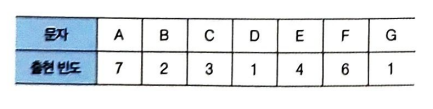
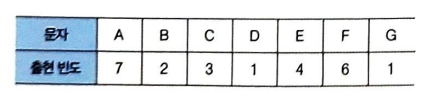
텍스트 'AAAAAAABBCCCDEEEEFFFFFFG'를 허프만 코딩으로 압축
① 각 문자별 출현 빈도 수 표시
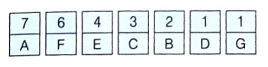
② 높은 빈도 수를 갖는 문자부터 내림차순으로 정렬
③ 빈도 수가 가장 낮은 문자 2개를 노드 1개로 묶고 두 문자의 빈도 수의 합을 노드에 표시, 노드 수 기준으로 재배열 (재배열 후 변화 없음)
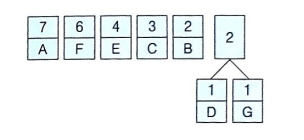
④ (③에서 묶은 노드 포함) 빈도 수가 가장 낮은 2개를 노드 1개로 묶고 빈도 수의 합을 노드에 표시, 재배열
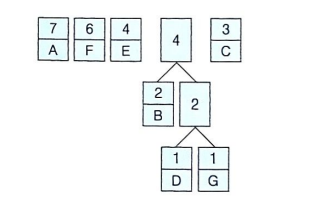
⑤ 같은 방식으로 1개의 노드에 모든 노드가 가지로 연결될 때까지 반복
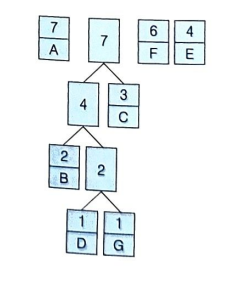
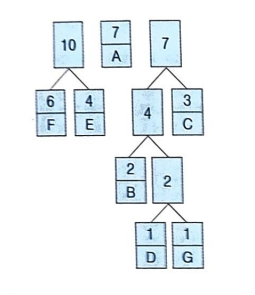
⑥ 더 이상 연결할 노드가 없음
→ 종료, 허프만 트리 완성
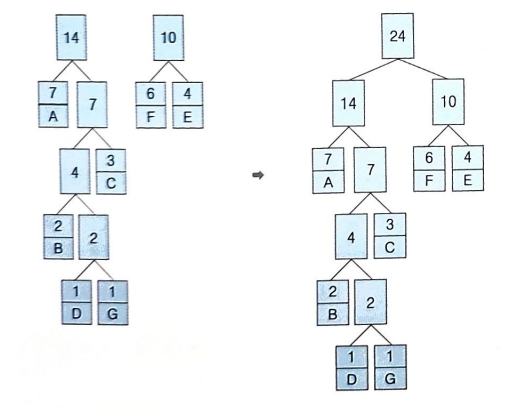
⑦ 각 가지의 왼쪽에 0, 오른쪽에 1 표시
→ 최상위 노드부터 가지를 따라 숫자 연결
→ 알파벳에 연결된 숫자 표시
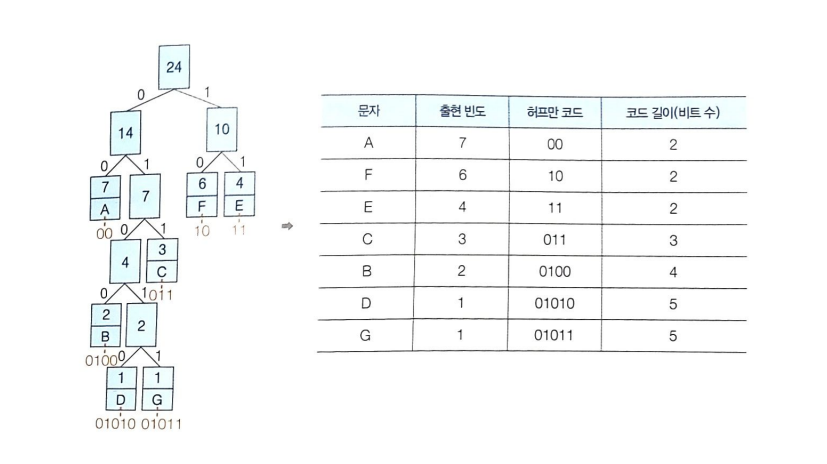
⑧ 허프만 코드로 나타낸 기존 텍스트
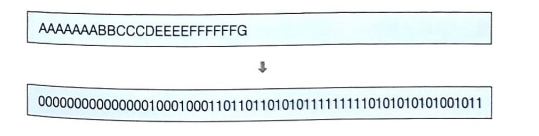
1-2. 텍스트 압축의 의의
허프만 코딩으로 나타낸 텍스트 전체 길이 61비트
기존 아스키 코드로 나타낸 텍스트 길이 (24x8비트=)192비트와 비교 :
121비트 적은 코드로 같은 텍스트 표현 가능
=> 효과적 정보 전송, 처리 가능
출처 : 소프트웨어 세상을 여는 컴퓨터과학, 김종훈, 2018

대학생