
1️⃣ GraphQL이란?
- Graph Query Language의 약자로, 이름에서 알 수 있듯이 SQL과 같은 query 언어.
- data를 가져오기 위해 타입 시스템을 사용하여 쿼리를 실행하는 서버사이드 런타임.
- 특정한 데이터베이스나 특정한 스토리지 엔진과 관계되어 있지 않으며 기존 코드와 데이터에 의해 대체 된다.
다음에서 GraphQL이 탄생하게 된 배경과 GraphQL이 해결하고 있는 문제들이 무엇인지 자세히 알아보자.
▷ 1-(1) Graphql의 탄생 - 왜 facebook은 Graphql을 만들었을까?
- facebook에서는 RESTful 서버와 FQL(facebook의 sql) 테이블을 사용하고 있었는데, 성능도 별로였고 앱에서도 충돌도 잦았다.
- 이러한 문제 상황 속에서, facebook 개발자들은 데이터 전송 방식을 개선해야 한다는 것을 깨닫고 데이터를 다른 시각으로 바라보기 시작했다.
- 이렇게 탄생한 것이 여러 다발의 데이터 전송을 graph로 묶어 request 수를 줄이고 효율성을 확보하여 문제를 해결하는 목적을 가진 GraphQL이다.
- 2015년 GraphQL의 초기 명세와 Graphql.js라는 자바스크립트 레퍼런스 서버를 공개 했다. 현재 facebook은 내부의 data fetch는 대부분 GrpahQL로 이루어지고 있으며, 오픈소스화 되어 많은 기업에서 사용하고 있다.
▷ 1-(2) GraphQL vs REST API
facebook에서 데이터 전송 방식 개선의 필요성을 느꼈던 구체적인 이유는 무엇이었을까? 다음에서 GraphQL과 REST API를 비교해보며 GraphQL이 해결하는 문제점들에 대해 알아보자.
📍 REST API vs GraphQL
REST API- HTTP 요청 방식 (GET, POST, PUT, DELET 등)을 사용하여 데이터를 요청하고 응답받는다.
- 상황에 따라 다른 method를 사용해야 하고, API 별로 각각의 end point를 갖는다.
GraphQL- 동일하게 HTTP 요청방식을 사용하지만, POST만 사용하고 단일 end point를 사용한다.
- 요청 시의 body의 schema에 맞춰 Query를 사용하여 요청하기 때문에 일관성 있는 통신이 가능하다.
📍over-fetching 문제
-
over-fetching: 내가 요청한 영역의 정보보다 많은 정보, 불필요한 정보까지 서버에서 받아오는 현상.💬 ex. 사용자 정보를 받아오는 API에서, 사용자의 ‘이름’을 받아오고 싶다고 가정해 보자.
🥺 REST API: 사용자 이름만 필요하지만, 성, 프로필, id 등 불필요한 데이터도 한꺼번에 받아야 한다.
➡️ overfetching 발생
//request GET /user/ //response { "data" : { "id" : ..., "profile" : ..., "name" : ..., "lastName" : ..., } }
😎 GrpahQL: 원하는 정보만 요청하고 받아오며 컨트롤 가능
➡️ overfetching 문제 해결
//request : 원하는 name 정보만 요청 { user { name } } //response : 요청했던 data만 반환 { "data" : { "name" : ..." } }
📍under-fetching 문제
-
under-fetching: 하나의 화면을 완성하기 위해 여러 번의 데이터 요청을 해야 하는 현상.💬 ex. 사용자의 프로필과 팔로우, 팔로잉 현황을 하나의 화면에 보여줘야 한다고 가정해 보자.
🥺 REST API: 사용자의 프로필 정보를 가져오는 API와, 사용자의 팔로우, 팔로잉 현황 정보를 가져오는 API를 별도로 호출한다.
➡️ 즉, 여러 개의 endpoint를 가지게 된다. === underfetching 발생
//request GET /user/ GET /follow/ //response1 -> user info { "data" : { "id" : ..., "profile" : ..., "name" : ..., } } //response2 -> follow info { "data" : { "following": ..., "follower": .... } }
😎 GrpahQL: 하나의 쿼리에 내가 정확하게 원하는 정보를 받아 올 수 있어, 여러 endpoint를 가지지 않고 여러 번의 API를 호출하는 일이 없어짐.
➡️ underfetching 문제 해결
//request : user 정보 + follow 정보 한 쿼리에 한 번에 요청 { user { id profile name } follow { following follower } } //response : 하나의 요청으로 여러 데이터 한 번에 반환 { "data" : { "user" : { "id" : ..., "profile": ..., "name" : ... }, { "follow" : { "following": ..., "follower" : ..., } }
▷ 1- (3) GraphQL의 장단점
위와 같은 현상들을 해결하는 GraphQL이 REST API와 비교하여 가지는 장점과, 그럼에도 불구하고 GraphQL이 가지는 단점을 다시 한 번 다음에서 정리해 보자.
📍 장점
- 1)
over-fetching과 under-fetching을 해결할 수 있다.- GrpahL 시스템의 목적은 클라이언트에서 필요한 필드를 포함하여 쿼리를 날려서 원하는 데이터들을 유연하게 응답받을 수 있도록 하는 것이다.
- GraphQL을 통해 API 요청을 유연하게 보낼 수 있게 됨으로써, HTTP 응답 사이즈를 최소화 하고 HTTP 요청 횟수를 줄이면서 REST API에서의 over-fetching, under-fetching 현상을 개선하고 클라이언트의 자유도를 높일 수 있다.
- 2)
endpoint와 요청 형식을 고민하지 않아도 된다.- REST API와 달리, 하나의 endpoint에 대해서 요청을 보내도록 되어 있기 때문에 API별로 endpoint를 지정하고 요청 객체 형태를 논의해야 하는 수고가 사라진다.
- 따라서 프론트엔드와 백엔드 사이의 의사소통 비용이 줄어든다.
- 3)
클라이언트 로직이 간결해진다.- GraphQL은 필요한 필드만 응답받기 때문에 클라이언트에서 응답 데이터의 타입을 정의하거나, 응답 데이터의 객체를 필터링하는 로직을 넣지 않고 받은 데이터를 그대로 사용할 수 있다.
- GraphQL은 필요한 필드만 응답받기 때문에 클라이언트에서 응답 데이터의 타입을 정의하거나, 응답 데이터의 객체를 필터링하는 로직을 넣지 않고 받은 데이터를 그대로 사용할 수 있다.
📍 단점
- 1)
HTTP 캐싱을 활용하기 어렵다.- HTTP 통신 시 헤더 설정을 통해 데이터를 캐싱할 수 있는데, REST API 시스템에서는 각각의 endpoint별로 얼마 동안 캐싱해둘지 간단하게 지정해둘 수 있지만, GraphQL은 단일 endpoint를 사용하기 때문에 HTTP 캐싱의 이점을 누리기 어렵다.
- 2)
에러 핸들링이 어렵다.- GraphQL에서는 여러 개의 데이터를 쿼리로 요청하는데, 성공한 쿼리는 data 필드에 담기고, 실패한 쿼리는 errors 필드에 배열로 담긴다.
- error 배열이 가지고 있는 객체들은 각 쿼리 필드에 대한 실패 사유와 실패한 위치 정보를 담고 있다.
- 클라이언트에서는 요청한 데이터 각각에 대한 에러 여부를 파악하고 대응해야 하므로 에러 핸들리이 매우 까다로워진다.
- 3)
요청이 무거워지고 설계하기 복잡하다.- 백엔드 개발자의 입장에서는, 클라이언트가 자유롭게 요청할 수 있는 쿼리에 대해 가능한 쿼리 조합을 어느 정도 예상하고 미리 대응해야 한다. 즉, API 설계 시 고민할 지점들이 매우 많아진다.
- 클라이언트에서 요청하는 데이터는 쿼리 때문에 무거워지고, 응답 데이터도 무거워질 가능성이 있다. 따라서 서버에 부담을 주지 않도록 쿼리의 최대 개수나 뎁스를 제한하는 것을 고려할 수 있다.
- 이러한 이유들로 반복적으로 적은 양의 데이터만 주고받는 가벼운 서비스에서 GraphQL을 도입하면 오버 엔지니어링을 유발할 수 있다. 따라서, REST API와 GraphQL에 따른 성능 차이가 미미하다면, 가벼운 프로젝트에서는 단순하고 빠르게 개발할 수 있는 REST API 방식을 채택하는게 합리적일 수 있다.
- 4)
마이크로서비스에서의 복잡성 증가.
- 마이크로서비스(이하 MSA)는 큰 서버를 기능별로 잘게 쪼개 작은 서비스로 모듈화하는 방식이다.
- 백엔드 서버가 MSA인 경우, 클라이언트에서 각 서비스에 API 요청을 각각 보내야 해서 또 다시 under-fetching이 발생할 수 있다.
➡️ 즉, under-fetching 문제를 해결하기 위해 GraphQL을 도입했지만 MSA 기반 서버에서는 다시 under-fetching 문제가 발생할 수 있어 결국 복잡성만 증가할 수 있다는 위험성이 있다.
✨ 출처 : 개발자에게 편리함을 주는 ‘GraphQL’ 도입 시 주의할 점은? | 요즘IT
▷ 1-(4) GraphQL, 어디에서 쓰고 있을까?
 ➡️ 코드너리 기준 51개의 국내 기업에서 사용 중이다.
➡️ 코드너리 기준 51개의 국내 기업에서 사용 중이다.
2️⃣ GraphL의 기본 구조와 용어
GraphQL의 개념에 대해 알아봤으니, 본격적으로 GraphQL을 사용하기 전 알아두면 좋은 핵심 용어들과, 전체적인 흐름을 다음에서 정리해보자.
▷ 2-(1) GraphQL 관련 용어 정리
스키마(Schema)- GraphQL은 데이터의 구조와 타입을 정의하는 스키마를 가진다.
- 스키마는 어떤 타입의 데이터를 쿼리할 수 있는지 각 데이터 타입이 어떤 필드를 가지고 있는지 정의한다.
쿼리(Query)- CRUD 중 Read에 해당하는 데이터를 단순히 받아오는 쿼리에 사용한다.
- 클라이언트는 원하는 데이터를 정확하게 명시하는 GraphQL 쿼리를 작성한다.
- 쿼리는 클라이언트가 서버에게 요청하는 데이터의 구조를 나타내며, JSON 형식으로 반환된다.
- 한 요청에 여러 개의 쿼리가 있을 경우 쿼리가 병렬적으로 실행된다.
뮤테이션 (mutation)- CRUD 중 Create, Update, Delete에 해당하는, 데이터 조작하는 쿼리에 사용한다.
- 변경 가능한 동작을 정의하고, 클라이언트가 서버에게 데이터 변경을 요청하는 방법을 제공한다.
- 한 요청에 여러 개의 뮤테이션이 있는 경우 쿼리가 순차적으로 실행된다.
리졸버(Resolver)- 서버 측에서는 각 필드의 데이터를 실제로 어떻게 가져올지를 정의하는 리졸버 함수를 작성한다.
- 리졸버 함수는 필드에 대한 실제 데이터 소스를 쿼리하며 그 결과를 반환한다.
실행 (Execution)- 클라이언트가 보낸 GraphQL 쿼리는 서버에 도착하면 실행된다.
- 서버는 쿼리를 분석하고 각 필드의 리졸버 함수를 호출하여 데이터를 수집한다.
변수 (Variables)- 쿼리에서 동적이 값 또는 파라미터를 사용하려면 변수를 정의하여 쿼리에 전달한다.
- 변수를 사용하면 동일 쿼리를 재사용하고, 보안과 성능을 향상시킬수 있다.
서브스크립션 (Subscription)- 서브스크립션이란 실시간 데이터 업데이트를 지원하는 메커니즘이다.
- 클라이언트는 특정 이벤트에 대한 서브스크립션을 등록하고 이벤트가 발생할 때마다 실시간으로 업데이트를 받을 수 있다.
▷ 2-(2) GraphQL의 전체적인 작동원리
위의 용어 정리 내용을 기반으로, GraphQL의 전체적인 작동원리를 정리해보면 위 그림과 같다.
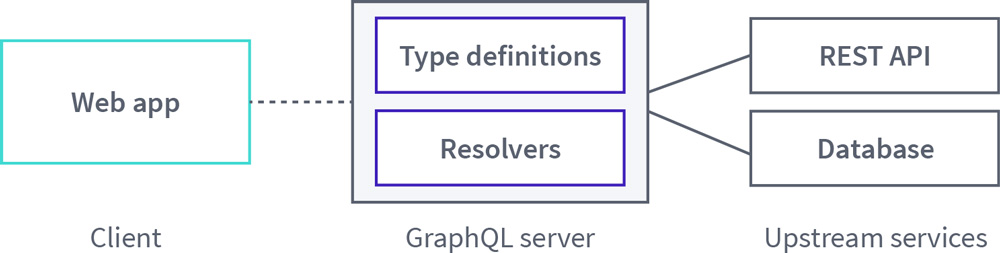
📍Client :
- Query로 조회 요청을 보내거나, Mutation으로 변경 요청 요청을 보낸다.
📍Server :
- Schema 정의를 통해 클라이언트에서 올 Query, Mutation 요청이 던질 질의의 구조를 미리 결정해둔다.
- Resolver 함수 정의를 통해 클라이언트 Query, Mutation 질의에 대한 응답 방식을 정의해두고, 질의 요청이 오면 정의 한 질의에 대한 응답을 반환한다.
다음 글에서 GraphQL의 가장 기본적인 문법인 Query와 Mutation을, 공식문서 기반으로 정리해볼 예정이다.
