다른 클러스터 제품도 마찬가지겠지만 데이터 분산이 되어 있다면 Query 조건에 대해 고민할 필요가 있다.
데이터 분산이란 말은 즉 네트워크 자원을 사용하게 된다는 것이고...
네트워크 자원을 최대한 사용하지 않아야 제대로 된 Query 응답 시간을 기대할 수 있다는 건 명확하다. 대부분의 지연은 네트워크에서 걸리기 마련.
1. 단건, 다건 수행 여부 고려
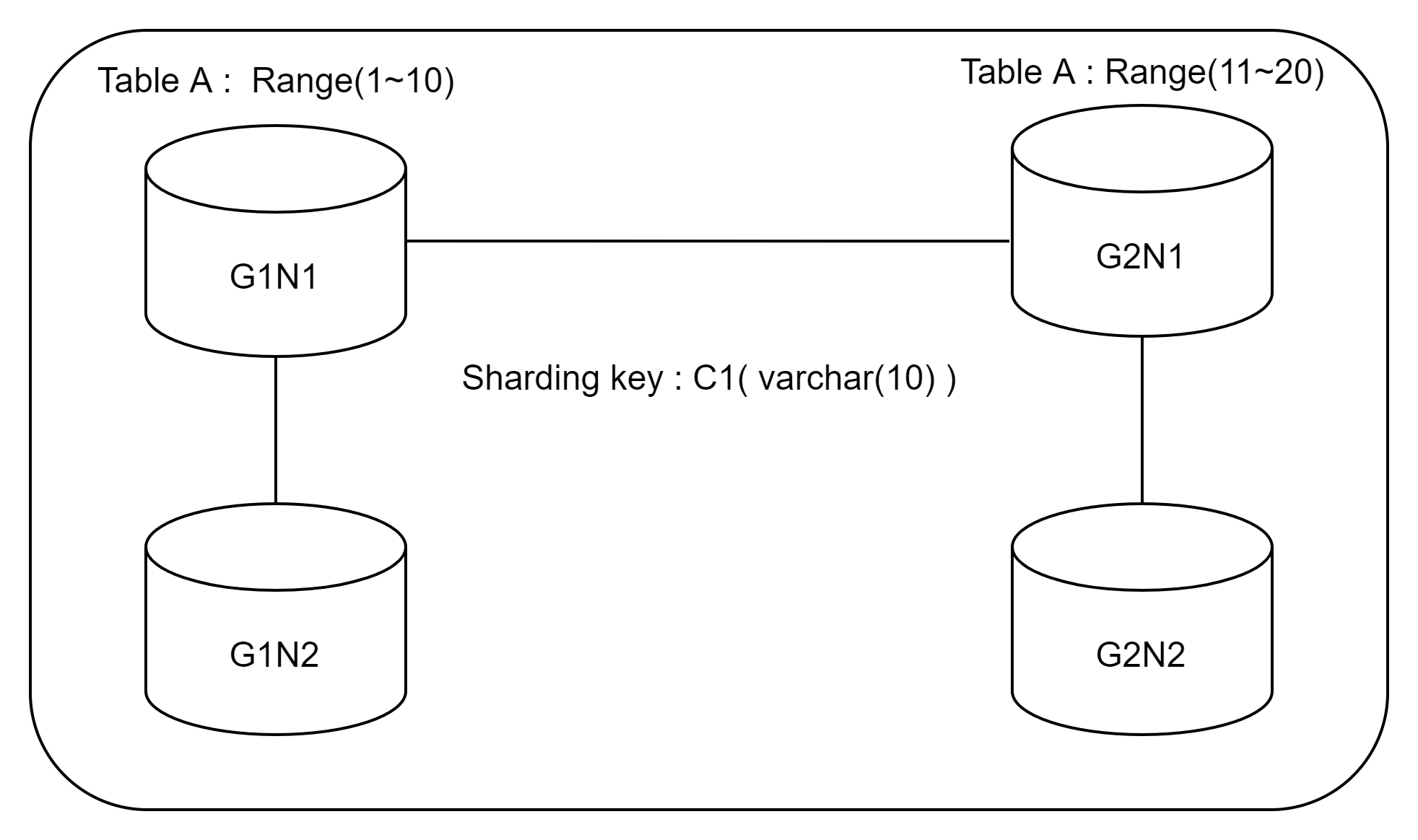
특정 테이블의 Sharding key가 C1이고, 이해를 위해 Range로 설정되어 있다고 가정해 보자.
C1의 값이 1~10인 데이터는 G1 그룹으로 갈 것이고, C1의 값이 11~20인 데이터는 G2 그룹으로 가게 될 것이다.
그렇다면 단일 행 조회 시 쿼리 조건은 다음과 같이 될 것이다.
SELECT * FROM T1 WHERE C1 = '1'
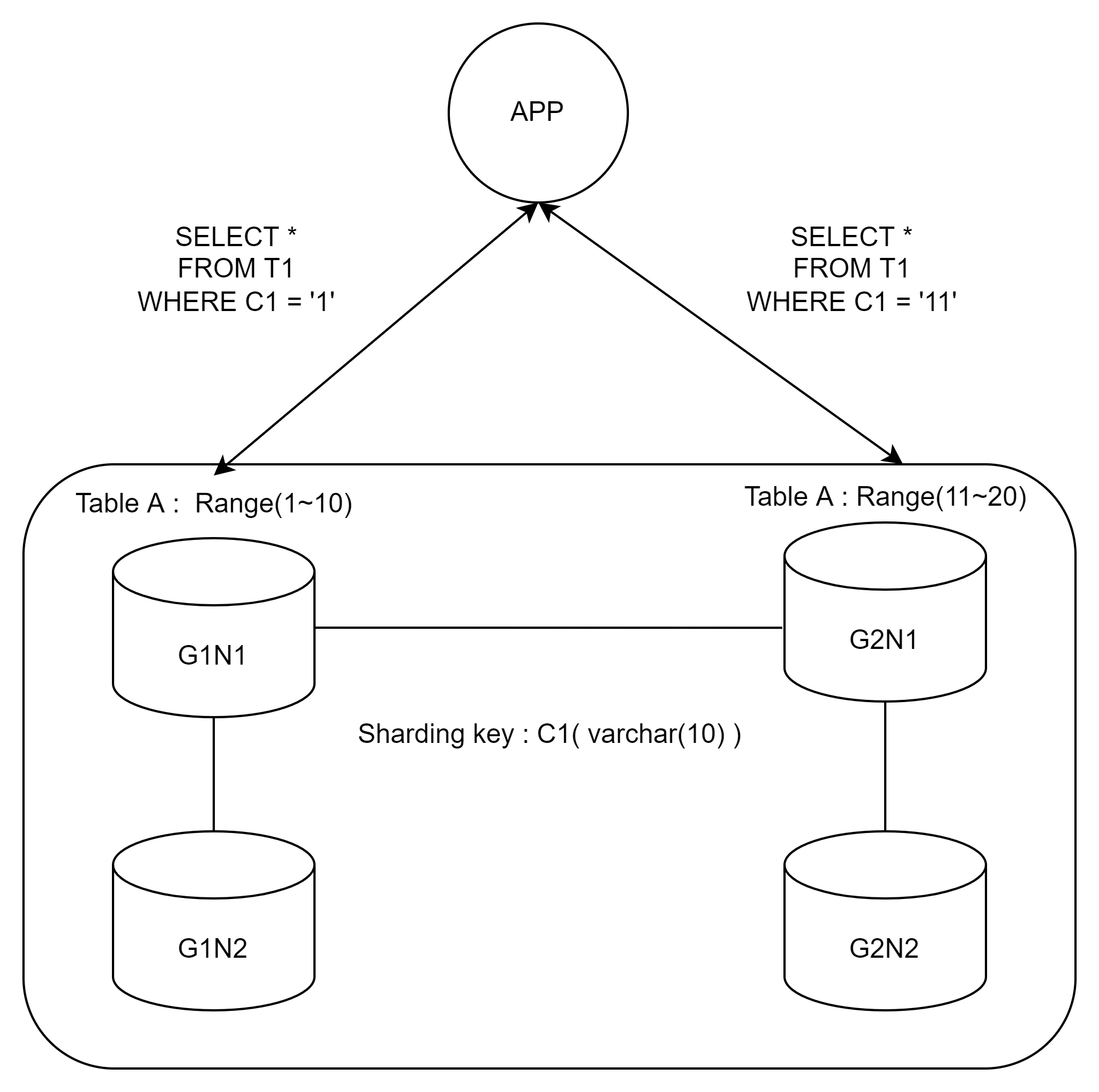 C1의 조건이 1이면 G1, 11이면 G2에 가서 단건을 긁어오게 된다.
C1의 조건이 1이면 G1, 11이면 G2에 가서 단건을 긁어오게 된다.
그런데 C1의 조건이 G1만 가져오는 케이스가 아니게 된다면?
1~10까지 한 그룹인데 내가 원하는 쿼리는 5보다 높은 값이라면 이런 식이 된다
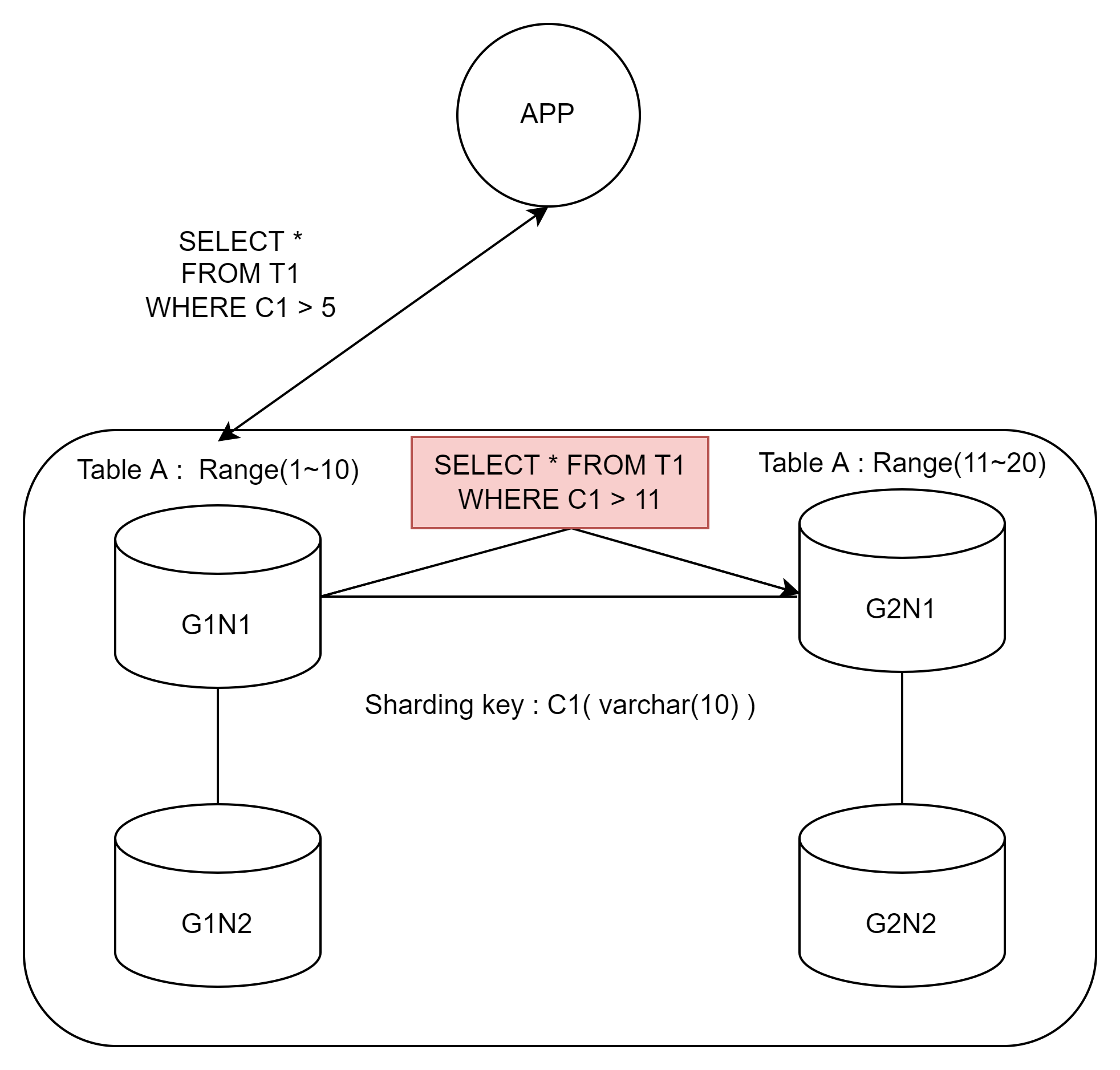 5~10까지의 값은 G1에서 가져오면 되지만, 11~의 값은 G1에서 가져올 수 없으므로 G2에 요청을 따로 하게 된다.
5~10까지의 값은 G1에서 가져오면 되지만, 11~의 값은 G1에서 가져올 수 없으므로 G2에 요청을 따로 하게 된다.
즉, 두 번의 네트워크 코스트가 발생한다.
1) G1에서 11보다 높은 쿼리 조건을 생성하여 전달
2) G2에서 G1으로 처리된 결과를 전달
쿼리를 생성하고, 쿼리를 산출하는 시간 또한 고려 사항이 될 수 있겠으나 사실 네트워크 코스트가 압도적으로 큰 경우가 많다. 애초에 쿼리 튜닝을 통해 달성할 수 있는 부분이고.
Sharding key를 설정할 때는 여러 가지 고려 사항이 필요한데 '단건 조회가 많을 것' 또한 고려의 대상이 되곤 한다. 물론 샤딩을 하더라도 단건 조회를 사용하지 않을 수 있다. 단순 데이터 분산을 위한 샤딩이고 네트워크 코스트가 미미한 수준으로 측정될 정도의 대규모 롱 쿼리라면 문제가 되진 않을 것이다.
실제로 그렇게 사용하는 경우도 있으며, 오히려 골디락스는 parallel select 를 지원하지 않으므로 그룹 별로 parallel 효과를 발휘할 수도 있어 장점이 될 수 있다.
2. 적절한 데이터 바인딩 & 조건 전략 수립
c1이 varchar(10)이고 sharding key로 설정되어 있는 t1 table을 하나 만들었다.
다음 두 쿼리를 비교해 보자.
where 조건에서 character로 검색
gSQL> select * From t1 where c1 = '1';
C1
--
1
1 row selected.
>>> start print plan
< Execution Plan >
==================================================================================================
| IDX | NODE DESCRIPTION | ROWS |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | 1 |
| 1 | QUERY BLOCK ("$QB_IDX_2") | 1 |
| 2 | INDEX ACCESS ("T1", "T1_PRIMARY_KEY_INDEX") | ( 1) 1 |
==================================================================================================
1 - TARGET : T1.C1
2 - HASH SHARD ( # 3 )
READ INDEX COLUMN : T1.C1
MIN RANGE : T1.C1 = '1'
MAX RANGE : T1.C1 = '1'
FETCH ONE ROWwhere 조건에서 숫자로 검색
gSQL> select * from t1 where c1 = 1;
C1
--
1
1 row selected.
>>> start print plan
< Execution Plan >
==================================================================================================
| IDX | NODE DESCRIPTION | ROWS |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | 1 |
| 1 | QUERY BLOCK ("$QB_IDX_2") | 1 |
| 2 | INDEX ACCESS ("T1", "T1_PRIMARY_KEY_INDEX") | ( 1) 1 |
==================================================================================================
1 - TARGET : T1.C1
2 - HASH SHARD ( # 3 )
READ INDEX COLUMN : T1.C1
LOGICAL KEY FILTER : T1.C1 = 1
<<< end print plan물론 해당 부분은 속도 측면에서 처음부터 튜닝되어야 하지만, sharding key로 설정되어 있을 경우에는 영향도가 매우 커지므로 특별히 주의해야 한다.
global connection을 사용 시 해당 테이블의 메타정보로 연결 분배를 하게 되는데, logical filter를 탈 만한 조건 발생 시 제대로 된 노드로 연결 분배를 해 줄 수 없게 된다.
결과는 remote query 발생일 것이며, 네트워크 비용으로 인해 서비스가 느려질 수 있다.
마찬가지로 sharding key 조건식에 변환 함수(to_char 등)가 들어갈 경우 동일한 상황이 발생할 수 있으니 주의를 요해야 한다.
sharding key는 partition 등과 다르게 데이터 분산을 위한 key란 것을 고려해 보면 옵티마이저가 정상적인 플랜을 생성할 수 있도록 조건 설정을 설계하여야 한다는 결론 또한 자연스레 나올 것이다.
때로는 어플리케이션 코드 레벨에서 숫자를 문자, 문자를 숫자로 바인딩하는 등의 실수나 의도적인 설계가 있을 수 있으니 체크해 봐야 할 부분이다.
