뭐 내부 구조도 잘 파악되지 않았지만 Replication을 어떻게 하나 비교 측면에서 매뉴얼 탐독.
참고 : https://www.mongodb.com/docs/manual/replication/
Replication in MongoDB
몽고디비의 Replication은 일반적인 A-S 구조와 비슷한 것으로 보인다.
A replica set is a group of mongod instances that maintain the same data set. A replica set contains several data bearing nodes and optionally one arbiter node. Of the data bearing nodes, one and only one member is deemed the primary node, while the other nodes are deemed secondary nodes.
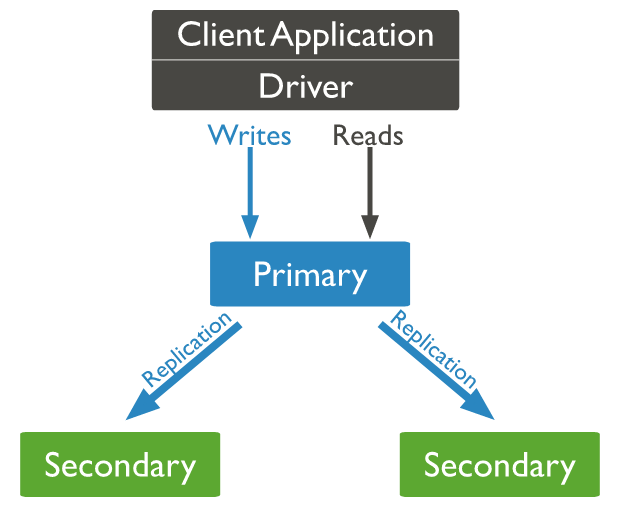
일반적으로 HA를 위한 리플리케이션이 많기도 하지만, 완전 Sync 구조로 가는 것은 아닌 게 확실하고, Async 구조로 Read capa를 올리는 등의 용도로 사용될 수 있을 것이다.
Write 노드는 정해져 있다는 것은 Tx 동기화가 이루어지지 않는다는 뜻으로 해석해도 될 듯.
The secondaries replicate the primary's oplog and apply the operations to their data sets such that the secondaries' data sets reflect the primary's data set. If the primary is unavailable, an eligible secondary will hold an election to elect itself the new primary.
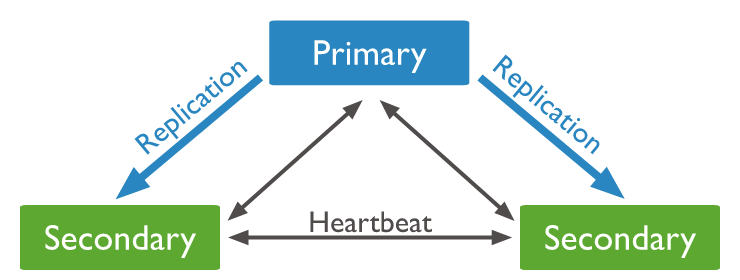
Heartbeat을 통해 서로의 state를 관리하며 Primary 침묵 시 Secondary로 Fail-over 함으로서 HA를 달성한다. 매우 흔한 구조라고 할 수 있겠다.
In some circumstances (such as you have a primary and a secondary but cost constraints prohibit adding another secondary), you may choose to add a mongod instance to a replica set as an arbiter
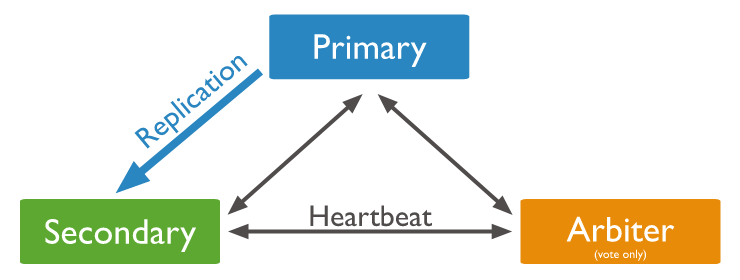
이것도 뭐 새로운 개념은 아니지만, 아비터 노드를 구성할 수도 있다.
secondary 노드를 추가하는데 있어 자원, 장비 등의 제약이 있으면 Arbiter 노드를 구성하여 primary Heartbeat 등으로 사용할 수 있을 듯.
일종의 locator 프로세스 용도로 두 노드만 구성했을 경우 생길 수 있는 split-brain 등의 상황을 방지할 수 있겠네.
Asynchronous Replication
Secondaries replicate the primary's oplog and apply the operations to their data sets asynchronously.
어느 정도 당연한 부분이지만 데이터를 복제하는 것이 아니고 op log를 복제한다고 한다.
log + Async라면 RDBMS의 CDC 개념이라 생각하면 정확할 것 같다.
Oplog : https://www.mongodb.com/docs/manual/core/replica-set-oplog/#std-label-slow-oplog-application
'Replica Set'이 붙는 걸로 봐서 Replication이 없을 땐 사용하지 않는 것으로 보인다.
- Replica Set이 없으면 OP log를 진짜 사용하지 않는것인가?
- 만약 없다면 Tx log에 해당하는 OP log 없이 운영이 가능한가?
- 그렇다면 리커버리 개념은??
Slow Operations
Starting in version 4.2 (also available starting in 4.0.6), secondary members of a replica set now log oplog entries that take longer than the slow operation threshold to apply
이건 튜닝을 목표로 하는 기능인가 싶기는 한데..
secondary node에서 slow operation threshold를 넘는 오퍼레이션을 로깅할 수 있다고 한다.
api 이름도 slowOpSampleRate인걸 보면 그런 기능인 듯.
- 샘플링해서 느린 이유를 찾는 것인가?
- secondary에서만 느린 오퍼레이션이 있다면, 어떠한 이유로 생길까?
- 해당 로그를 바탕으로 데이터 동기가 느려 생긴 conflict를 체크할 수 있지 않을까?
Replication Lag and Flow Control
Async 리플리케이션 개념에서 Lag이란 것은 필연적으로 발생할 부분일 수 밖에 없다.
이 랙이 특수한 이유로 감당하지 못할 정도로 늘어난다면 튜닝이 필요할 것이다.
이 부분은 몽고디비에서 Flow Control 이란 것으로 제어한다고 함.
flowControlTargetLagSeconds
해당 프로퍼티 설정으로 replSetGetStatus.optimes.lastCommittedOpTime(majority committed)을 기준으로 하는 최대 Lag Second를 설정한다고 한다. Flow Control이 켜져 있다면 해당 프로퍼티를 기준으로 Flow Control이 작동할 것이다
- Flow Control이 무엇인가?
- lag second...란 것은 시간 기준의 threshold인데 commit count등으로 제어할 방법은 없을까?
Lag 관련된 정보는 rs.printSecondaryReplicationInfo()를 통해 조회할 수 있다.
source: m1.example.net:27002
syncedTo: Mon Mar 01 2021 16:30:50 GMT-0800 (PST)
0 secs (0 hrs) behind the primary
source: m2.example.net:27003
syncedTo: Mon Mar 01 2021 16:30:50 GMT-0800 (PST)
0 secs (0 hrs) behind the primary해당 정보는 JSON으로 출력되지 않는 것은 특이한 점.
Flow Control 이란 것은 찾아보니 그렇게 복잡한 것은 아니고 특정 Lag 이상으로 쌓일 시(기준은 Lag Second) primary에서 lock이 잡히는 것이라고 한다.
참고 : Flow Control
MongoDB Replication 요약
- MongoDB Replication은 CDC 방식과 유사한 Async Replication이다.
- 데이터 Write가 가능한 노드는 Primary, Read만 가능한 노드는 Secondary
- 장비 자원 등의 문제로 Secondary와 비슷한 역할을 하지만 데이터는 없는 Arbiter 노드
- Async이므로 Gap이 발생하고 Replcation Lag이라고 한다. 해당 Lag은 시간값이며 Flow Control을 통해 락을 제어함으로서 Lag 임계점을 설정할 수 있다.
다음 포스팅
- Replication 구성
- Arbiter 구성, 구체적으로 어떤 역할인지
- OP log
정도로.
